In riferimento al tuo commento:
@MarcB il database è normalizzato, la stringa CSV proviene dall'interfaccia utente. "Ottieni i dati per le seguenti persone:101,202,303"
Questa risposta si concentra solo su quei numeri separati da una virgola. Perché, a quanto pare, non stavi nemmeno parlando di FIND_IN_SET dopotutto.
Sì, puoi ottenere ciò che desideri. Crei un'istruzione preparata che accetta una stringa come parametro come in questa Risposta recente
mio. In quella risposta, guarda il secondo blocco che mostra la CREATE PROCEDURE e il suo secondo parametro che accetta una stringa come (1,2,3) . Tornerò su questo punto tra un momento.
Non che tu debba vederlo @spraff ma altri potrebbero. La missione è ottenere il type !=TUTTI e possible_keys e keys di Spiega per non mostrare null, come hai mostrato nel secondo blocco. Per una lettura generale sull'argomento, vedere l'articolo Capire Output di EXPLAIN
e la pagina del manuale MySQL intitolata EXPLAIN Informazioni aggiuntive
.
Ora, torniamo al (1,2,3) riferimento sopra. Sappiamo dal tuo commento e dal tuo secondo output Spiega nella tua domanda che soddisfa le seguenti condizioni desiderate:
- tipo =range (e in particolare non ALL) . Vedi i documenti sopra su questo.
- la chiave non è nulla
Queste sono esattamente le condizioni che hai nel tuo secondo output Spiega e l'output che può essere visto con la seguente query:
explain
select * from ratings where id in (2331425, 430364, 4557546, 2696638, 4510549, 362832, 2382514, 1424071, 4672814, 291859, 1540849, 2128670, 1320803, 218006, 1827619, 3784075, 4037520, 4135373, ... use your imagination ..., ..., 4369522, 3312835);
dove ho 999 valori in quel in elenco di clausole. Questo è un esempio di questa risposta
mio nell'Appendice D che genera una tale stringa casuale di csv, circondata da parentesi aperte e chiuse.
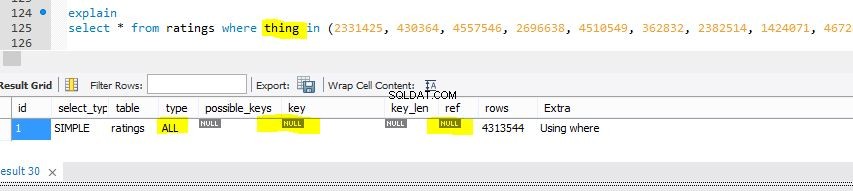
E nota quanto segue Spiega l'output per quell'elemento 999 nella clausola seguente:

Obiettivo raggiunto. Puoi ottenere questo risultato con un processo memorizzato simile a quello che ho menzionato prima in questo link
utilizzando un PREPARED STATEMENT
(e quelle cose usano concat() seguito da un EXECUTE ).
L'indice viene utilizzato, un Tablescan (che significa cattivo) non viene sperimentato. Ulteriori letture sono Il tipo di join dell'intervallo
, qualsiasi riferimento che puoi trovare su Cost-Based Optimizer (CBO) di MySQL, questa risposta
da vladr sebbene datato, con un occhio al ANALYZE TABLE
parte, in particolare a seguito di modifiche significative dei dati. Si noti che ANALYZE può richiedere una notevole quantità di tempo per l'esecuzione su set di dati estremamente enormi. A volte molte molte ore.
Attacchi di iniezione SQL:
L'uso di stringhe passate alle stored procedure è un vettore di attacco per gli attacchi SQL Injection. Devono essere adottate precauzioni per prevenirli quando si utilizzano i dati forniti dall'utente. Se la tua routine viene applicata contro i tuoi ID generati dal tuo sistema, allora sei al sicuro. Si noti, tuttavia, che gli attacchi SQL Injection di 2° livello si verificano quando i dati sono stati inseriti da routine che non hanno disinfettato tali dati in un inserimento o aggiornamento precedente. Attacchi messi in atto prima tramite dati e utilizzati successivamente (una sorta di bomba a orologeria).
Quindi questa risposta è Completata per la maggior parte.
Quella di seguito è una vista della stessa tabella con una piccola modifica per mostrare ciò che un temuto Tablescan sarebbe simile alla query precedente (ma rispetto a una colonna non indicizzata denominata thing ).
Dai un'occhiata alla nostra attuale definizione di tabella:
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
select min(id), max(id),count(*) as theCount from ratings;
+---------+---------+----------+
| min(id) | max(id) | theCount |
+---------+---------+----------+
| 1 | 5046213 | 4718592 |
+---------+---------+----------+
Nota che la colonna thing prima era una colonna int nullable.
update ratings set thing=id where id<1000000;
update ratings set thing=id where id>=1000000 and id<2000000;
update ratings set thing=id where id>=2000000 and id<3000000;
update ratings set thing=id where id>=3000000 and id<4000000;
update ratings set thing=id where id>=4000000 and id<5100000;
select count(*) from ratings where thing!=id;
-- 0 rows
ALTER TABLE ratings MODIFY COLUMN thing int not null;
-- current table definition (after above ALTER):
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
E poi Spiega che è un Tablescan (contro la colonna thing ):