AGGIORNAMENTO:2 settembre 2021 (Pubblicato originariamente il 26 luglio 2012.)
Molte cose cambiano nel corso di alcune versioni principali della nostra piattaforma di database preferita. SQL Server 2016 ci ha portato STRING_SPLIT, una funzione nativa che elimina la necessità di molte delle soluzioni personalizzate di cui avevamo bisogno in precedenza. È anche veloce, ma non è perfetto. Ad esempio, supporta solo un delimitatore a carattere singolo e non restituisce nulla per indicare l'ordine degli elementi di input. Ho scritto diversi articoli su questa funzione (e STRING_AGG, che è arrivato in SQL Server 2017) da quando è stato scritto questo post:
- Sorprese e presupposti sulle prestazioni:STRING_SPLIT()
- STRING_SPLIT() in SQL Server 2016:follow-up n. 1
- STRING_SPLIT() in SQL Server 2016:follow-up n. 2
- Codice di sostituzione della stringa divisa di SQL Server con STRING_SPLIT
- Confronto dei metodi di divisione/concatenazione delle stringhe
- Risolvi vecchi problemi con le nuove funzioni STRING_AGG e STRING_SPLIT di SQL Server
- Gestione del delimitatore a carattere singolo nella funzione STRING_SPLIT di SQL Server
- Aiutaci con STRING_SPLIT miglioramenti
- Un modo per migliorare STRING_SPLIT in SQL Server e puoi aiutare
Lascerò qui il contenuto di seguito per i posteri e la rilevanza storica, e anche perché parte della metodologia di test è rilevante per altri problemi oltre alla divisione delle stringhe, ma per favore vedere alcuni dei riferimenti sopra per informazioni su come dovresti dividere stringhe nelle versioni moderne e supportate di SQL Server, oltre a questo post, che spiega perché la divisione delle stringhe forse non è un problema che vuoi che il database risolva in primo luogo, nuova funzione o meno.
- Dividi le stringhe:ora con meno T-SQL
So che molte persone sono annoiate dal problema delle "stringhe divise", ma sembra ancora venire fuori quasi ogni giorno su forum e siti di domande e risposte come Stack Overflow. Questo è il problema per cui le persone vogliono passare una stringa come questa:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
All'interno della procedura, vogliono fare qualcosa del genere:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Questo non funziona perché @FavoriteTeams è una singola stringa e quanto sopra si traduce in:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server cercherà quindi di trovare un team chiamato Patriots, Red Sox, Bruins , e suppongo che non ci sia una squadra del genere. Quello che vogliono davvero qui è l'equivalente di:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Ma poiché non esiste un tipo di matrice in SQL Server, non è affatto così che viene interpretata la variabile:è ancora una semplice stringa singola che contiene alcune virgole. Progettazione di schemi discutibile a parte, in questo caso l'elenco separato da virgole deve essere "diviso" in valori individuali - e questa è la domanda che spesso stimola molti "nuovi" dibattiti e commenti sulla soluzione migliore per ottenere proprio questo.
La risposta sembra essere, quasi invariabilmente, che dovresti usare CLR. Se non potete usare CLR – e so che ci sono molti di voi là fuori che non possono, a causa della politica aziendale, del capo dai capelli a punta o della testardaggine – allora usate una delle tante soluzioni alternative che esistono. E esistono molte soluzioni alternative.
Ma quale dovresti usare?
Confronterò le prestazioni di alcune soluzioni e mi concentrerò sulla domanda che tutti si pongono sempre:"Qual è il più veloce?" Non ho intenzione di approfondire la discussione su *tutti* i potenziali metodi, perché molti sono già stati eliminati a causa del fatto che semplicemente non sono scalabili. E potrei rivisitarlo in futuro per esaminare l'impatto su altre metriche, ma per ora mi concentrerò solo sulla durata. Ecco i contendenti che ho intenzione di confrontare (usando SQL Server 2012, 11.00.2316, su una VM Windows 7 con 4 CPU e 8 GB di RAM):
CLR
Se desideri utilizzare CLR, dovresti assolutamente prendere in prestito il codice dal collega MVP Adam Machanic prima di pensare di scriverne uno tuo (ho già scritto sul blog di reinventare la ruota, e si applica anche a frammenti di codice gratuiti come questo). Ha trascorso molto tempo a mettere a punto questa funzione CLR per analizzare in modo efficiente una stringa. Se stai attualmente utilizzando una funzione CLR e questa non è quella, ti consiglio vivamente di implementarla e confrontarla:l'ho testata su una routine CLR basata su VB molto più semplice che era funzionalmente equivalente, ma l'approccio VB ha funzionato circa tre volte peggio rispetto a quello di Adam.
Quindi ho preso la funzione di Adam, ho compilato il codice in una DLL (usando csc) e ho distribuito solo quel file sul server. Quindi ho aggiunto il seguente assembly e la funzione al mio database:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Questa è la funzione tipica che utilizzo per scenari occasionali in cui so che l'input è "sicuro", ma non è una funzione che consiglio per gli ambienti di produzione (ne parleremo più avanti).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Un avvertimento molto forte deve accompagnare l'approccio XML:può essere utilizzato solo se puoi garantire che la tua stringa di input non contenga caratteri XML illegali. Un nome con <,> o &e la funzione esploderà. Quindi, indipendentemente dalle prestazioni, se utilizzerai questo approccio, tieni presente i limiti:non dovrebbe essere considerata un'opzione praticabile per uno splitter di stringhe generico. Lo includo in questo riepilogo perché potresti avere un caso in cui puoi fidati dell'input, ad esempio è possibile utilizzarlo per elenchi di numeri interi o GUID separati da virgole.
Tabella dei numeri
Questa soluzione utilizza una tabella di numeri, che devi creare e popolare tu stesso. (Abbiamo richiesto una versione integrata per anni.) La tabella di Numbers dovrebbe contenere abbastanza righe per superare la lunghezza della stringa più lunga che dividerai. In questo caso utilizzeremo 1.000.000 di righe:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (L'uso della compressione dei dati ridurrà drasticamente il numero di pagine richieste, ma ovviamente dovresti usare questa opzione solo se stai utilizzando la Enterprise Edition. In questo caso i dati compressi richiedono 1.360 pagine, contro 2.102 pagine senza compressione, circa un risparmio del 35%. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Espressione di tabella comune
Questa soluzione utilizza un CTE ricorsivo per estrarre ogni parte della stringa dal "resto" della parte precedente. Come CTE ricorsivo con variabili locali, noterai che questa doveva essere una funzione con valori di tabella a più istruzioni, a differenza delle altre che sono tutte inline.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Separatore di Jeff Moden Una funzione basata sullo splitter di Jeff Moden con modifiche minori per supportare stringhe più lunghe
Su SQLServerCentral, Jeff Moden ha presentato una funzione splitter che rivaleggiava con le prestazioni di CLR, quindi ho pensato che fosse giusto includere una variazione usando un approccio simile in questo riepilogo. Ho dovuto apportare alcune piccole modifiche alla sua funzione per gestire la nostra stringa più lunga (500.000 caratteri) e ho anche reso simili le convenzioni di denominazione:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Per inciso, per coloro che utilizzano la soluzione di Jeff Moden, potresti prendere in considerazione l'utilizzo di una tabella di numeri come sopra e sperimentare una leggera variazione sulla funzione di Jeff:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Questo scambierà letture leggermente più alte con una CPU leggermente inferiore, quindi potrebbe essere migliore a seconda che il tuo sistema sia già legato alla CPU o all'I/O.)
Controllo della sanità mentale
Per essere sicuri di essere sulla strada giusta, possiamo verificare che tutte e cinque le funzioni restituiscano i risultati attesi:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
E infatti, questi sono i risultati che vediamo in tutti e cinque i casi...

I dati del test
Ora che sappiamo che le funzioni si comportano come previsto, possiamo arrivare alla parte divertente:testare le prestazioni rispetto a vari numeri di stringhe che variano in lunghezza. Ma prima abbiamo bisogno di un tavolo. Ho creato il seguente semplice oggetto:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Ho popolato questa tabella con un insieme di stringhe di lunghezza variabile, assicurandomi che per ogni test venga utilizzato all'incirca lo stesso insieme di dati:prime 10.000 righe in cui la stringa è lunga 50 caratteri, quindi 1.000 righe in cui la stringa è lunga 500 caratteri , 100 righe in cui la stringa è lunga 5.000 caratteri, 10 righe in cui la stringa è lunga 50.000 caratteri e così via fino a 1 riga di 500.000 caratteri. L'ho fatto sia per confrontare la stessa quantità di dati complessivi elaborati dalle funzioni, sia per cercare di mantenere i miei tempi di test in qualche modo prevedibili.
Uso una tabella #temp in modo da poter semplicemente usare GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
La creazione e il popolamento di questa tabella ha richiesto circa 20 secondi sulla mia macchina e la tabella rappresenta circa 6 MB di dati (circa 500.000 caratteri per 2 byte o 1 MB per tipo_stringa, più riga e sovraccarico dell'indice). Non è una tabella enorme, ma dovrebbe essere abbastanza grande da evidenziare eventuali differenze di prestazioni tra le funzioni.
Le prove
Con le funzioni in atto e la tabella adeguatamente riempita con grandi stringhe su cui masticare, possiamo finalmente eseguire alcuni test effettivi per vedere come si comportano le diverse funzioni rispetto ai dati reali. Per misurare le prestazioni senza tener conto dell'overhead di rete, ho utilizzato SQL Sentry Plan Explorer, eseguendo ciascuna serie di test 10 volte, raccogliendo le metriche di durata e calcolando la media.
Il primo test ha semplicemente estratto gli elementi da ciascuna stringa come un set:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
I risultati mostrano che man mano che le corde diventano più grandi, il vantaggio di CLR brilla davvero. All'estremità inferiore, i risultati sono stati contrastanti, ma anche in questo caso il metodo XML dovrebbe avere un asterisco accanto, poiché il suo utilizzo dipende dall'utilizzo di input sicuri per XML. Per questo caso d'uso specifico, la tabella Numbers ha sempre ottenuto i risultati peggiori:
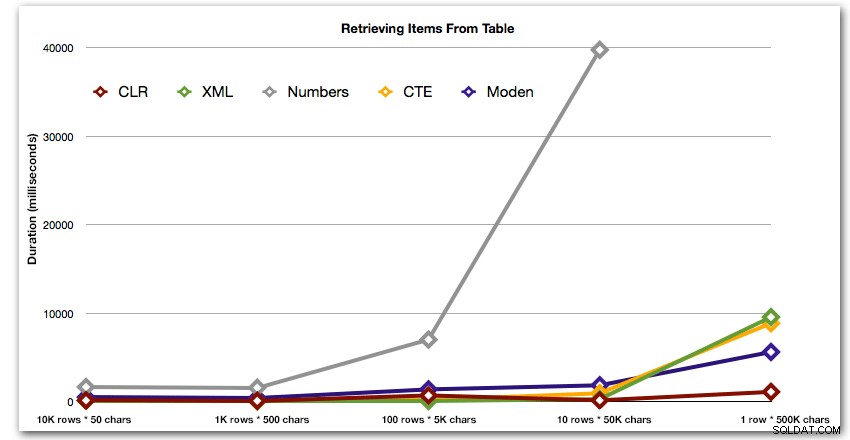
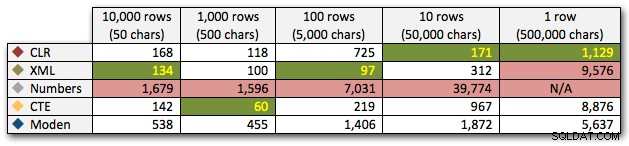
Durata, in millisecondi
Dopo la performance iperbolica di 40 secondi per la tabella dei numeri rispetto a 10 righe di 50.000 caratteri, l'ho eliminata dalla corsa per l'ultimo test. Per mostrare meglio le prestazioni relative dei quattro metodi migliori in questo test, ho eliminato del tutto i risultati di Numbers dal grafico:
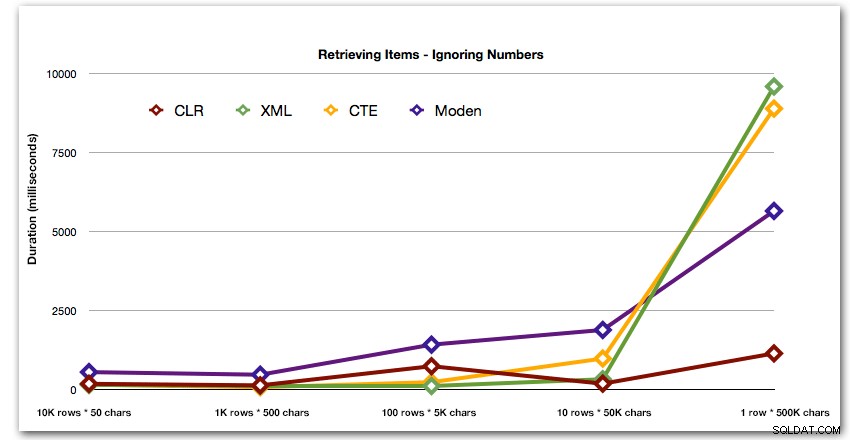
Quindi, confrontiamo quando eseguiamo una ricerca con il valore separato da virgole (ad es. Restituiamo le righe in cui una delle stringhe è 'foo'). Anche in questo caso utilizzeremo le cinque funzioni precedenti, ma confronteremo anche il risultato con una ricerca eseguita in fase di esecuzione utilizzando LIKE invece di occuparci della divisione.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Questi risultati mostrano che, per stringhe piccole, CLR era effettivamente il più lento e che la soluzione migliore sarebbe eseguire una scansione usando LIKE, senza preoccuparsi di dividere i dati. Ancora una volta ho abbandonato la soluzione della tabella dei numeri dal 5° approccio, quando era chiaro che la sua durata sarebbe aumentata esponenzialmente all'aumentare della dimensione della stringa:
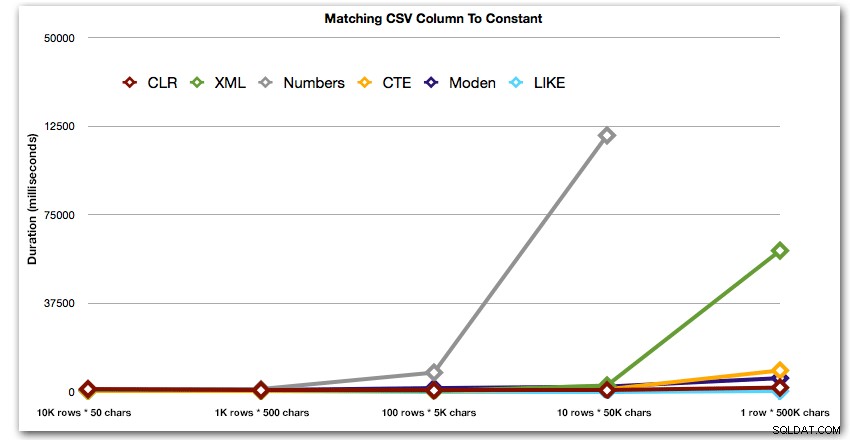
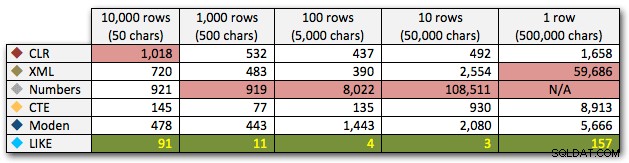
Durata, in millisecondi
E per dimostrare meglio i modelli per i primi 4 risultati, ho eliminato i numeri e le soluzioni XML dal grafico:
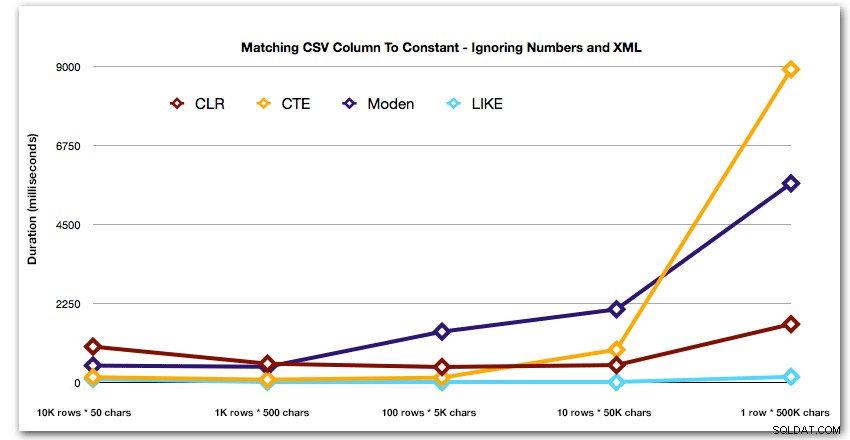
Quindi, diamo un'occhiata alla replica del caso d'uso dall'inizio di questo post, in cui stiamo cercando di trovare tutte le righe in una tabella che esistono nell'elenco che viene passato. Come con i dati nella tabella che abbiamo creato sopra, noi creeremo stringhe di lunghezza variabile da 50 a 500.000 caratteri, le memorizzeremo in una variabile e quindi verificheremo che una vista catalogo comune esista nell'elenco.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Questi risultati mostrano che, per questo modello, diversi metodi vedono la loro durata aumentare in modo esponenziale all'aumentare della dimensione della stringa. All'estremità inferiore, XML mantiene un buon ritmo con CLR, ma anche questo si deteriora rapidamente. CLR è costantemente il chiaro vincitore qui:
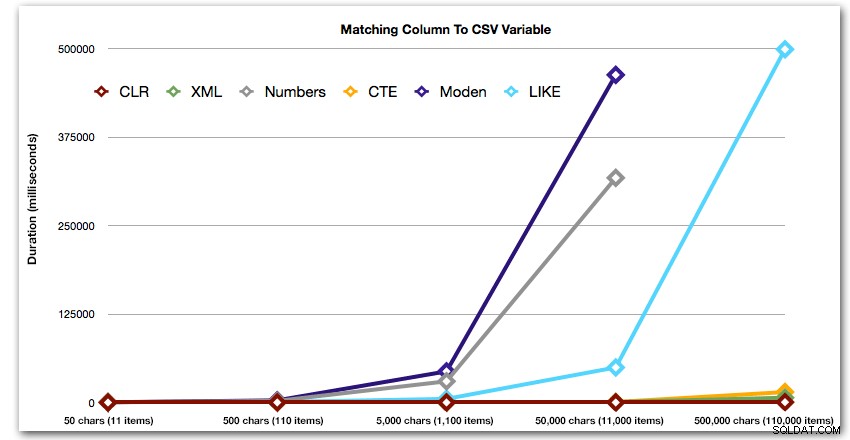
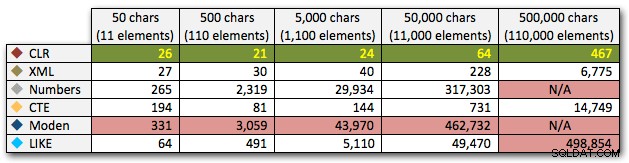
Durata, in millisecondi
E ancora senza i metodi che esplodono al rialzo in termini di durata:
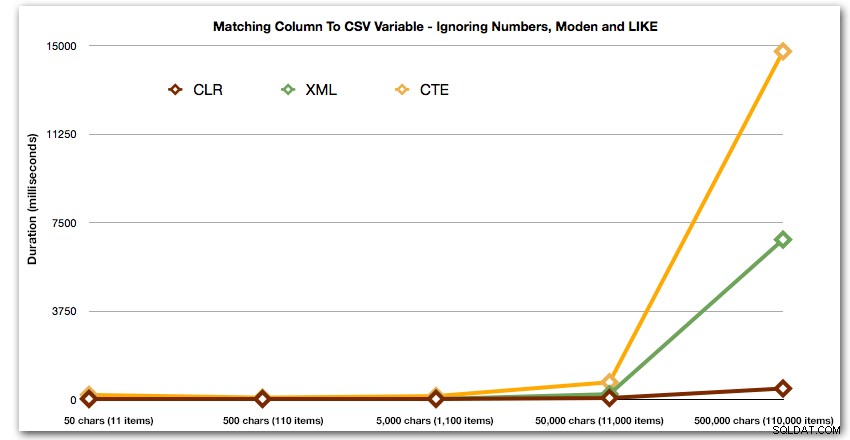
Infine, confrontiamo il costo del recupero dei dati da una singola variabile di lunghezza variabile, ignorando il costo della lettura dei dati da una tabella. Di nuovo genereremo stringhe di lunghezza variabile, da 50 a 500.000 caratteri, quindi restituiremo semplicemente i valori come un insieme:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Questi risultati mostrano anche che CLR è piuttosto fisso in termini di durata, fino a 110.000 elementi nel set, mentre gli altri metodi mantengono un ritmo decente fino a qualche tempo dopo 11.000 elementi:
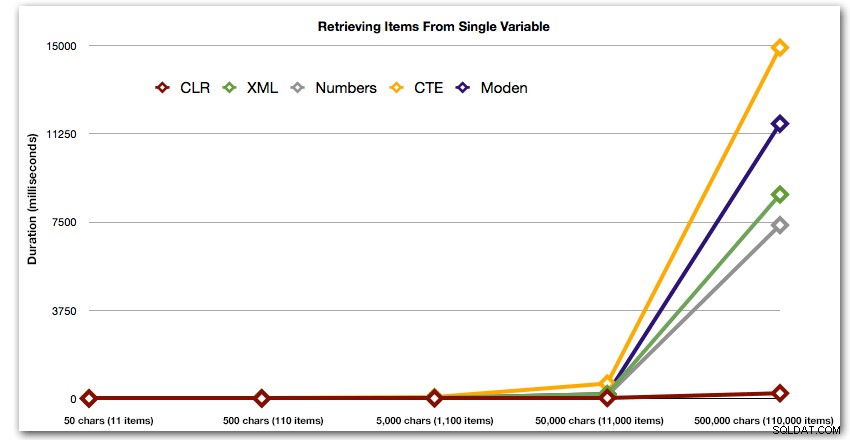
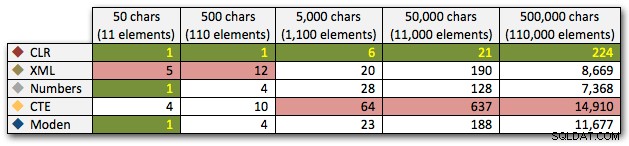
Durata, in millisecondi
Conclusione
In quasi tutti i casi, la soluzione CLR supera nettamente gli altri approcci:in alcuni casi è una vittoria schiacciante, soprattutto con l'aumento delle dimensioni delle corde; in pochi altri, è un fotofinish che potrebbe cadere in entrambi i casi. Nel primo test abbiamo visto che XML e CTE hanno superato CLR nella fascia bassa, quindi se questo è un caso d'uso tipico *e* sei sicuro che le tue stringhe siano comprese tra 1 e 10.000 caratteri, uno di questi approcci potrebbe essere un'opzione migliore. Se le dimensioni delle tue stringhe sono meno prevedibili di così, CLR è probabilmente ancora la soluzione migliore in assoluto:perdi alcuni millisecondi nella fascia bassa, ma guadagni molto nella fascia alta. Ecco le scelte che farei, a seconda dell'attività, con il secondo posto evidenziato per i casi in cui CLR non è un'opzione. Nota che XML è il mio metodo preferito solo se so che l'input è sicuro per XML; queste potrebbero non essere necessariamente le tue migliori alternative se hai meno fiducia nel tuo contributo.
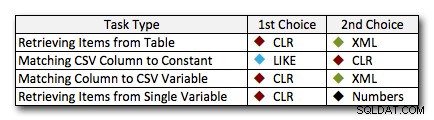
L'unica vera eccezione in cui CLR non è la mia scelta su tutta la linea è il caso in cui stai effettivamente archiviando elenchi separati da virgole in una tabella e quindi trovando righe in cui un'entità definita si trova in quell'elenco. In quel caso specifico, probabilmente consiglierei prima di riprogettare e normalizzare correttamente lo schema, in modo che quei valori siano archiviati separatamente, piuttosto che usarlo come scusa per non usare CLR per la divisione.
Se non puoi usare CLR per altri motivi, non c'è un chiaro "secondo posto" rivelato da questi test; le mie risposte sopra erano basate su una scala generale e non su una dimensione specifica della stringa. Ogni soluzione qui si è classificata seconda in almeno uno scenario, quindi mentre CLR è chiaramente la scelta quando puoi usarlo, ciò che dovresti usare quando non puoi è più una risposta "dipende" - dovrai giudicare in base a i tuoi casi d'uso e i test precedenti (o costruendo i tuoi test) quale alternativa è migliore per te.
Addendum:un'alternativa alla divisione in primo luogo
Gli approcci di cui sopra non richiedono modifiche alle tue applicazioni esistenti, supponendo che stiano già assemblando una stringa separata da virgole e lanciandola nel database da gestire. Un'opzione da considerare, se CLR non è un'opzione e/o è possibile modificare le applicazioni, è l'utilizzo dei parametri con valori di tabella (TVP). Ecco un rapido esempio di come utilizzare un TVP nel contesto sopra. Innanzitutto, crea un tipo di tabella con una singola colonna di stringa:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Quindi la procedura memorizzata può prendere questo TVP come input e unirsi al contenuto (o usarlo in altri modi - questo è solo un esempio):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Ora nel tuo codice C#, ad esempio, invece di creare una stringa separata da virgole, compila una DataTable (o usa qualsiasi raccolta compatibile potrebbe già contenere il tuo set di valori):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Potresti considerare questo come un prequel di un post successivo.
Ovviamente questo non funziona bene con JSON e altre API, molto spesso il motivo per cui una stringa separata da virgole viene passata in primo luogo a SQL Server.