Lavorando con i nomi delle persone e facendo ricerche sfocate su di essi, ciò che ha funzionato per me è stato creare una seconda tabella di parole. Creare anche una terza tabella che sia una tabella di intersezione per la relazione molti a molti tra la tabella contenente il testo e la tabella di parole. Quando una riga viene aggiunta alla tabella di testo, dividi il testo in parole e popola la tabella di intersezione in modo appropriato, aggiungendo nuove parole alla tabella di parole quando necessario. Una volta che questa struttura è a posto, puoi eseguire ricerche un po' più velocemente, perché devi solo eseguire la tua funzione damlev sulla tabella di parole univoche. Un semplice join ti dà il testo contenente le parole corrispondenti. 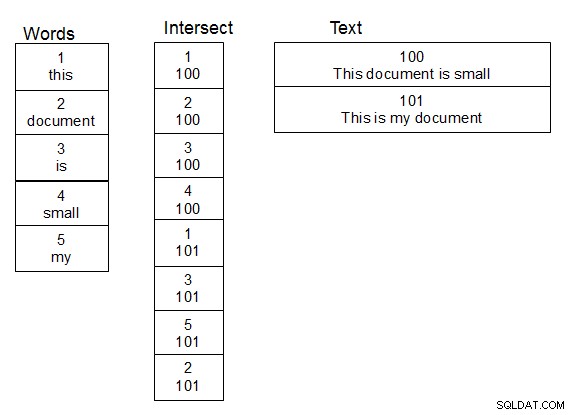
Una query per una corrispondenza di una singola parola sarebbe simile a questa:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
e due parole sembrerebbero così (in cima alla mia testa, quindi potrebbero non essere esattamente corrette):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
I vantaggi qui, al costo di un po' di spazio nel database, è che devi solo applicare la funzione damlev costosa in termini di tempo alle parole univoche, che probabilmente conterranno solo decine di migliaia indipendentemente dalle dimensioni della tua tabella di testo. Questo è importante, perché l'UDF damlev non utilizzerà gli indici:analizzerà l'intera tabella su cui è applicato per calcolare un valore per ogni riga. La scansione solo delle parole uniche dovrebbe essere molto più veloce. L'altro vantaggio è che il damlev viene applicato a livello di parola, che sembra essere quello che stai chiedendo. Un altro vantaggio è che puoi espandere la query per supportare la ricerca su più parole e classificare i risultati raggruppando le righe di intersezione corrispondenti su TextId e classificando il conteggio delle corrispondenze.