Questo è un problema abbastanza comune.
B-Tree semplice gli indici non vanno bene per le query come questa:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
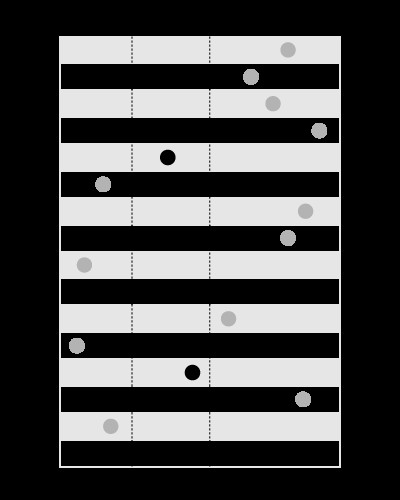
Un indice è utile per cercare i valori entro i limiti dati, come questo:
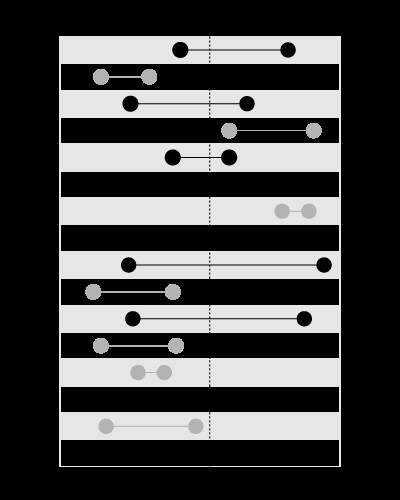
, ma non per cercare i limiti che contengono il valore dato, come questo:
Questo articolo nel mio blog spiega il problema in modo più dettagliato:
(il modello degli insiemi annidati si occupa del tipo simile di predicato).
Puoi fare l'indice su time , in questo modo gli intervals sarà all'inizio del join, il tempo con intervallo verrà utilizzato all'interno dei loop nidificati. Ciò richiederà l'ordinamento in base al time .
Puoi creare un indice spaziale su intervals (disponibile in MySQL utilizzando MyISAM storage) che includerebbe start e end in una colonna geometrica. In questo modo, measures può condurre nel join e non sarà necessario alcun ordinamento.
Gli indici spaziali, tuttavia, sono più lenti, quindi questo sarà efficiente solo se hai poche misure ma molti intervalli.
Dato che hai pochi intervalli ma molte misure, assicurati di avere un indice su measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Aggiornamento:
Ecco uno script di esempio da testare:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Questa domanda:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
utilizza NESTED LOOPS e ritorna in 1.7 secondi.
Questa domanda:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
utilizza MERGE JOIN e ho dovuto interromperlo dopo 5 minuti.
Aggiornamento 2:
Molto probabilmente dovrai forzare il motore a utilizzare l'ordine corretto delle tabelle nel join usando un suggerimento come questo:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
L'Oracle L'ottimizzatore non è abbastanza intelligente da vedere che gli intervalli non si intersecano. Ecco perché molto probabilmente utilizzerà measures come tavolo principale (che sarebbe una decisione saggia se gli intervalli si intersecano).
Aggiornamento 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Questa query suddivide l'asse temporale negli intervalli e utilizza un HASH JOIN per unire misure e timestamp sui valori dell'intervallo, con filtraggio fine in seguito.
Vedi questo articolo nel mio blog per spiegazioni più dettagliate su come funziona: