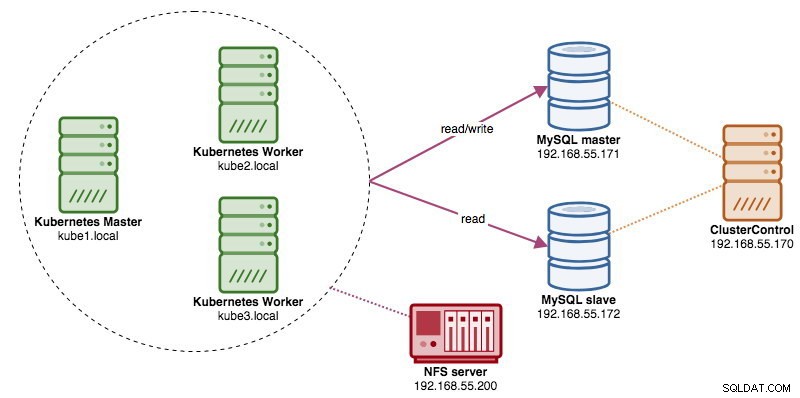
Quando si eseguono cluster di database distribuiti, è abbastanza comune anticiparli con i servizi di bilanciamento del carico. I vantaggi sono evidenti:bilanciamento del carico, failover della connessione e disaccoppiamento del livello dell'applicazione dalle topologie di database sottostanti. Per un bilanciamento del carico più intelligente, un proxy sensibile al database come ProxySQL o MaxScale sarebbe la strada da percorrere. Nel nostro blog precedente, ti abbiamo mostrato come eseguire ProxySQL come contenitore di supporto in Kubernetes. In questo post del blog, ti mostreremo come distribuire ProxySQL come servizio Kubernetes. Useremo Wordpress come applicazione di esempio e il backend del database è in esecuzione su una replica MySQL a due nodi distribuita utilizzando ClusterControl. Il diagramma seguente illustra la nostra infrastruttura:
Dal momento che implementeremo una configurazione simile a quella di questo post del blog precedente, aspettati che la duplicazione in alcune parti del post del blog mantenga il post più leggibile.
ProxySQL su Kubernetes
Cominciamo con un po' di riassunto. La progettazione di un'architettura ProxySQL è un argomento soggettivo e fortemente dipendente dal posizionamento dell'applicazione, dai contenitori di database e dal ruolo di ProxySQL stesso. Idealmente, possiamo configurare ProxySQL per essere gestito da Kubernetes con due configurazioni:
- ProxySQL come servizio Kubernetes (distribuzione centralizzata)
- ProxySQL come contenitore di supporto in un pod (distribuzione distribuita)
Entrambe le distribuzioni possono essere facilmente distinte osservando il diagramma seguente:
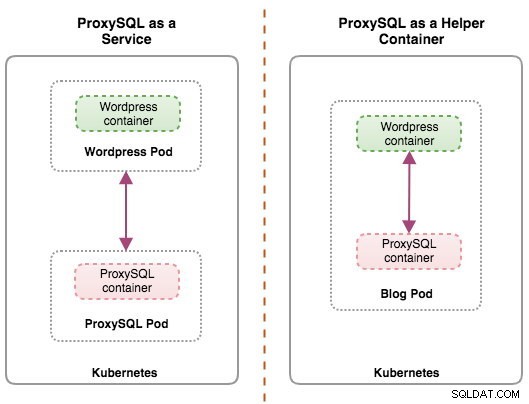
Questo post del blog tratterà la prima configurazione:eseguire ProxySQL come servizio Kubernetes. La seconda configurazione è già trattata qui. Contrariamente all'approccio del contenitore di supporto, l'esecuzione come servizio fa sì che i pod ProxySQL risiedano indipendentemente dalle applicazioni e possono essere facilmente ridimensionati e raggruppati insieme con l'aiuto di Kubernetes ConfigMap. Questo è sicuramente un approccio di clustering diverso rispetto al supporto del clustering nativo ProxySQL che si basa sul checksum di configurazione tra le istanze ProxySQL (ovvero proxysql_servers). Dai un'occhiata a questo post del blog se vuoi saperne di più sul clustering ProxySQL semplificato con ClusterControl.
In Kubernetes, il sistema di configurazione multilivello di ProxySQL rende possibile il clustering dei pod con ConfigMap. Tuttavia, ci sono una serie di carenze e soluzioni alternative per farlo funzionare senza problemi come fa la funzionalità di clustering nativa di ProxySQL. Al momento, segnalare un pod all'aggiornamento di ConfigMap è una funzionalità in lavorazione. Tratteremo questo argomento in modo molto più dettagliato in un prossimo post sul blog.
Fondamentalmente, dobbiamo creare pod ProxySQL e collegare un servizio Kubernetes a cui possano accedere gli altri pod all'interno della rete Kubernetes o esternamente. Le applicazioni si connetteranno quindi al servizio ProxySQL tramite rete TCP/IP sulle porte configurate. Il valore predefinito è 6033 per le connessioni con bilanciamento del carico MySQL e 6032 per la console di amministrazione ProxySQL. Con più di una replica, le connessioni al pod verranno bilanciate automaticamente dal componente Kubernetes kube-proxy in esecuzione su ogni nodo Kubernetes.
ProxySQL come servizio Kubernetes
In questa configurazione, eseguiamo sia ProxySQL che Wordpress come pod e servizi. Il diagramma seguente illustra la nostra architettura di alto livello:
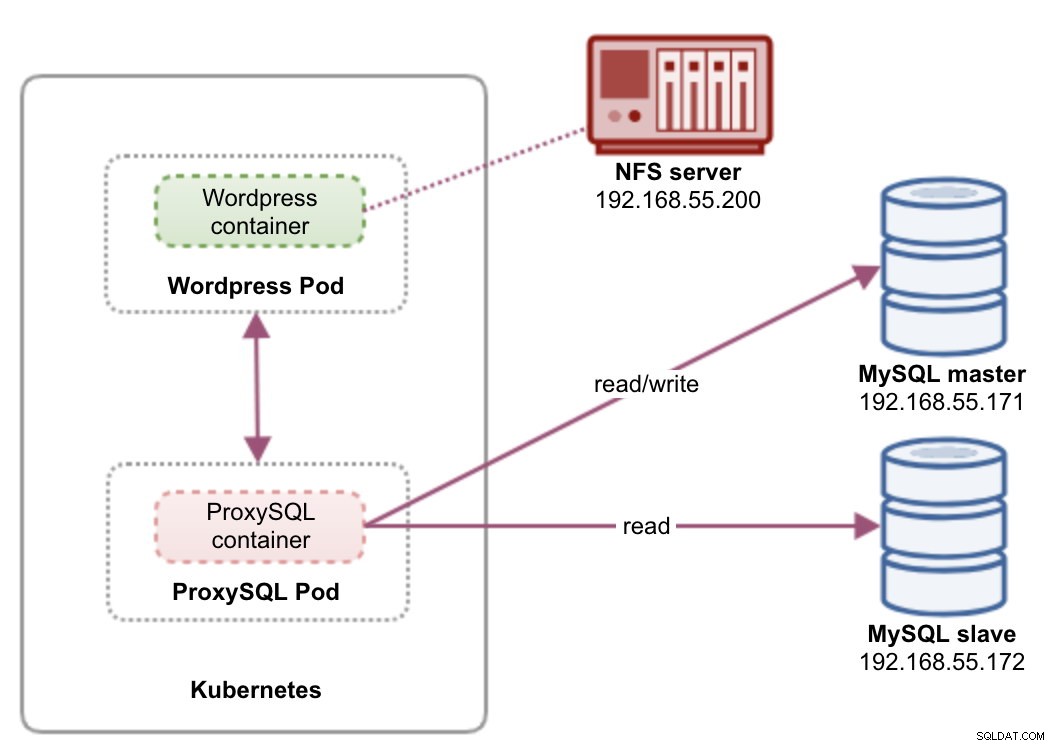
In questa configurazione, implementeremo due pod e servizi:"wordpress" e "proxysql". Uniremo la dichiarazione di distribuzione e servizio in un file YAML per applicazione e le gestiremo come un'unica unità. Per mantenere il contenuto dei contenitori dell'applicazione persistente su più nodi, dobbiamo utilizzare un file system cluster o remoto, che in questo caso è NFS.
La distribuzione di ProxySQL come servizio offre un paio di aspetti positivi rispetto all'approccio del contenitore di supporto:
- Utilizzando l'approccio Kubernetes ConfigMap, ProxySQL può essere raggruppato con una configurazione immutabile.
- Kubernetes gestisce il ripristino di ProxySQL e bilancia automaticamente le connessioni alle istanze.
- Un singolo endpoint con implementazione dell'indirizzo IP virtuale Kubernetes chiamato ClusterIP.
- Livello proxy inverso centralizzato con architettura nulla condivisa.
- Può essere utilizzato con applicazioni esterne al di fuori di Kubernetes.
Inizieremo la distribuzione come due repliche per ProxySQL e tre per Wordpress per dimostrare l'esecuzione su larga scala e le capacità di bilanciamento del carico offerte da Kubernetes.
Preparazione del database
Crea il database wordpress e l'utente sul master e assegna con il privilegio corretto:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Inoltre, crea l'utente di monitoraggio ProxySQL:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Quindi, ricarica la tabella delle sovvenzioni:
mysql-master> FLUSH PRIVILEGES;Pod proxySQL e definizione del servizio
Il prossimo è preparare la nostra distribuzione ProxySQL. Crea un file chiamato proxysql-rs-svc.yml e aggiungi le seguenti righe:
apiVersion: v1
kind: Deployment
metadata:
name: proxysql
labels:
app: proxysql
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: proxysql
tier: frontend
spec:
restartPolicy: Always
containers:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap
---
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendVediamo di cosa trattano queste definizioni. YAML è costituito da due risorse combinate in un file, separate dal delimitatore "---". La prima risorsa è il Deployment, che definiamo con la seguente specifica:
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdateQuanto sopra significa che vorremmo distribuire due pod ProxySQL come ReplicaSet che corrisponda ai contenitori etichettati con "app=proxysql,tier=frontend". La strategia di distribuzione specifica la strategia utilizzata per sostituire i vecchi pod con quelli nuovi. In questa distribuzione, abbiamo selezionato RollingUpdate, il che significa che i pod verranno aggiornati in modo continuo, un pod alla volta.
La parte successiva è il modello del contenitore:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmapIn spec.templates.spec.containers.* sezione, stiamo dicendo a Kubernetes di distribuire ProxySQL usando diverselnines/proxysql immagine versione 1.4.12. Vogliamo anche che Kubernetes monti il nostro file di configurazione preconfigurato personalizzato e lo mappi a /etc/proxysql.cnf all'interno del contenitore. I pod in esecuzione pubblicheranno due porte:6033 e 6032. Definiamo anche la sezione "volumi", in cui indichiamo a Kubernetes di montare ConfigMap come volume all'interno dei pod ProxySQL da montare da volumeMounts.
La seconda risorsa è il servizio. Un servizio Kubernetes è un livello di astrazione che definisce l'insieme logico di pod e una politica in base alla quale accedervi. In questa sezione, definiamo quanto segue:
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendIn questo caso, vogliamo che il nostro ProxySQL sia accessibile dalla rete esterna, quindi il tipo NodePort è il tipo scelto. Questo pubblicherà nodePort su ogni nodo Kubernetes nel cluster. L'intervallo di porte valide per la risorsa NodePort è 30000-32767. Abbiamo scelto la porta 30033 per connessioni con bilanciamento del carico MySQL mappata sulla porta 6033 dei pod ProxySQL e la porta 30032 per la porta di amministrazione ProxySQL mappata su 6032.
Pertanto, in base alla nostra definizione YAML sopra, dobbiamo preparare la seguente risorsa Kubernetes prima di poter iniziare a distribuire il pod "proxysql":
- ConfigMap - Per archiviare il file di configurazione ProxySQL come volume in modo che possa essere montato su più pod e possa essere rimontato di nuovo se il pod viene riprogrammato sull'altro nodo Kubernetes.
Preparazione di ConfigMap per ProxySQL
Simile al post del blog precedente, utilizzeremo l'approccio ConfigMap per disaccoppiare il file di configurazione dal contenitore e anche per scopi di scalabilità. Tieni presente che in questa configurazione, consideriamo la nostra configurazione ProxySQL immutabile.
Innanzitutto, crea il file di configurazione di ProxySQL, proxysql.cnf e aggiungi le seguenti righe:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="proxysql-admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)Presta attenzione a admin_variables.admin_credentials variabile in cui abbiamo utilizzato un utente non predefinito che è "proxysql-admin". ProxySQL riserva l'utente "admin" predefinito solo per la connessione locale tramite localhost. Pertanto, dobbiamo utilizzare altri utenti per accedere all'istanza ProxySQL in remoto. In caso contrario, avresti il seguente errore:
ERROR 1040 (42000): User 'admin' can only connect locallyLa nostra configurazione ProxySQL si basa sui nostri due server di database in esecuzione in MySQL Replication, come riepilogato nella seguente schermata della topologia presa da ClusterControl:
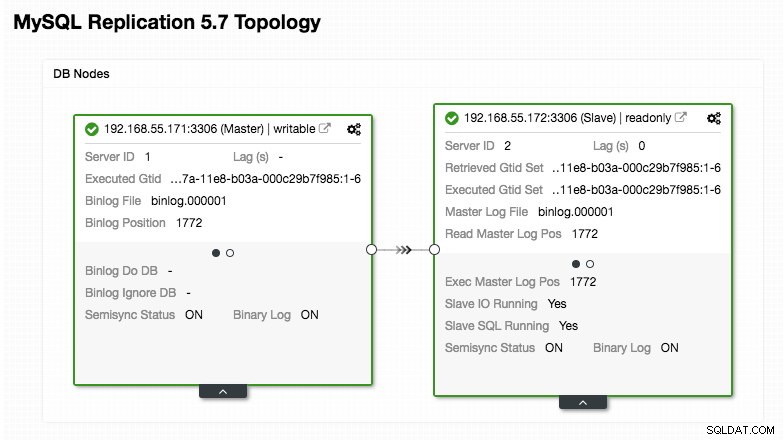
Tutte le scritture dovrebbero andare al nodo master mentre le letture vengono inoltrate al gruppo host 20, come definito nella sezione "mysql_query_rules". Questa è la base della suddivisione in lettura/scrittura e vogliamo utilizzarle del tutto.
Quindi, importa il file di configurazione in ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVerifica se ConfigMap è caricato in Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sPod Wordpress e definizione del servizio
Ora incolla le seguenti righe in un file chiamato wordpress-rs-svc.yml sull'host in cui è configurato kubectl:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033 # proxysql.default.svc.cluster.local:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_DATABASE
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendSimile alla nostra definizione ProxySQL, YAML è costituito da due risorse, separate dal delimitatore "---" combinate in un file. La prima è la risorsa Deployment, che verrà distribuita come ReplicaSet, come mostrato nella sezione "spec.*":
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdateQuesta sezione fornisce la specifica di distribuzione:3 pod per iniziare che corrispondono all'etichetta "app=wordpress,tier=backend". La strategia di distribuzione è RollingUpdate, il che significa che il modo in cui Kubernetes sostituirà il pod è utilizzando la modalità di aggiornamento in sequenza, lo stesso con la nostra distribuzione ProxySQL.
La parte successiva è la sezione "spec.template.spec.*":
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
In questa sezione, stiamo dicendo a Kubernetes di distribuire Wordpress 4.9 utilizzando il server Web Apache e abbiamo assegnato al contenitore il nome "wordpress". Il contenitore verrà riavviato ogni volta che è inattivo, indipendentemente dallo stato. Vogliamo anche che Kubernetes passi una serie di variabili d'ambiente:
- WORDPRESS_DB_HOST - L'host del database MySQL. Poiché utilizziamo ProxySQL come servizio, il nome del servizio sarà il valore di metadata.name che è "proxysql". ProxySQL è in ascolto sulla porta 6033 per connessioni MySQL con bilanciamento del carico mentre la console di amministrazione ProxySQL è su 6032.
- WORDPRESS_DB_USER - Specificare l'utente del database wordpress che è stato creato nella sezione "Preparazione del database".
- WORDPRESS_DB_PASSWORD - La password per WORDPRESS_DB_USER . Poiché non vogliamo esporre la password in questo file, possiamo nasconderla utilizzando Kubernetes Secrets. Qui indichiamo a Kubernetes di leggere invece la risorsa segreta "mysql-pass". I segreti devono essere creati in anticipo prima dell'implementazione del pod, come spiegato più avanti.
Vogliamo anche pubblicare la porta 80 del pod per l'utente finale. Il contenuto di Wordpress archiviato all'interno di /var/www/html nel contenitore verrà montato nella nostra memoria permanente in esecuzione su NFS. Utilizzeremo le risorse PersistentVolume e PersistentVolumeClaim per questo scopo, come mostrato nella sezione "Preparazione dell'archiviazione persistente per Wordpress".
Dopo la linea di interruzione "---", definiamo un'altra risorsa chiamata Servizio:
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendIn questa configurazione, vorremmo che Kubernetes creasse un servizio chiamato "wordpress", ascolti sulla porta 30088 su tutti i nodi (aka NodePort) alla rete esterna e lo inoltri alla porta 80 su tutti i pod etichettati con "app=wordpress,tier=front-end".
Pertanto, in base alla nostra definizione YAML di cui sopra, dobbiamo preparare un certo numero di risorse Kubernetes prima di poter iniziare a distribuire il pod e il servizio "wordpress":
- Volume persistente e Richiesta volume persistente - Per archiviare i contenuti web della nostra applicazione Wordpress, così quando il pod viene riprogrammato su un altro nodo di lavoro, non perderemo le ultime modifiche.
- Segreti - Per nascondere la password utente del database Wordpress all'interno del file YAML.
Preparazione dell'archiviazione persistente per Wordpress
Una buona memoria persistente per Kubernetes dovrebbe essere accessibile da tutti i nodi Kubernetes nel cluster. Per il bene di questo post del blog, abbiamo utilizzato NFS come provider PersistentVolume (PV) perché è facile e supportato immediatamente. Il server NFS si trova da qualche parte al di fuori della nostra rete Kubernetes (come mostrato nel primo diagramma dell'architettura) e lo abbiamo configurato per consentire tutti i nodi Kubernetes con la seguente riga all'interno di /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Tieni presente che il pacchetto client NFS deve essere installato su tutti i nodi Kubernetes. In caso contrario, Kubernetes non sarebbe in grado di montare correttamente l'NFS. Su tutti i nodi:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSInoltre, assicurati che sul server NFS esista la directory di destinazione:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressQuindi, crea un file chiamato wordpress-pv-pvc.yml e aggiungi le seguenti righe:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: wordpress
tier: frontendNella definizione di cui sopra, stiamo dicendo a Kubernetes di allocare 3 GB di spazio di volume sul server NFS per il nostro contenitore Wordpress. Prendi nota per l'utilizzo in produzione, NFS deve essere configurato con provisioner automatico e classe di archiviazione.
Crea le risorse FV e PVC:
$ kubectl create -f wordpress-pv-pvc.ymlVerifica se tali risorse sono state create e lo stato deve essere "Bound":
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hPreparazione dei segreti per Wordpress
Crea un segreto che verrà utilizzato dal contenitore di Wordpress per WORDPRESS_DB_PASSWORD variabile d'ambiente. Il motivo è semplicemente perché non vogliamo esporre la password in chiaro all'interno del file YAML.
Crea una risorsa segreta chiamata mysql-pass e passa la password di conseguenza:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVerifica che il nostro segreto sia stato creato:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mDistribuzione di ProxySQL e Wordpress
Infine, possiamo iniziare la distribuzione. Distribuisci prima ProxySQL, seguito da Wordpress:
$ kubectl create -f proxysql-rs-svc.yml
$ kubectl create -f wordpress-rs-svc.ymlPossiamo quindi elencare tutti i pod e i servizi che sono stati creati nel livello "frontend":
$ kubectl get pods,services -l tier=frontend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
pod/proxysql-95b8d8446-qfbf2 1/1 Running 0 12m 10.36.0.2 kube2.local <none>
pod/proxysql-95b8d8446-vljlr 1/1 Running 0 12m 10.44.0.6 kube3.local <none>
pod/wordpress-59489d57b9-4dzvk 1/1 Running 0 37m 10.36.0.1 kube2.local <none>
pod/wordpress-59489d57b9-7d2jb 1/1 Running 0 30m 10.44.0.4 kube3.local <none>
pod/wordpress-59489d57b9-gw4p9 1/1 Running 0 30m 10.36.0.3 kube2.local <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/proxysql NodePort 10.108.195.54 <none> 6033:30033/TCP,6032:30032/TCP 10m app=proxysql,tier=frontend
service/wordpress NodePort 10.109.144.234 <none> 80:30088/TCP 37m app=wordpress,tier=frontend
kube2.local <none>L'output di cui sopra verifica la nostra architettura di distribuzione in cui attualmente disponiamo di tre pod Wordpress, esposti pubblicamente sulla porta 30088, nonché sulla nostra istanza ProxySQL che è esposta sulle porte 30033 e 30032 esternamente più 6033 e 6032 internamente.
A questo punto, la nostra architettura è simile a questa:
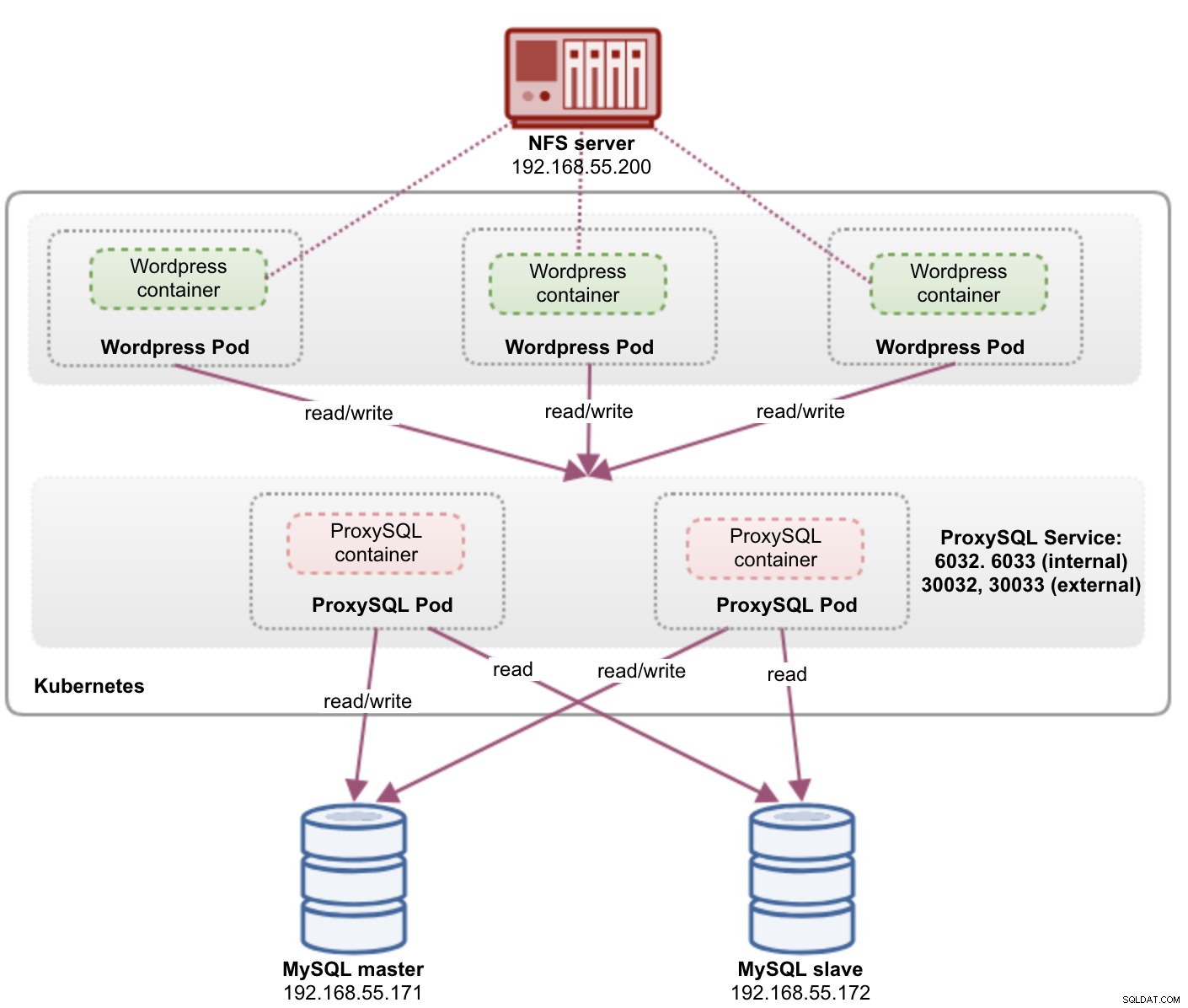
La porta 80 pubblicata dai pod di Wordpress è ora mappata al mondo esterno tramite la porta 30088. Possiamo accedere al nostro post sul blog all'indirizzo https://{any_kubernetes_host}:30088/ e dovrebbe essere reindirizzato alla pagina di installazione di Wordpress. Se procediamo con l'installazione, salterà la parte relativa alla connessione al database e mostrerà direttamente questa pagina:
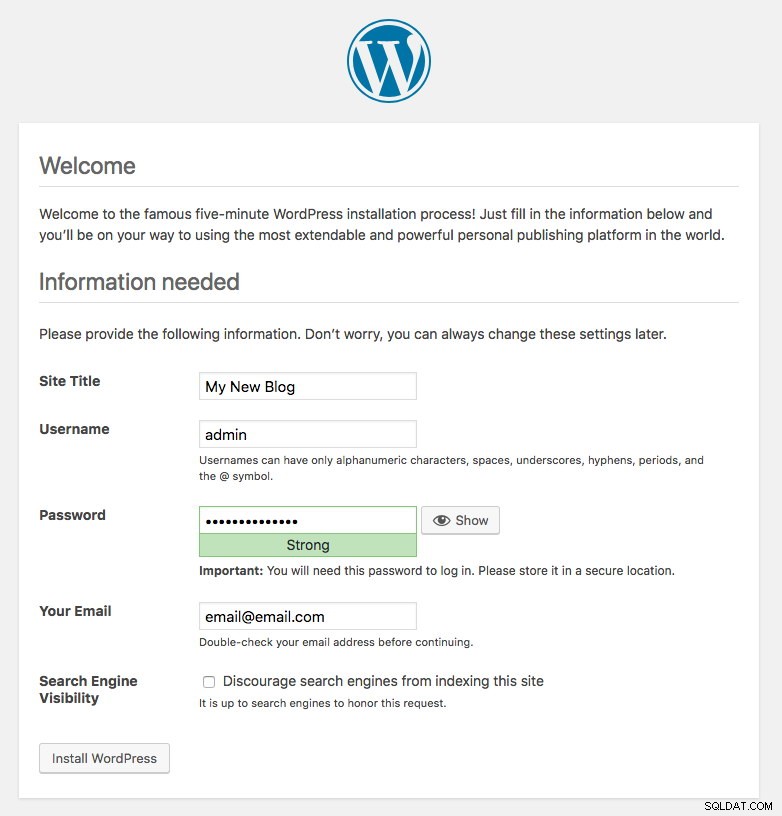
Indica che la nostra configurazione MySQL e ProxySQL è configurata correttamente all'interno del file wp-config.php. In caso contrario, verrai reindirizzato alla pagina di configurazione del database.
La nostra distribuzione è ora completa.
Pod proxySQL e gestione dei servizi
Il failover e il ripristino dovrebbero essere gestiti automaticamente da Kubernetes. Ad esempio, se un lavoratore Kubernetes si interrompe, il pod verrà ricreato nel successivo nodo disponibile dopo --pod-eviction-timeout (predefinito a 5 minuti). Se il contenitore si arresta in modo anomalo o viene interrotto, Kubernetes lo sostituirà quasi istantaneamente.
Alcune attività di gestione comuni dovrebbero essere diverse durante l'esecuzione all'interno di Kubernetes, come mostrato nelle sezioni successive.
Connessione a ProxySQL
Sebbene ProxySQL sia esposto esternamente sulla porta 30033 (MySQL) e 30032 (Admin), è anche accessibile internamente tramite le porte pubblicate, rispettivamente 6033 e 6032. Pertanto, per accedere alle istanze ProxySQL all'interno della rete Kubernetes, utilizzare CLUSTER-IP o il nome del servizio "proxysql" come valore host. Ad esempio, all'interno del pod di Wordpress, puoi accedere alla console di amministrazione di ProxySQL utilizzando il comando seguente:
$ mysql -uproxysql-admin -p -hproxysql -P6032Se vuoi connetterti esternamente, usa la porta definita in nodePort value nel servizio YAML e scegli uno qualsiasi dei nodi Kubernetes come valore host:
$ mysql -uproxysql-admin -p -hkube3.local -P30032Lo stesso vale per la connessione MySQL con bilanciamento del carico sulla porta 30033 (esterna) e 6033 (interna).
Scala su e giù
Aumentare è facile con Kubernetes:
$ kubectl scale deployment proxysql --replicas=5
deployment.extensions/proxysql scaledVerifica lo stato di implementazione:
$ kubectl rollout status deployment proxysql
deployment "proxysql" successfully rolled outAnche il ridimensionamento è simile. Qui vogliamo ripristinare da 5 a 2 repliche:
$ kubectl scale deployment proxysql --replicas=2
deployment.extensions/proxysql scaledPossiamo anche esaminare gli eventi di distribuzione per ProxySQL per avere un quadro migliore di ciò che è accaduto per questa distribuzione utilizzando l'opzione "descrivi":
$ kubectl describe deployment proxysql
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 0
Normal ScalingReplicaSet 7m10s deployment-controller Scaled up replica set proxysql-6c55f647cb to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled down replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled up replica set proxysql-6c55f647cb to 2
Normal ScalingReplicaSet 6m53s deployment-controller Scaled down replica set proxysql-769895fbf7 to 0
Normal ScalingReplicaSet 54s deployment-controller Scaled up replica set proxysql-6c55f647cb to 5
Normal ScalingReplicaSet 21s deployment-controller Scaled down replica set proxysql-6c55f647cb to 2Le connessioni ai pod verranno bilanciate automaticamente da Kubernetes.
Modifiche alla configurazione
Un modo per apportare modifiche alla configurazione sui nostri pod ProxySQL è eseguire la versione della nostra configurazione utilizzando un altro nome ConfigMap. Innanzitutto, modifica il nostro file di configurazione direttamente tramite il tuo editor di testo preferito:
$ vim /root/proxysql.cnfQuindi, caricalo in Kubernetes ConfigMap con un nome diverso. In questo esempio, aggiungiamo "-v2" nel nome della risorsa:
$ kubectl create configmap proxysql-configmap-v2 --from-file=proxysql.cnfVerifica se ConfigMap è caricato correttamente:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 3d15h
proxysql-configmap-v2 1 19mApri il file di distribuzione ProxySQL, proxysql-rs-svc.yml e cambia la seguente riga nella sezione configMap alla nuova versione:
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap-v2 #change this lineQuindi, applica le modifiche alla nostra distribuzione ProxySQL:
$ kubectl apply -f proxysql-rs-svc.yml
deployment.apps/proxysql configured
service/proxysql configuredVerifica il rollout esaminando l'evento ReplicaSet utilizzando il flag "descrivi":
$ kubectl describe proxysql
...
Pod Template:
Labels: app=proxysql
tier=frontend
Containers:
proxysql:
Image: severalnines/proxysql:1.4.12
Ports: 6033/TCP, 6032/TCP
Host Ports: 0/TCP, 0/TCP
Environment: <none>
Mounts:
/etc/proxysql.cnf from proxysql-config (rw)
Volumes:
proxysql-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: proxysql-configmap-v2
Optional: false
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: proxysql-769895fbf7 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 53s deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 41s deployment-controller Scaled down replica set proxysql-95b8d8446 to 0Prestare attenzione alla sezione "Volumi" con il nuovo nome ConfigMap. Puoi anche vedere gli eventi di distribuzione nella parte inferiore dell'output. A questo punto, la nostra nuova configurazione è stata caricata in tutti i pod ProxySQL, in cui Kubernetes ha ridimensionato ProxySQL ReplicaSet a 0 (obbedendo alla strategia RollingUpdate) e riportandoli allo stato desiderato di 2 repliche.
Pensieri finali
Fino a questo punto, abbiamo trattato il possibile approccio di distribuzione per ProxySQL in Kubernetes. L'esecuzione di ProxySQL con l'aiuto di Kubernetes ConfigMap apre una nuova possibilità di clustering ProxySQL, dove è leggermente diverso rispetto al supporto nativo per il clustering integrato in ProxySQL.
Nel prossimo post del blog, esploreremo il clustering ProxySQL utilizzando Kubernetes ConfigMap e come farlo nel modo giusto. Resta sintonizzato!