MySQL Replication è stata la soluzione più comune e ampiamente utilizzata per l'elevata disponibilità da grandi organizzazioni come Github, Twitter e Facebook. Sebbene sia facile da configurare, quando si utilizza questa soluzione per la manutenzione si devono affrontare sfide, inclusi aggiornamenti software, deriva dei dati o incoerenza dei dati tra i nodi di replica, modifiche alla topologia, failover e ripristino. Quando MySQL ha rilasciato la versione 5.6, ha apportato una serie di miglioramenti significativi, in particolare alla replica che include Global Transaction ID (GTID), checksum degli eventi, slave multi-thread e slave/master a prova di crash. La replica è migliorata ancora con MySQL 5.7 e MySQL 8.0.
La replica consente di replicare i dati da un server MySQL (primario/master) su uno o più server MySQL (replica/slave). MySQL Replication è molto facile da configurare e viene utilizzato per scalare i carichi di lavoro di lettura, fornire disponibilità elevata e ridondanza geografica e scaricare backup e processi di analisi.
Replica MySQL in natura
Diamo una rapida panoramica di come funziona la replica MySQL in natura. MySQL Replication è ampio e ci sono diversi modi per configurarlo e come può essere utilizzato. Per impostazione predefinita, utilizza la replica asincrona, che funziona quando la transazione viene completata nell'ambiente locale. Non vi è alcuna garanzia che qualsiasi evento raggiungerà mai uno schiavo. È una relazione master-slave debolmente accoppiata, dove:
-
La primaria non attende una replica.
-
Replica determina quanto leggere e da quale punto nel log binario.
-
La replica può essere arbitrariamente indietro rispetto al maestro nella lettura o nell'applicazione delle modifiche.
Se il primario si arresta in modo anomalo, le transazioni che ha commesso potrebbero non essere state trasmesse a nessuna replica. Di conseguenza, il failover dalla replica primaria alla replica più avanzata, in questo caso, può comportare un failover alla replica primaria desiderata che in realtà non ha transazioni relative al server precedente.
La replica asincrona fornisce una latenza di scrittura inferiore poiché una scrittura viene riconosciuta localmente da un master prima di essere scritta sugli slave. È ottimo per il ridimensionamento della lettura poiché l'aggiunta di più repliche non influisce sulla latenza della replica. Buoni casi d'uso per la replica asincrona includono la distribuzione di repliche di lettura per il ridimensionamento della lettura, la copia di backup in tempo reale per il ripristino di emergenza e l'analisi/reporting.
Replica semisincrona MySQL
MySQL supporta anche la replica semi-sincrona, in cui il master non conferma le transazioni al client fino a quando almeno uno slave non ha copiato la modifica nel suo registro di inoltro e lo ha scaricato su disco. Per abilitare la replica semisincrona, sono necessari passaggi aggiuntivi per l'installazione del plug-in che devono essere abilitati sui nodi MySQL master e slave designati.
Il semi-sincrono sembra essere una buona e pratica soluzione per molti casi in cui l'elevata disponibilità e l'assenza di perdita di dati sono importanti. Ma dovresti considerare che il semi-sincrono ha un impatto sulle prestazioni a causa del round trip aggiuntivo e non fornisce forti garanzie contro la perdita di dati. Quando un commit viene restituito correttamente, è noto che i dati esistono in almeno due posizioni (sul master e almeno in uno slave). Se il master esegue il commit ma si verifica un arresto anomalo mentre il master attende il riconoscimento da uno slave, è possibile che la transazione non abbia raggiunto nessuno slave. Questo non è un grosso problema in quanto il commit non verrà restituito all'applicazione in questo caso. È compito dell'applicazione riprovare la transazione in futuro. Ciò che è essenziale tenere a mente è che quando il master fallisce e uno schiavo è stato promosso, il vecchio master non può unirsi alla catena di replica. In alcune circostanze, ciò può portare a conflitti con i dati sugli slave, ad es. quando il master è andato in crash dopo che lo slave ha ricevuto l'evento del registro binario ma prima che il master ricevesse la conferma dallo slave). Pertanto, l'unico modo sicuro consiste nell'eliminare i dati sul vecchio master ed eseguirne il provisioning da zero utilizzando i dati del nuovo master promosso.
Utilizzo errato del formato di replica
Da MySQL 5.7.7, il formato di log binario predefinito o la variabile binlog_format utilizza ROW, che era STATEMENT prima della 5.7.7. I diversi formati di replica corrispondono al metodo utilizzato per registrare gli eventi di log binari dell'origine. La replica funziona perché gli eventi scritti nel log binario vengono letti dall'origine e quindi elaborati nella replica. Gli eventi vengono registrati all'interno del log binario in diversi formati di replica in base al tipo di evento. Non sapere con certezza cosa usare può essere un problema. MySQL ha tre formati di metodi di replica:STATEMENT, ROW e MIXED.
-
Il formato di replica basato su STATEMENT (SBR) è esattamente quello che è:un flusso di replica di ogni istruzione eseguita sul master che verrà riprodotto sul nodo slave. Per impostazione predefinita, la replica tradizionale (asincrona) di MySQL non esegue le transazioni replicate sugli slave in parallelo. Ciò significa che l'ordine delle istruzioni nel flusso di replica potrebbe non essere uguale al 100%. Inoltre, la riproduzione di un'istruzione può dare risultati diversi quando non viene eseguita contemporaneamente a quando viene eseguita dall'origine. Ciò porta a uno stato incoerente rispetto al primario e alle sue repliche. Questo non è stato un problema per molti anni, poiché non molti hanno eseguito MySQL con molti thread simultanei. Tuttavia, con le moderne architetture multi-CPU, questo è diventato molto probabile su un normale carico di lavoro quotidiano.
-
Il formato di replica ROW fornisce soluzioni che mancano all'SBR. Quando si utilizza il formato di registrazione della replica basata su riga (RBR), l'origine scrive gli eventi nel registro binario che indicano come vengono modificate le singole righe della tabella. La replica dall'origine alla replica funziona copiando gli eventi che rappresentano le modifiche alle righe della tabella nella replica. Ciò significa che è possibile generare più dati, influendo sullo spazio su disco nella replica e sul traffico di rete e sull'I/O del disco. Considera se un'istruzione modifica molte righe, ad esempio con un'istruzione UPDATE, RBR scrive più dati nel log binario anche per le istruzioni di cui viene eseguito il rollback. Anche l'esecuzione di snapshot point-in-time può richiedere più tempo. Potrebbero entrare in gioco problemi di concorrenza dati i tempi di blocco necessari per scrivere grandi quantità di dati nel log binario.
-
Allora c'è un metodo tra questi due; replica in modalità mista. Questo tipo di replica replica sempre le istruzioni, tranne quando la query contiene la funzione UUID(), trigger, stored procedure, UDF e poche altre eccezioni. La modalità mista non risolverà il problema della deriva dei dati e, insieme alla replica basata su istruzioni, dovrebbe essere evitata.
Pianificazione di avere una configurazione multi-master?
La replica circolare (nota anche come topologia ad anello) è una configurazione nota e comune per la replica di MySQL. Viene utilizzato per eseguire una configurazione multi-master (vedi immagine sotto) ed è spesso necessario se si dispone di un ambiente multi-datacenter. Poiché l'applicazione non può attendere che il master nell'altro data center riconosca le scritture, è preferibile un master locale. Normalmente l'offset di incremento automatico viene utilizzato per evitare conflitti di dati tra i master. Avere due master che si scrivono l'un l'altro in questo modo è una soluzione ampiamente accettata.
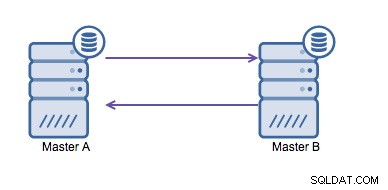
Tuttavia, se è necessario scrivere in più data center nello stesso database , ti ritroverai con più master che devono scrivere i propri dati tra loro. Prima di MySQL 5.7.6, non esisteva un metodo per eseguire un tipo di replica mesh, quindi l'alternativa sarebbe utilizzare invece una replica ad anello circolare.
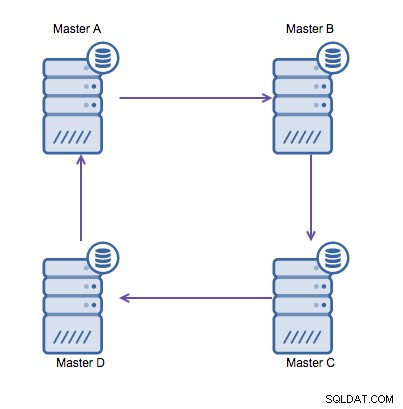
La replica ad anello in MySQL è problematica per i seguenti motivi:latenza, alta disponibilità e la deriva dei dati. Scrivere alcuni dati sul server A richiederebbe tre salti per finire sul server D (tramite il server B e C). Poiché la replica (tradizionale) di MySQL è a thread singolo, qualsiasi query di lunga durata nella replica potrebbe bloccare l'intero anello. Inoltre, se uno qualsiasi dei server si interrompesse, l'anello verrebbe interrotto e attualmente nessun software di failover può riparare le strutture dell'anello. Quindi può verificarsi una deriva dei dati quando i dati vengono scritti sul server A e modificati contemporaneamente sul server C o D.
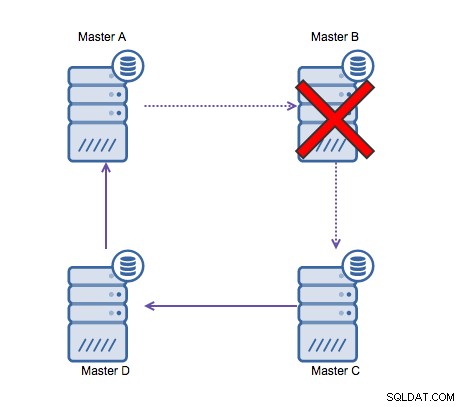
In generale, la replica circolare non è adatta a MySQL e dovrebbe essere evitato a tutti i costi. Poiché è stato progettato tenendo presente questo, Galera Cluster sarebbe una buona alternativa per le scritture multi-datacenter.
Blocco della replica con aggiornamenti di grandi dimensioni
Vari lavori batch di pulizia spesso svolgono varie attività, che vanno dalla pulizia dei vecchi dati al calcolo della media dei "Mi piace" recuperati da un'altra fonte. Ciò significa che un lavoro creerà molta attività del database a intervalli prestabiliti e, molto probabilmente, riscriverà molti dati nel database. Naturalmente, ciò significa che l'attività all'interno del flusso di replica aumenterà in egual modo.
La replica basata su istruzioni replicherà le query esatte utilizzate nei lavori batch, quindi se la query impiegasse mezz'ora per essere elaborata sul master, il thread slave verrebbe bloccato per almeno la stessa quantità di tempo. Ciò significa che nessun altro dato può essere replicato e i nodi slave inizieranno a rimanere indietro rispetto al master. Se questo supera la soglia del tuo strumento di failover o proxy, potrebbe eliminare questi nodi slave dai server disponibili nel cluster. Se utilizzi la replica basata su istruzioni, puoi evitarlo sgretolando i dati per il tuo lavoro in batch più piccoli.
Ora, potresti pensare che la replica basata su riga non sia influenzata da ciò, poiché replicherà le informazioni sulla riga anziché la query. Ciò è in parte vero poiché, per le modifiche DDL, la replica torna a un formato basato su istruzioni. Inoltre, un numero elevato di operazioni CRUD (Crea, Leggi, Aggiorna, Elimina) influirà sul flusso di replica. Nella maggior parte dei casi, si tratta ancora di un'operazione a thread singolo e quindi ogni transazione attenderà che la precedente venga riprodotta tramite replica. Ciò significa che se hai un'elevata concorrenza sul master, lo slave potrebbe bloccarsi per il sovraccarico delle transazioni durante la replica.
Per aggirare questo problema, sia MariaDB che MySQL offrono la replica parallela. L'implementazione può variare in base al fornitore e alla versione. MySQL 5.6 offre la replica parallela purché le query siano separate dallo schema. MariaDB 10.0 e MySQL 5.7 possono entrambi gestire la replica parallela tra schemi ma hanno altri limiti. L'esecuzione di query tramite thread slave paralleli può accelerare il flusso di replica se stai scrivendo pesantemente. In caso contrario, sarebbe meglio attenersi alla tradizionale replica a thread singolo.
Gestire la modifica dello schema o i DDL
Dalla versione 5.7, la gestione della modifica dello schema o della modifica del DDL (Data Definition Language) in MySQL è notevolmente migliorata. Fino a MySQL 8.0, gli algoritmi di modifica DDL supportati sono COPY e INPLACE.
-
COPIA:questo algoritmo crea una nuova tabella temporanea con lo schema alterato. Una volta migrati completamente i dati nella nuova tabella temporanea, scambia e rilascia la vecchia tabella.
-
INPLACE:questo algoritmo esegue operazioni sul posto sulla tabella originale ed evita la copia e la ricostruzione della tabella quando possibile.
-
INSTANT:questo algoritmo è stato introdotto da MySQL 8.0 ma presenta ancora dei limiti.
In MySQL 8.0 è stato introdotto l'algoritmo INSTANT, che apporta modifiche istantanee e sul posto alla tabella per l'aggiunta di colonne e consente DML simultaneo con una migliore reattività e disponibilità in ambienti di produzione impegnati. Questo aiuta a evitare enormi ritardi e stalli nella replica che di solito erano grossi problemi nella prospettiva dell'applicazione, causando il recupero di dati non aggiornati poiché le letture nello slave non sono state ancora aggiornate a causa del ritardo.
Sebbene si tratti di un miglioramento promettente, ci sono ancora dei limiti e talvolta non è possibile applicare quegli algoritmi INSTANT e INPLACE. Ad esempio, per gli algoritmi INSTANT e INPLACE, anche la modifica del tipo di dati di una colonna è una normale attività DBA, soprattutto nella prospettiva di sviluppo dell'applicazione a causa della modifica dei dati. Queste occasioni sono inevitabili; quindi, non puoi continuare con l'algoritmo COPY poiché questo blocca la tabella causando ritardi nello slave. Influisce anche sul server primario/master durante questa esecuzione poiché accumula transazioni in entrata che fanno riferimento anche alla tabella interessata. Non è possibile eseguire un ALTER diretto o una modifica dello schema su un server occupato poiché ciò accompagna i tempi di inattività o può danneggiare il database se perdi la pazienza, soprattutto se la tabella di destinazione è enorme.
È vero che eseguire modifiche allo schema su una configurazione di produzione in esecuzione è sempre un compito impegnativo. Una soluzione alternativa utilizzata di frequente consiste nell'applicare prima la modifica dello schema ai nodi slave. Funziona bene per la replica basata su istruzioni, ma può funzionare solo fino a un certo livello per la replica basata su riga. La replica basata su riga consente l'esistenza di colonne aggiuntive alla fine della tabella, quindi finché può scrivere le prime colonne, andrà bene. Innanzitutto, applica la modifica a tutti gli slave, quindi esegui il failover su uno degli slave, quindi applica la modifica al master e collegalo come slave. Se la modifica comporta l'inserimento di una colonna al centro o la rimozione di una colonna, funzionerà con la replica basata su riga.
Sono disponibili strumenti che possono eseguire modifiche allo schema online in modo più affidabile. Il Percona Online Schema Change (noto come pt-osc) e gh-ost di Schlomi Noach sono comunemente usati dai DBA. Questi strumenti gestiscono le modifiche allo schema in modo efficace raggruppando le righe interessate in blocchi e questi blocchi possono essere configurati di conseguenza a seconda di quanti si desidera raggruppare.
Se hai intenzione di saltare con pt-osc, questo strumento creerà una tabella ombra con la nuova struttura della tabella, inserirà nuovi dati tramite trigger e riempirà i dati in background. Una volta terminata la creazione della nuova tabella, scambierà semplicemente la vecchia con la nuova tabella all'interno di una transazione. Questo non funziona in tutti i casi, specialmente se la tua tabella esistente ha già dei trigger.
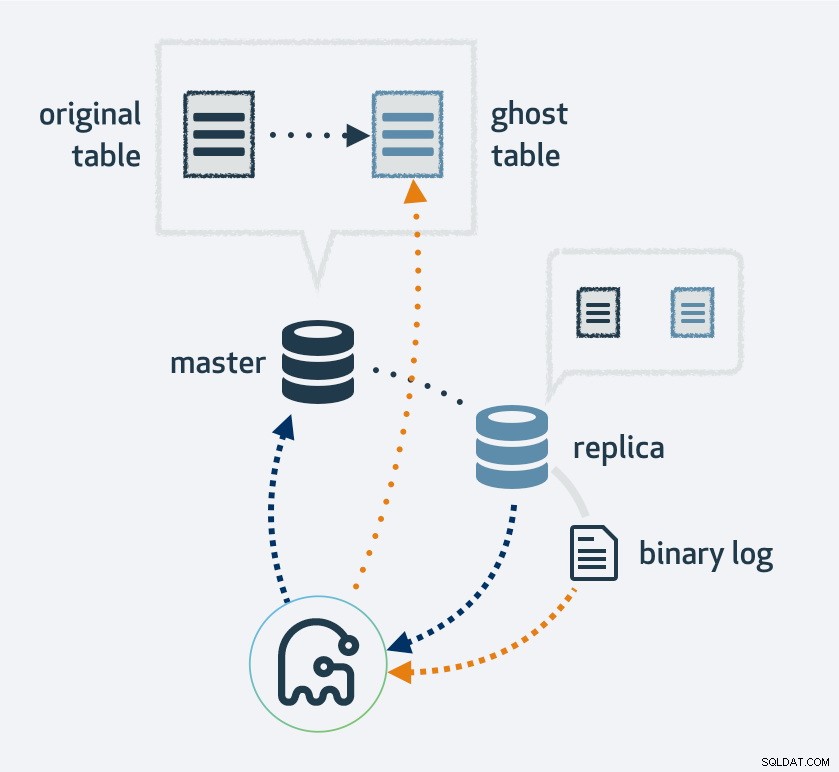
L'utilizzo di gh-ost creerà prima una copia del layout della tabella esistente, modificare la tabella nel nuovo layout, quindi collegare il processo come una replica MySQL. Utilizzerà il flusso di replica per trovare nuove righe che sono state inserite nella tabella originale e, allo stesso tempo, riempirà la tabella. Una volta terminato il riempimento, le tabelle originali e nuove cambieranno. Naturalmente, tutte le operazioni sulla nuova tabella finiranno nel flusso di replica; quindi, su ogni replica, la migrazione avviene simultaneamente.
Tabelle di memoria e replica
Mentre siamo in tema di DDL, un problema comune è la creazione di tabelle di memoria. Le tabelle di memoria sono tabelle non persistenti, la loro struttura della tabella rimane, ma perdono i dati dopo un riavvio di MySQL. Quando si crea una nuova tabella di memoria sia su un master che su uno slave, avranno una tabella vuota, che funzionerà perfettamente. Una volta riavviato uno dei due, la tabella verrà svuotata e si verificheranno errori di replica.
La replica basata su righe si interromperà una volta che i dati nel nodo slave restituiscono risultati diversi e la replica basata su istruzioni si interromperà quando tenterà di inserire dati già esistenti. Per le tabelle di memoria, questo è un frequente interruttore di replica. La soluzione è semplice:fai una nuova copia dei dati, cambia il motore in InnoDB e ora dovrebbe essere sicuro per la replica.
Impostazione di read_only={True|1}
Questo è, ovviamente, un possibile caso quando si utilizza una topologia ad anello e, se possibile, sconsigliamo l'uso di una topologia ad anello. Abbiamo descritto in precedenza che non avere gli stessi dati nei nodi slave può interrompere la replica. Spesso, ciò è causato da qualcosa (o qualcuno) che altera i dati sul nodo slave ma non sul nodo master. Una volta che i dati del nodo master vengono alterati, questi verranno replicati sullo slave dove non può applicare la modifica e questo provoca l'interruzione della replica. Ciò può anche portare al danneggiamento dei dati a livello di cluster, soprattutto se lo slave è stato promosso o ha eseguito il failover a causa di un arresto anomalo. Può essere un disastro.
Una facile prevenzione per questo è assicurarsi che read_only e super_read_only (solo su> 5.6) siano impostati su ON o 1. Potresti aver capito come queste due variabili differiscono e come influiscono se disabiliti o abiliti loro. Con super_read_only (da MySQL 5.7.8) disabilitato, l'utente root può impedire qualsiasi modifica nella destinazione o nella replica. Quindi, quando entrambi sono disabilitati, ciò impedirà a chiunque di apportare modifiche ai dati, ad eccezione della replica. La maggior parte dei gestori di failover, come ClusterControl, imposta automaticamente questo flag per impedire agli utenti di scrivere sul master utilizzato durante il failover. Alcuni di loro lo conservano anche dopo il failover.
Abilitazione GTID
Nella replica MySQL, è essenziale avviare lo slave dalla posizione corretta nei log binari. È possibile ottenere questa posizione quando si esegue un backup (xtrabackup e mysqldump lo supportano) o quando si è smesso di eseguire lo slave su un nodo di cui si sta eseguendo una copia. L'avvio della replica con il comando CHANGE MASTER TO sarebbe simile al seguente:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;L'avvio della replica nel punto sbagliato può avere conseguenze disastrose:i dati possono essere scritti due volte o non aggiornati. Ciò provoca la deriva dei dati tra il nodo master e quello slave.
Inoltre, trasferire un master su uno slave implica trovare la posizione corretta e cambiare il master nell'host appropriato. MySQL non conserva i log binari e le posizioni del suo master, ma crea invece i propri log e posizioni binari. Questo potrebbe diventare un problema serio per il riallineamento di un nodo slave al nuovo master. La posizione esatta del master durante il failover deve essere trovata sul nuovo master, quindi tutti gli slave possono essere riallineati.
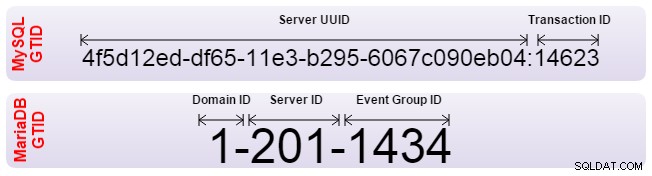
Sia Oracle MySQL che MariaDB hanno implementato il Global Transaction Identifier (GTID) per risolvere questo problema. I GTID consentono l'allineamento automatico degli slave e il server calcola da solo qual è la posizione corretta. Tuttavia, entrambi hanno implementato il GTID in modo diverso e sono quindi incompatibili. Se è necessario impostare la replica dall'uno all'altro, la replica deve essere impostata con il tradizionale posizionamento del log binario. Inoltre, il tuo software di failover dovrebbe essere informato del fatto che non utilizza GTID.
Slave a prova di crash
Crash safe significa che anche se uno slave MySQL/OS si arresta in modo anomalo, è possibile ripristinare lo slave e continuare la replica senza ripristinare i database MySQL sullo slave. Per far funzionare lo slave a prova di crash, devi usare solo il motore di archiviazione InnoDB e, in 5.6, devi impostare relay_log_info_repository=TABLE e relay_log_recovery=1.
Conclusione
La pratica rende davvero perfetti, ma senza un'adeguata formazione e conoscenza di queste tecniche vitali, potrebbe essere problematico o portare a un disastro. Queste pratiche sono comunemente seguite dagli esperti di MySQL e sono adattate dalle grandi industrie come parte del loro lavoro quotidiano di routine durante l'amministrazione della replica MySQL nei server di database di produzione.
Se desideri saperne di più sulla replica di MySQL, dai un'occhiata a questo tutorial sulla replica di MySQL per un'elevata disponibilità.
Per ulteriori aggiornamenti sulle soluzioni di gestione dei database e sulle best practice per i tuoi database open source, seguici su Twitter e LinkedIn e iscriviti alla nostra newsletter.