Quello che segue è un estratto dal nostro whitepaper "Come progettare ambienti di database open source altamente disponibili" che può essere scaricato gratuitamente.
Un paio di parole sull'"alta disponibilità"
Al giorno d'oggi l'elevata disponibilità è un must per qualsiasi distribuzione seria. Sono lontani i giorni in cui è possibile programmare un tempo di inattività del database per diverse ore per eseguire una manutenzione. Se i tuoi servizi non sono disponibili, stai perdendo clienti e denaro. Pertanto, rendere un ambiente di database altamente disponibile ha in genere una delle massime priorità.
Ciò rappresenta una sfida significativa per gli amministratori di database. Prima di tutto, come fai a sapere se il tuo ambiente è altamente disponibile o meno? Come lo misureresti? Quali sono i passaggi necessari per migliorare la disponibilità? Come progettare la tua configurazione per renderla altamente disponibile fin dall'inizio?
Ci sono molte molte soluzioni HA disponibili nell'ecosistema MySQL (e MariaDB), ma come facciamo a sapere di quali possiamo fidarci? Alcune soluzioni potrebbero funzionare in determinate condizioni specifiche, ma potrebbero causare più problemi se applicate al di fuori di queste condizioni. Anche una funzionalità di base come la replica di MySQL, che può essere configurata in molti modi, può causare danni significativi, ad esempio la replica circolare con più master scrivibili. Sebbene sia facile impostare una "configurazione multi-master" utilizzando la replica, può facilmente interrompersi e lasciarci con set di dati divergenti su server diversi. Per un database, che è spesso considerato l'unica fonte di verità, l'integrità dei dati compromessa può avere conseguenze catastrofiche.
Nei capitoli seguenti discuteremo i requisiti per l'elevata disponibilità nelle impostazioni del database
e come progettare il sistema da zero.
Misurare l'elevata disponibilità
Che cos'è l'alta disponibilità? Per poter decidere se un determinato ambiente è altamente disponibile o meno, è necessario disporre di alcune metriche per questo. Esistono numerosi modi per misurare l'elevata disponibilità, ci concentreremo su alcune delle cose più basilari.
Per prima cosa, però, pensiamo a cosa si tratta di tutta questa disponibilità elevata? Qual è il suo scopo? Si tratta di assicurarsi che l'ambiente serva al suo scopo. Lo scopo può essere definito in molti modi ma, in genere, riguarderà la fornitura di un servizio. Nel mondo dei database, in genere è in qualche modo correlato ai dati. Potrebbe fornire dati alla tua applicazione interna. Può essere per memorizzare dati e renderli interrogabili da processi analitici. Può essere per memorizzare alcuni dati per i tuoi utenti e fornirli quando richiesto su richiesta. Una volta che abbiamo chiarito lo scopo, possiamo stabilire i fattori di successo coinvolti. Questo ci aiuterà a definire cosa significa disponibilità elevata nel nostro caso specifico.
SLA
Accordo sul livello di servizio (SLA). È anche abbastanza comune definire SLA per i servizi interni. Che cos'è uno SLA? È una definizione del livello di servizio che intendi fornire ai tuoi clienti. Questo è per loro per capire meglio quale livello di stabilità pianifichi per un servizio che hanno acquistato o che stanno pianificando di acquistare. Esistono numerosi metodi che puoi sfruttare per preparare uno SLA, ma quelli tipici sono:
- Disponibilità del servizio (percentuale)
- Reattività del servizio - latenza (media, max, 95 percentile, 99 percentile)
- Perdita di pacchetti sulla rete (percentuale)
- Produttività (media, minima, 95 percentile, 99 percentile)
Tuttavia, può diventare più complesso di così. In un ambiente multiutente suddiviso in partizioni, puoi definire, ad esempio, il tuo SLA come:“Il servizio sarà disponibile il 99,99% delle volte, i tempi di inattività vengono dichiarati quando più del 2% degli utenti è interessato. Nessun incidente può richiedere più di 15 minuti per essere risolto”. Tale SLA può anche essere esteso per incorporare il tempo di risposta alle query:"il tempo di inattività viene chiamato se il 99 percentile di latenza per le query supera i 200 millisecondi".
Nove
La disponibilità è in genere misurata in "nove", esaminiamo cosa garantisce esattamente un determinato importo di "nove". La tabella seguente è tratta da Wikipedia:
| % di disponibilità | Tempo di fermo all'anno | Tempo di inattività al mese | Tempo di inattività settimanale | Tempo di inattività al giorno |
|---|---|---|---|---|
| 90% ("uno nove") | 36,5 giorni | 72 ore | 16,8 ore | 2,4 ore |
| 95% ("uno e mezzo nove") | 18,25 giorni | 36 ore | 8,4 ore | 1,2 ore |
| 97% | 10,96 giorni | 21,6 ore | 5,04 ore | 43,2 minuti |
| 98% | 7,30 giorni | 14,4 ore | 3,36 ore | 28,8 minuti |
| 99% ("due nove") | 3,65 giorni | 7:20 ore | 1,68 ore | 14,4 minuti |
| 99,5% ("due nove e mezzo") | 1,83 giorni | 3,60 ore | 50,4 minuti | 7,2 minuti |
| 99,8% | 17:52 ore | 86,23 minuti | 20,16 minuti | 2,88 minuti |
| 99,9% ("tre nove") | 8,76 ore | 43,8 minuti | 10,1 minuti | 1,44 minuti |
| 99,95% ("tre nove e mezzo") | 4,38 ore | 21,56 minuti | 5,04 minuti | 43,2 s |
| 99,99% ("quattro nove") | 52,56 minuti | 4,38 minuti | 1,01 min | 8,64 s |
| 99,995% ("quattro nove e mezzo") | 26,28 minuti | 2,16 minuti | 30,24 s | 4,32 s |
| 99,999% ("cinque nove") | 5,26 minuti | 25,9 s | 6.05 s | 864,3 ms |
| 99,9999% ("sei nove") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999% ("sette nove") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999% ("otto nove") | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999% ("nove nove") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Come possiamo vedere, si intensifica rapidamente. Cinque nove (disponibilità del 99.999%) equivalgono a 5,26 minuti di inattività nel corso di un anno. La disponibilità può anche essere calcolata in diversi intervalli più piccoli:al mese, alla settimana, al giorno. Tieni presente questi numeri, poiché saranno utili quando inizieremo a discutere i costi associati al mantenimento di diversi livelli di disponibilità.
Misurare la disponibilità
Per capire se c'è un periodo di inattività o meno, bisogna avere una visione dell'ambiente. Devi tenere traccia delle metriche che definiscono la disponibilità dei tuoi sistemi. È importante tenere presente che dovresti misurarlo dal punto di vista del cliente, prendendo in considerazione il quadro più ampio in esame. Non importa se i tuoi database sono attivi se, diciamo, a causa di un problema di rete, nessuna applicazione non riesce a raggiungerli. Ogni singolo elemento costitutivo della tua configurazione ha il suo impatto sulla disponibilità.
Uno dei buoni posti in cui cercare i dati sulla disponibilità sono i log del server web. Tutte le richieste che sono finite con errori significano che è successo qualcosa. Potrebbe essere l'errore HTTP 500 restituito dall'applicazione, perché la connessione al database non è riuscita. Potrebbero essere errori programmatici che puntano ad alcuni problemi del database e che sono finiti nel registro degli errori di Apache. Puoi anche utilizzare una metrica semplice come tempo di attività dei server di database, anche se, con SLA più complessi potrebbe essere difficile determinare in che modo l'indisponibilità di un database abbia influito sulla tua base di utenti. Indipendentemente da quello che fai, dovresti utilizzare più di una metrica:questa è necessaria per acquisire problemi che potrebbero essersi verificati su diversi livelli del tuo ambiente.
Numero magico:"Tre"
Anche se l'alta disponibilità riguarda anche la ridondanza, in caso di cluster di database, tre è un numero magico. Non è sufficiente avere due nodi per la ridondanza:tale configurazione non fornisce alcuna disponibilità elevata incorporata. Certo, potrebbe essere meglio di un solo nodo, ma è necessario l'intervento umano per ripristinare i servizi. Vediamo perché è così.
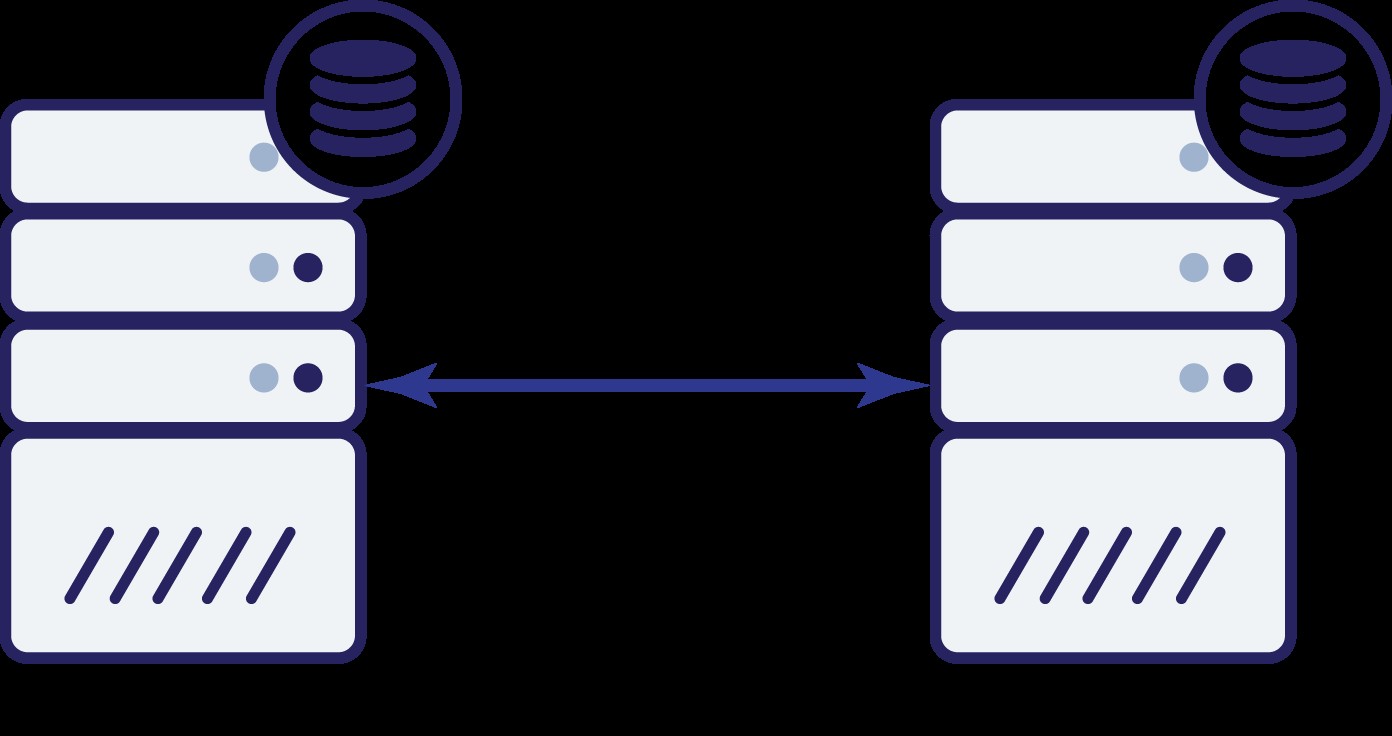
Supponiamo di avere due nodi, A e B. C'è un collegamento di rete tra di loro. Assumiamo che sia A che B servano scritture e che l'applicazione scelga casualmente dove connettersi (il che significa che parte dell'applicazione si connetterà al nodo A e l'altra parte si connetterà al nodo B). Ora, immaginiamo di avere un problema di rete che si traduce in una perdita di connettività di rete tra A e B.
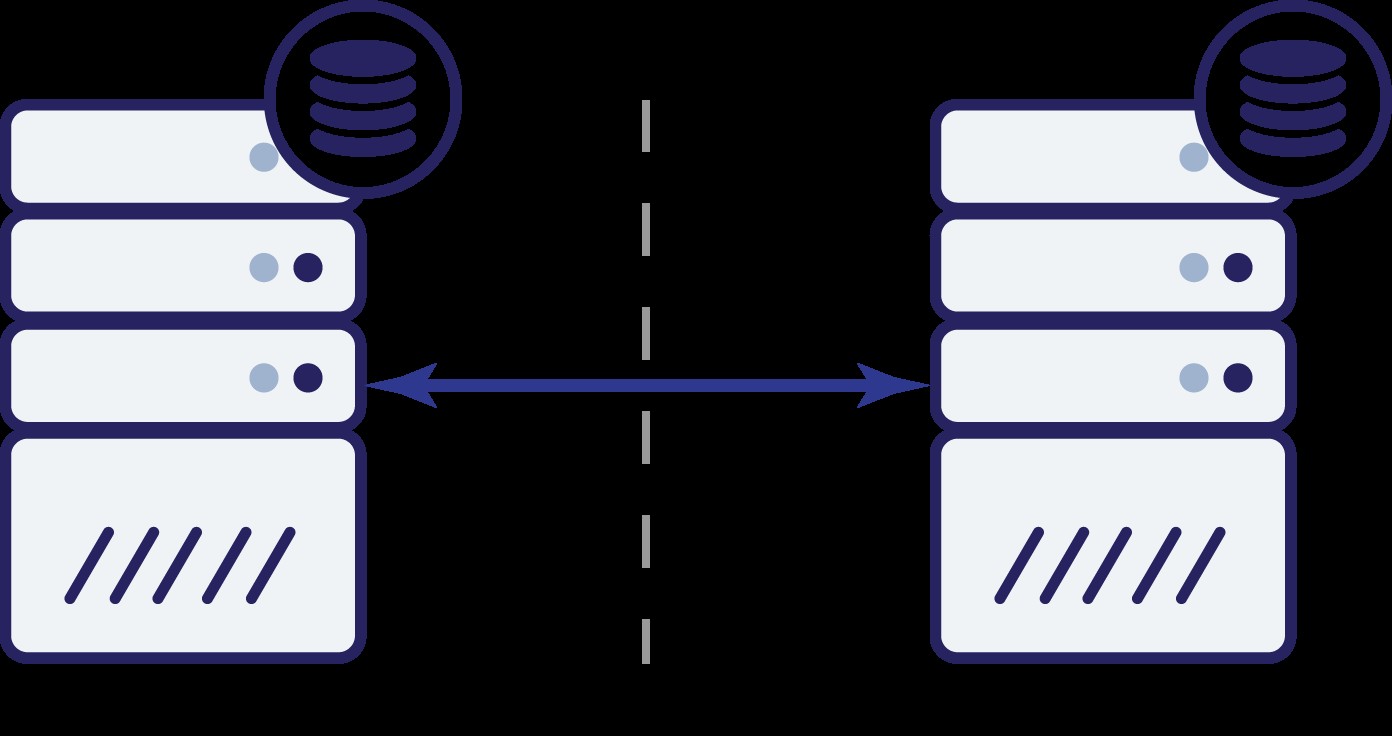
E adesso? Né A né B possono conoscere lo stato dell'altro nodo. Ci sono due azioni che possono essere intraprese da entrambi i nodi:
- Possono continuare ad accettare traffico
- Possono cessare di operare e rifiutarsi di servire qualsiasi traffico
Pensiamo alla prima opzione. Finché l'altro nodo è effettivamente inattivo, questa è l'azione preferita da intraprendere:vogliamo che il nostro database continui a servire il traffico. Dopotutto, questa è l'idea principale alla base dell'elevata disponibilità. Cosa accadrebbe, tuttavia, se entrambi i nodi continuassero ad accettare traffico mentre sono disconnessi l'uno dall'altro? Verranno aggiunti nuovi dati su entrambi i lati e i set di dati non saranno sincronizzati. Quando il problema di rete sarà risolto, sarà un compito arduo unire questi due set di dati. Pertanto, non è accettabile mantenere entrambi i nodi attivi e in esecuzione. Il problema è:come può il nodo A dire se il nodo B è vivo o meno (e viceversa)? La risposta è:non può. Se tutta la connettività è inattiva, non c'è modo di distinguere un nodo guasto da una rete guasta. Di conseguenza, l'unica azione sicura è che entrambi i nodi interrompano tutte le operazioni e si rifiutino di
servire il traffico.
Pensiamo ora a come un terzo nodo può aiutarci in una situazione del genere.
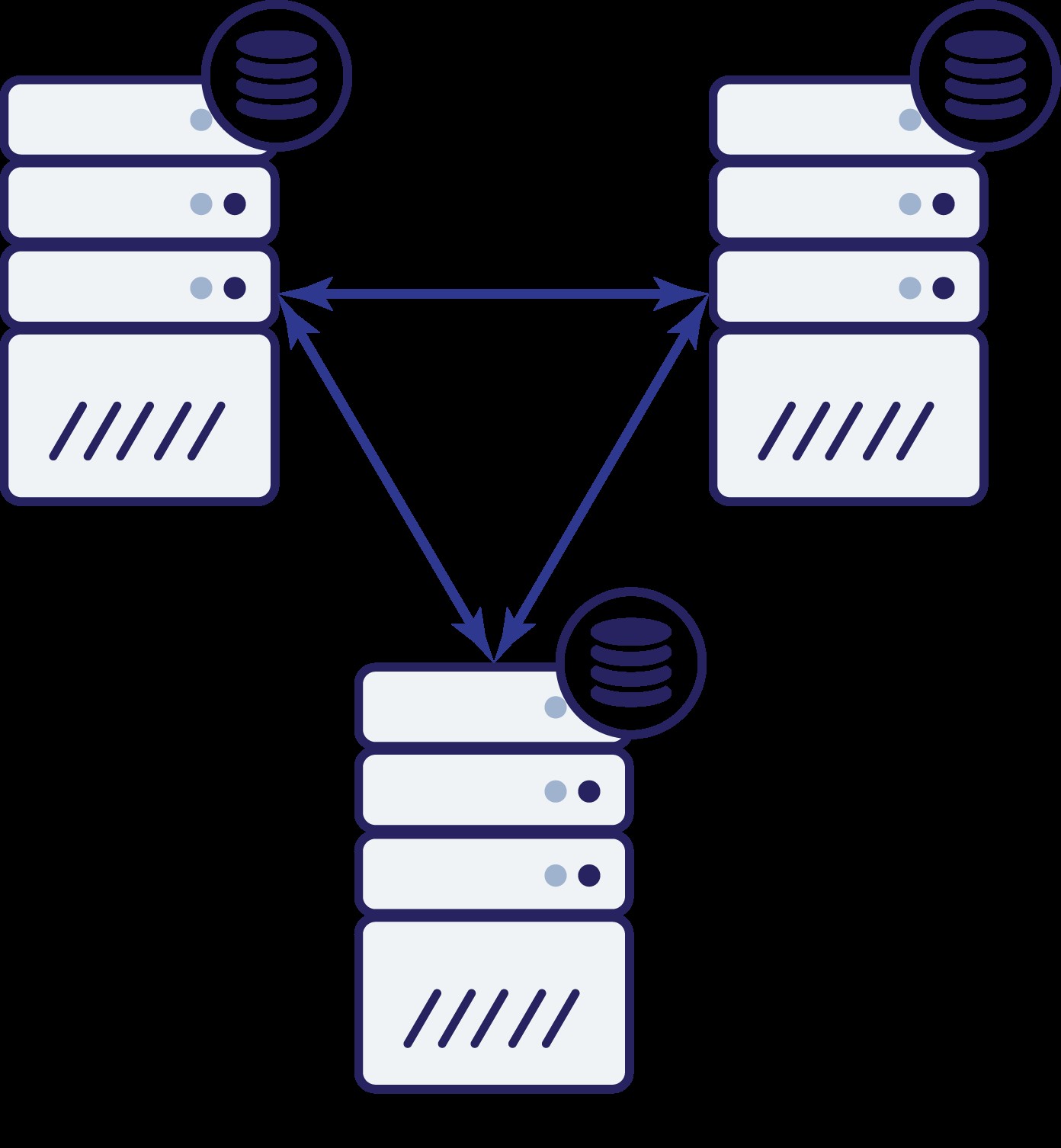
Quindi ora abbiamo tre nodi:A, B e C. Tutti sono interconnessi, tutti gestiscono letture e scritture.
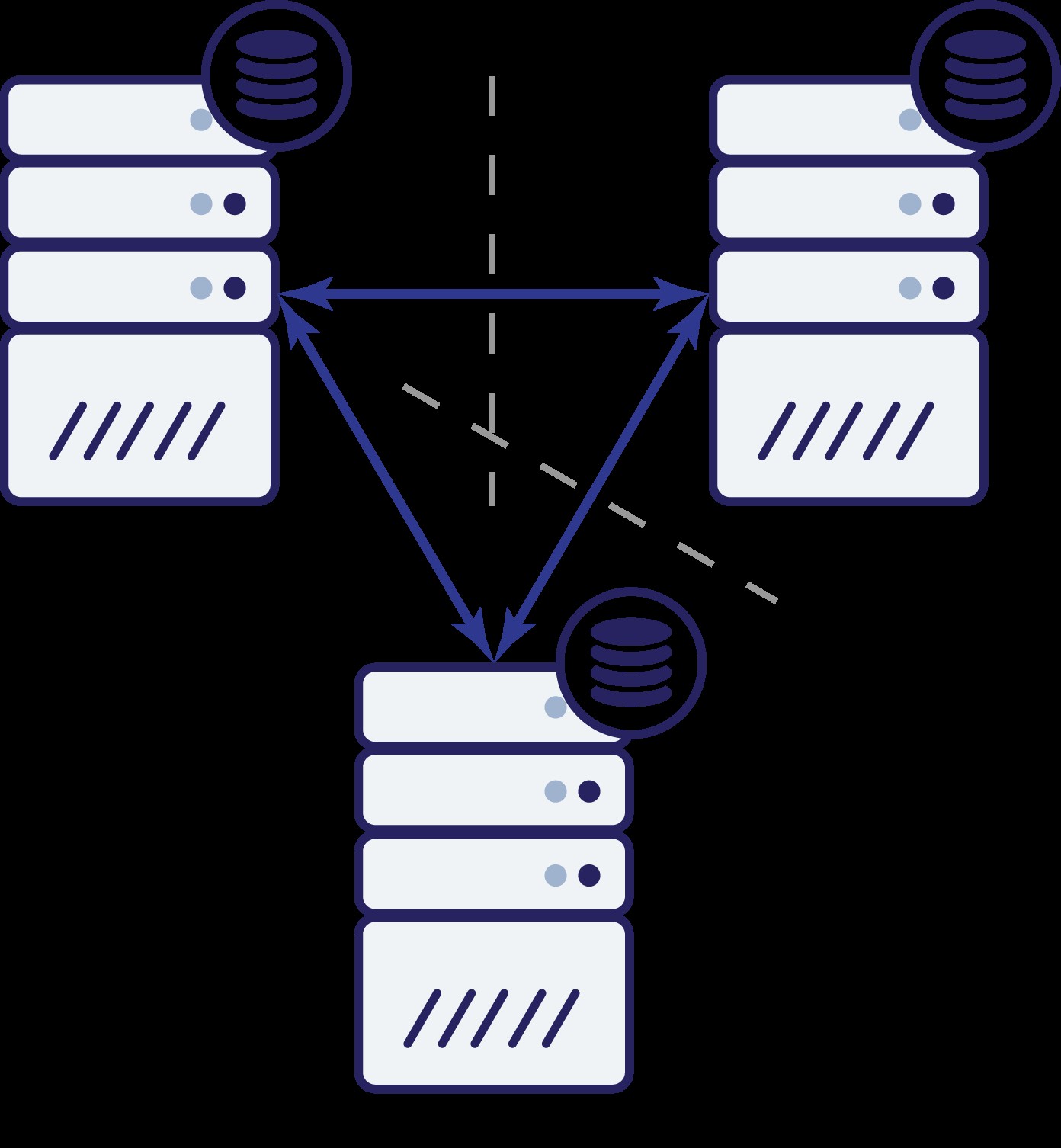
Anche in questo caso, come nell'esempio precedente, il nodo B è stato tagliato fuori dal resto del cluster a causa di problemi di rete. Cosa può succedere dopo? Bene, la situazione è abbastanza simile a quella di cui abbiamo discusso prima. Due opzioni:il nodo B può essere inattivo (e il resto del cluster dovrebbe continuare) o può essere attivo, nel qual caso non dovrebbe essere autorizzato a gestire il traffico. Possiamo ora dire qual è lo stato del cluster? Attualmente si. Possiamo vedere che i nodi A e C possono dialogare tra loro e, di conseguenza, possono concordare sul fatto che il nodo B non è disponibile. Non saranno in grado di dire perché è successo, ma quello che sanno è che su tre nodi nel cluster due hanno ancora connettività tra loro. Dato che questi due nodi costituiscono la maggioranza del cluster, è possibile continuare a gestire il traffico. Allo stesso tempo il nodo B può anche dedurre che il problema è dalla sua parte. Non può accedere né al nodo A né al nodo C, rendendo il nodo B separato dal resto del cluster. Poiché è isolato e non fa parte della maggioranza (1 su 3), l'unica azione sicura che può intraprendere è interrompere il servizio del traffico e rifiutarsi di accettare qualsiasi query, assicurando che non si verifichi la deriva dei dati.
Ovviamente, ciò non significa che puoi avere solo tre nodi nel cluster. Se desideri una migliore tolleranza ai guasti, potresti volerne aggiungere di più. Tieni presente, tuttavia, che dovrebbe essere un numero dispari se desideri migliorare l'alta disponibilità. Inoltre, negli esempi precedenti stavamo parlando di "nodi". Tieni presente che questo vale anche per i data center, le zone di disponibilità, ecc. Se hai due data center, ciascuno con lo stesso numero di nodi (diciamo tre nodi ciascuno) e perdi la connettività tra questi due controller di dominio, qui si applicano gli stessi principi - non puoi dire quale metà del cluster dovrebbe iniziare a gestire il traffico. Per poterlo dire, devi avere un osservatore in un terzo datacenter. Può essere un altro insieme di nodi, o solo un singolo host, con il compito
di osservare lo stato dei dataceter rimanenti e prendere parte alle decisioni (un esempio qui potrebbe essere l'arbitro Galera).
Punti di fallimento singoli
L'elevata disponibilità consiste nell'eliminare i singoli punti di errore (SPOF) e nel non introdurne di nuovi nel processo. Cosa sono gli SPOF? Qualsiasi parte della tua infrastruttura che, in caso di guasto, provoca tempi di inattività come definito nello SLA, è chiamata SPOF. La progettazione delle infrastrutture richiede un approccio olistico, i diversi componenti non possono essere progettati indipendentemente l'uno dall'altro. Molto probabilmente, non sei responsabile dell'intera progettazione:
gli amministratori di database tendono a concentrarsi sui database e non, ad esempio, sul livello di rete. Tuttavia, devi tenere a mente le altre parti e lavorare con i team che ne sono responsabili, per assicurarti che non solo la parte di cui sei responsabile sia progettata correttamente ma anche che i restanti bit dell'infrastruttura siano stati progettati utilizzando il stessi principi. Inoltre, tale conoscenza di come è progettata l'intera infrastruttura, aiuta anche a progettare lo stack del database. Sapere quali problemi possono verificarsi aiuta a costruire alcuni meccanismi per impedire che influiscano sulla disponibilità del database.