Introduzione
In SQL Server 2012, l'aggregazione raggruppata (vettoriale) è stata in grado di usare l'esecuzione parallela in modalità batch, ma solo per l'aggregazione parziale (per thread). L'aggregato globale associato è sempre stato eseguito in modalità riga, dopo un Ripartizione flussi scambio.
SQL Server 2014 ha aggiunto la possibilità di eseguire l'aggregazione raggruppata in modalità batch parallela all'interno di un singolo Hash Match Aggregate operatore. Ciò ha eliminato l'elaborazione in modalità riga non necessaria e la necessità di uno scambio.
SQL Server 2016 ha introdotto l'elaborazione in modalità batch seriale e il download aggregato . Quando il pushdown ha esito positivo, l'aggregazione viene eseguita all'interno di Columnstore Scan operatore stesso, eventualmente operando direttamente su dati compressi, e sfruttando le istruzioni della CPU SIMD.
I miglioramenti delle prestazioni possibili con il pushdown aggregato possono essere molto sostanziali. La documentazione elenca alcune delle condizioni richieste per ottenere il pushdown, ma ci sono casi in cui la mancanza di "righe aggregate localmente" non può essere completamente spiegata solo da questi dettagli.
Questo articolo tratta ulteriori fattori che influiscono sul pushdown aggregato per GROUP BY solo query . Pushdown aggregato scalare (aggregazione senza un GROUP BY clausola), filtro pushdown e espressione pushdown potrebbero essere trattati in un post futuro.
Archiviazione del Columnstore
La prima cosa da dire è che il pushdown aggregato si applica solo ai dati compressi, quindi le righe in un archivio delta non sono ammissibili. Oltre a ciò, il pushdown può dipendere dal tipo di compressione utilizzata. Per capirlo, è necessario prima esaminare come funziona lo storage columnstore ad alto livello:
Un gruppo di righe compresso contiene un segmento di colonna per ogni colonna. I valori non elaborati della colonna sono codificati in un numero intero a 4 o 8 byte utilizzando valore o dizionario codifica.
Codifica del valore può ridurre il numero di bit necessari per l'archiviazione traducendo i valori grezzi utilizzando un offset di base e un modificatore di magnitudine. Ad esempio, i valori {1100, 1200, 1300} possono essere memorizzati come (0, 1, 2) scalando prima di un fattore 0,01 per dare {11, 12, 13}, quindi ribasando a 11 per dare {0, 1, 2}.
Codifica del dizionario viene utilizzato quando sono presenti valori duplicati. Può essere utilizzato con dati non numerici. Ogni valore univoco viene archiviato in un dizionario e gli viene assegnato un ID intero. I dati del segmento fanno quindi riferimento a numeri ID nel dizionario anziché ai valori originali.
Dopo la codifica, i dati del segmento possono essere ulteriormente compressi utilizzando la codifica run-length (RLE) e il bit-packing:
RLE sostituisce gli elementi ripetuti con i dati e il numero di ripetizioni, ad esempio {1, 1, 1, 1, 1, 2, 2, 2} potrebbero essere sostituiti con {5×1, 3×2}. Il risparmio di spazio RLE aumenta con la lunghezza delle corse ripetute. Le corse brevi possono essere controproducenti.
Imballaggio di bit memorizza la forma binaria dei dati in una finestra comune il più stretta possibile. Ad esempio, i numeri {7, 9, 15} sono archiviati in numeri interi binari (a byte singolo per spazio) come {00000111, 00001001, 00001111}. La compressione di questi bit in una finestra fissa a quattro bit dà al flusso {011110011111}. Sapere che esiste una dimensione fissa della finestra significa che non è necessario un delimitatore.
La codifica e la compressione sono passaggi separati, quindi RLE e il pacchetto di bit vengono applicati al risultato della codifica del valore o della codifica del dizionario dei dati grezzi. Inoltre, i dati all'interno dello stesso segmento di colonna possono avere una miscela di compressione RLE e bit-packing. I dati compressi con RLE sono chiamati puri e i dati compressi in bit sono chiamati impuri . Un segmento di colonna può contenere dati sia puri che impuri.
Il risparmio di spazio che si può ottenere attraverso la codifica e la compressione può dipendere dall'ordine. Tutti i segmenti di colonna all'interno di un gruppo di righe devono essere ordinati in modo implicito allo stesso modo in modo che SQL Server possa ricostruire in modo efficiente righe complete dai segmenti di colonna. Sapere che la riga 123 è memorizzata nella stessa posizione (123) in ogni segmento di colonna significa che il numero di riga non deve essere memorizzato.
Uno svantaggio di questa disposizione è che un ordinamento comune deve essere scelto per tutti i segmenti di colonna in un gruppo di righe. Un particolare ordinamento potrebbe adattarsi molto bene a una colonna, ma perdere opportunità significative in altre colonne. Questo è più chiaramente il caso della compressione RLE. SQL Server utilizza la tecnologia Vertipaq per determinare un buon modo di ordinare le colonne in ogni gruppo di righe per ottenere un buon risultato di compressione generale.
SQL Server attualmente utilizza solo RLE all'interno di un segmento di colonna quando è presente un minimo di 64 valori ripetuti contigui. I valori rimanenti nel segmento sono compressi in bit. Come notato, se i valori ripetuti appaiono come contigui in un segmento di colonna dipende dall'ordine scelto per il gruppo di righe.
SQL Server supporta SIMD specializzati spacchettamento dei bit per larghezze di bit da 1 a 10 inclusi, 12 e 21 bit. SQL Server può anche utilizzare dimensioni intere standard, ad es. 16, 32 e 64 bit con impacchettamento dei bit. Questi numeri sono scelti perché si adattano bene in un'unità a 64 bit. Ad esempio, un'unità può contenere tre subunità a 21 bit o 5 subunità a 12 bit. SQL Server non attraversare un limite di 64 bit quando si comprimono i bit.
SIMD utilizza registri a 256 bit quando il processore supporta le istruzioni AVX2 e registri a 128 bit quando sono disponibili le istruzioni SSE4.2. In caso contrario, è possibile utilizzare la decompressione non SIMD.
Condizioni pushdown aggregate raggruppate
La maggior parte dei piani con un Hash Match Aggregate operatore direttamente sopra un Columnstore Scan l'operatore si qualificherà potenzialmente per il pushdown aggregato raggruppato, fatte salve le condizioni generali riportate nella documentazione.
A volte è anche possibile aggiungere filtri ed espressioni extra senza impedire il pushdown aggregato raggruppato. La regola generale è che il filtro o l'espressione devono anche essere in grado di eseguire il pushdown (sebbene le espressioni compatibili possano ancora apparire in un Compute Scalar separato ). Come notato nell'introduzione, questi aspetti possono essere trattati in dettaglio in articoli separati.
Al momento non vi è nulla nei piani di esecuzione che indichi se un particolare aggregato fosse considerato generalmente compatibile con pushdown aggregati raggruppati o meno. Tuttavia, quando il piano generalmente si qualifica per il pushdown aggregato raggruppato, sono disponibili i percorsi di codice pushdown (veloce) e non pushdown (lento).
Ciascun batch di output della scansione (fino a 900 righe) prende una decisione di runtime tra i percorsi del codice veloce e lento. Questa flessibilità consente al maggior numero possibile di batch di beneficiare del pushdown. Nel peggiore dei casi, nessun batch utilizzerà il percorso rapido in fase di esecuzione, nonostante un piano "generalmente compatibile".
Il piano di esecuzione mostra il risultato dell'elaborazione pushdown con percorso rapido come "righe aggregate localmente" senza un output di riga corrispondente dalla scansione. I batch a percorso lento vengono visualizzati come righe di output dalla scansione columnstore come di consueto, con l'aggregazione eseguita da un operatore separato invece che durante la scansione.
Una singola combinazione di aggregazione e scansione raggruppata può inviare alcuni batch lungo il percorso veloce e alcuni lungo il percorso lento, quindi è perfettamente possibile vedere alcune, ma non tutte, le righe aggregate localmente. Quando il pushdown aggregato raggruppato ha esito positivo, ogni batch di output della scansione contiene chiavi di raggruppamento e un'aggregazione parziale che rappresenta le righe che contribuiscono.
Controlli dettagliati
Esistono numerosi controlli di runtime per determinare se è possibile utilizzare l'elaborazione pushdown. Tra i controlli poco documentati ci sono:
- Non deve esserci alcuna possibilità di overflow aggregato .
- Qualsiasi impuro (compresso in bit) chiavi di raggruppamento deve essere non più largo di 10 bit . Le chiavi di raggruppamento pure (codificate RLE) sono considerate aventi una larghezza impura pari a zero, quindi di solito presentano pochi ostacoli.
- L'elaborazione pushdown deve continuare a essere considerata utile , utilizzando una "misura del beneficio" aggiornata alla fine di ogni lotto di output.
La possibilità di overflow aggregato viene valutato in modo conservativo per ciascun batch in base al tipo di aggregato, al tipo di dati del risultato, ai valori di aggregazione parziale correnti e alle informazioni sui dati di input. Ad esempio, SQL Server conosce i valori minimo e massimo dei metadati del segmento come esposti in DMV sys.column_store_segments . In caso di rischio di overflow, il batch utilizzerà l'elaborazione del percorso lento. Questo è principalmente un rischio per il SUM aggregato.
La restrizione sulla larghezza della chiave di raggruppamento impuro vale la pena sottolineare. Si applica solo alle colonne nel GROUP BY clausole effettivamente utilizzate nel piano di esecuzione come base per il raggruppamento. Questi set non sono sempre esattamente gli stessi perché l'ottimizzatore ha la libertà di rimuovere le colonne di raggruppamento ridondanti o di riscrivere in altro modo gli aggregati, a condizione che i risultati finali della query corrispondano alla specifica della query originale. Laddove c'è una disparità, sono le colonne di raggruppamento mostrate nel piano di esecuzione che contano.
La difficoltà maggiore è sapere se una qualsiasi delle colonne di raggruppamento è memorizzata utilizzando il bit-packing e, in tal caso, quale larghezza è stata utilizzata. Sarebbe anche utile sapere quanti valori sono stati codificati utilizzando RLE. Queste informazioni potrebbero trovarsi nei column_store_segments DMV, ma oggi non è così. Per quanto ne so, al momento non esiste un modo documentato per ottenere il bit-packing e le informazioni RLE dai metadati. Questo ci lascia alla ricerca di alternative non documentate.
Trovare informazioni RLE e bit-packing
Il DBCC CSINDEX non documentato può darci le informazioni di cui abbiamo bisogno. Il flag di traccia 3604 deve essere attivo affinché questo comando produca output nella scheda dei messaggi SSMS. Date le informazioni sul segmento di colonna che ci interessa, questo comando restituisce:
- Attributi del segmento (simili a
column_store_segments) - Informazioni RLE
- Segnalibri nei dati RLE
- Informazioni sul pacchetto di bit
Non essendo documentato, ci sono alcune stranezze (come dover aggiungerne uno agli ID colonna per il columnstore cluster, ma non il columnstore non cluster) e persino un paio di errori minori. Non dovresti usarlo su nient'altro che un sistema di test personale. Si spera che un giorno verrà invece fornito un metodo supportato per accedere a questi dati.
Esempi
Il modo migliore per mostrare DBCC CSINDEX e dimostrare i punti fatti finora in questo testo è lavorare attraverso alcuni esempi. Gli script che seguono presuppongono che esista una tabella chiamata dbo.Numbers nel database corrente che contiene numeri interi da 1 ad almeno 16.384. Ecco uno script per creare la mia versione standard di questa tabella con dieci milioni di numeri interi:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Gli esempi utilizzano tutti la stessa tabella di test di base:la prima colonna c1 contiene un numero univoco per ogni riga. La seconda colonna c2 è popolato con un numero di duplicati per ciascuno di un piccolo numero di valori distinti.
Un indice columnstore cluster viene creato dopo il popolamento dei dati in modo che tutti i dati di test finiscano in un unico gruppo di righe compresso (nessun archivio delta). È costruito sostituendo un indice cluster b-tree sulla colonna c2 per incoraggiare l'algoritmo VertiPaq a considerare l'utilità dell'ordinamento su quella colonna all'inizio. Questa è la configurazione di base del test:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
Le due variabili riguardano il numero di valori distinti da inserire nella colonna c2 e il numero di duplicati per ciascuno di questi valori.
La query di test è un COUNT_BIG raggruppato molto semplice aggregazione utilizzando la colonna c2 come chiave:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Le informazioni sull'indice Columnstore verranno visualizzate utilizzando DBCC CSINDEX dopo ogni esecuzione di query di test:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); I test sono stati eseguiti sull'ultima versione rilasciata di SQL Server disponibile al momento della stesura:Microsoft SQL Server 2017 RTM-CU13-OD build 14.0.3049 Developer Edition (64 bit) su Windows 10 Pro. Le cose dovrebbero funzionare bene anche sull'ultima build di SQL Server 2016.
Test 1:pushdown, chiavi impure a 9 bit
Questo test utilizza lo script di popolamento dei dati di test esattamente come scritto sopra, producendo una tabella con 32.256 righe. Colonna c1 contiene numeri da 1 a 32.256.
Colonna c2 contiene 512 valori distinti da 0 a 511 compreso. Ogni valore in c2 è duplicato 63 volte , ma non appaiono come blocchi contigui se visualizzati in c1 ordine; ciclano 63 volte attraverso i valori da 0 a 511.
Data la discussione precedente, ci aspettiamo che SQL Server memorizzi il c2 dati di colonna utilizzando:
- Codifica del dizionario poiché esiste un numero significativo di valori duplicati.
- Nessun RLE . Il numero di duplicati (63) per valore non raggiunge la soglia di 64 richiesta per RLE.
- Imballaggio bit 9 . Le 512 voci distinte del dizionario si adatteranno esattamente a 9 bit (2^9 =512). Ciascuna unità a 64 bit conterrà fino a sette subunità a 9 bit.
Tutto ciò è confermato come corretto utilizzando il DBCC CSINDEX domanda:
Gli Attributi del segmento la sezione dell'output mostra la codifica del dizionario (digitare 2; i valori per encodingType sono come documentati in sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Conteggio righe =32256
La sezione RLE mostra nessun dato RLE , solo un puntatore all'area a compressione di bit e una voce vuota per il valore zero:
Intestazione RLE:
Tipo Lob =3 Conteggio array RLE (in termini di unità native) =2
Dimensione voce array RLE =8
Dati RLE:
Indice =0 Indice dell'array Bitpack =0 Conteggio =32256
Indice =1 Valore =0 Conteggio =0
L'intestazione dati Bitpack la sezione mostra la dimensione del pacchetto di bit 9 e 4.608 unità bitpack utilizzate:
Intestazione dati Bitpack:
Dimensione voce bitpack =9 Conteggio unità bitpack =4608 ID minimo bitpack =3
Dimensione dati bitpack =36864
I Dati del pacchetto di bit la sezione mostra i valori memorizzati nelle prime due unità bitpack come richiesto dagli ultimi due parametri al DBCC CSINDEX comando. Ricordiamo che ogni unità a 64 bit può contenere 7 subunità (numerate da 0 a 6) di 9 bit ciascuna (7 x 9 =63 bit). Le 4.608 unità in totale contengono 4.608 * 7 =32.256 righe:
Unità 0 Sottounità 0 =383
Unità 0 Sottounità 1 =255
Unità 0 Sottounità 2 =127
Unità 0 Sottounità 3 =510
Unità 0 Sottounità 4 =381
Unità 0 Sottounità 5 =253
Unità 0 Sottounità 6 =125
Unità 1 Sottounità 0 =508
Unità 1 Sottounità 1 =379
Unità 1 Sottounità 2 =251
Unità 1 Sottounità 3 =123
Unità 1 Sottounità 4 =506
Unità 1 Sottounità 5 =377
Unità 1 Sottounità 6 =249
Poiché le chiavi di raggruppamento utilizzano il packing di bit con una dimensione inferiore o uguale a 10 , ci aspettiamo un download aggregato raggruppato per lavorare qui. In effetti, il piano di esecuzione mostra che tutte le righe sono state aggregate localmente in Columnstore Index Scan operatore:

Il piano xml contiene ActualLocallyAggregatedRows="32256" nelle informazioni di runtime per la scansione dell'indice.
Test 2:nessun pushdown, chiavi impure a 12 bit
Questo test cambia il @values parametro a 1025, mantenendo @dupes a 63. Ciò fornisce una tabella di 64.575 righe, con 1.025 valori distinti nella colonna c2 da 0 a 1024 inclusi. Ogni valore in c2 è duplicato 63 volte .
SQL Server archivia il c2 dati di colonna utilizzando:
- Codifica del dizionario poiché esiste un numero significativo di valori duplicati.
- Nessun RLE . Il numero di duplicati (63) per valore non raggiunge la soglia di 64 richiesta per RLE.
- Un po' confezionato con la taglia 12 . Le 1.025 voci distinte del dizionario non si adatteranno perfettamente a 10 bit (2^10 =1.024). Si adatterebbero a 11 bit ma SQL Server non supporta la dimensione di compressione dei bit come menzionato in precedenza. La successiva dimensione più piccola è 12 bit. Utilizzando unità a 64 bit con bordi rigidi per il bit-packing, non è possibile inserire più subunità a 11 bit in 64 bit rispetto alle subunità a 12 bit. In ogni caso, 5 subunità si adatteranno a un'unità a 64 bit.
Il DBCC CSINDEX l'output conferma l'analisi di cui sopra:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Conteggio righe =64575
Intestazione RLE:
Tipo Lob =3 Conteggio array RLE (in termini di unità native) =2
Dimensione voce array RLE =8
Dati RLE:
Indice =0 Indice dell'array del pacchetto di bit =0 Conteggio =64575
Indice =1 Valore =0 Conteggio =0
Intestazione dati Bitpack:
Dimensione voce bitpack =12 Conteggio unità bitpack =12915 ID minimo bitpack =3
Dimensione dati bitpack =103320
Dati bitpack:
Unità 0 Sottounità 0 =767
Unità 0 Sottounità 1 =510
Unità 0 Sottounità 2 =254
Unità 0 Sottounità 3 =1021
Unità 0 Sottounità 4 =765
Unità 1 Sottounità 0 =507
Unità 1 Sottounità 1 =250
Unità 1 Sottounità 2 =1019
Unità 1 Sottounità 3 =761
Unità 1 Sottounità 4 =505
Dal momento che l'impuro le chiavi di raggruppamento hanno una dimensione superiore a 10 , ci aspettiamo un download aggregato raggruppato non lavorare qui. Ciò è confermato dal piano di esecuzione che mostra zero righe aggregate localmente nella Scansione dell'indice del Columnstore operatore:
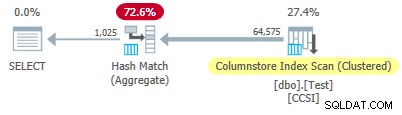
Tutte le 64.575 righe vengono emesse (in batch) da Columnstore Index Scan e aggregati in modalità batch dall'Hash Match Aggregate operatore. Le ActualLocallyAggregatedRows manca l'attributo dalle informazioni di runtime del piano xml per la scansione dell'indice.
Test 3:Pushdown, tasti puri
Questo test cambia il @dupes parametro da 63 a 64 per consentire RLE. I @values il parametro viene modificato in 16.384 (il numero massimo per il numero totale di righe per rientrare ancora in un singolo gruppo di righe). Il numero esatto scelto per @values non è importante:il punto è generare 64 duplicati di ciascun valore univoco in modo da poter utilizzare RLE.
SQL Server archivia il c2 dati di colonna utilizzando:
- Codifica del dizionario a causa dei valori duplicati.
- RLE. Utilizzato per ogni valore distinto poiché ciascuno soddisfa la soglia di 64.
- Nessun dato pieno di bit . Se ce ne fosse, userebbe la taglia 16. La taglia 12 non è abbastanza grande (2^12 =4.096 valori distinti) e la taglia 21 sarebbe uno spreco. I 16.384 valori distinti si adatterebbero a 14 bit ma, come prima, non più di questi possono essere inseriti in un'unità a 64 bit di subunità a 16 bit.
Il DBCC CSINDEX l'output conferma quanto sopra (solo alcune voci RLE e segnalibri mostrati per motivi di spazio):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Conteggio righe =1048576
Intestazione RLE:
Tipo Lob =3 Conteggio array RLE (in termini di unità native) =16385
Dimensione voce array RLE =8
Dati RLE:
Indice =0 Valore =3 Conteggio =64
Indice =1 Valore =1538 Conteggio =64
Indice =2 Valore =3072 Conteggio =64
Indice =3 Valore =4608 Conteggio =64
Indice =4 Valore =6142 Conteggio =64
…
Indice =16381 Valore =8954 Conteggio =64
Indice =16382 Valore =10489 Conteggio =64
Indice =16383 Valore =12025 Conteggio =64
Indice =16384 Valore =0 Conteggio =0
Intestazione segnalibro:
Conteggio segnalibro =65 Distanza segnalibro =16384 Dimensione segnalibro =520
Dati del segnalibro:
Posizione =0 Indice =64
Posizione =512 Indice =16448
Posizione =1024 Indice =32832
…
Posizione =31744 Indice =1015872
Posizione =32256 Indice =1032256
Posizione =32768 Indice =1048577
Intestazione dati Bitpack:
Dimensione voce bitpack =16 Conteggio unità bitpack =0 ID minimo bitpack =3
Dimensione dati bitpack =0
Poiché le chiavi di raggruppamento sono pure (viene utilizzato RLE), pushdown aggregato raggruppato è previsto qui. Il piano di esecuzione lo conferma mostrando tutte le righe aggregate localmente nella Scansione dell'indice del Columnstore operatore:
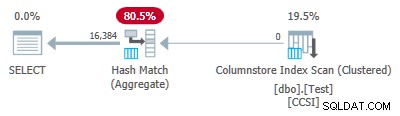
Il piano xml contiene ActualLocallyAggregatedRows="1048576" nelle informazioni di runtime per la scansione dell'indice.
Test 4:chiavi impure a 10 bit
Questo test imposta @values a 1024 e @dupes a 63, fornendo una tabella di 64.512 righe, con 1.024 valori distinti nella colonna c2 con valori da 0 a 1.023 inclusi. Ogni valore in c2 è duplicato 63 volte .
La cosa più importante , l'indice cluster b-tree è ora creato nella colonna c1 invece della colonna c2 . Il columnstore cluster continua a sostituire l'indice cluster b-tree. Questa è la parte modificata dello script:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server archivia il c2 dati di colonna utilizzando:
- Codifica del dizionario a causa dei duplicati.
- Nessun RLE . Il numero di duplicati (63) per valore non raggiunge la soglia di 64 richiesta per RLE.
- Confezione bit con taglia 10 . Le 1.024 voci distinte del dizionario si adattano esattamente a 10 bit (2^10 =1.024). È possibile memorizzare sei subunità di 10 bit ciascuna in ciascuna unità a 64 bit.
Il DBCC CSINDEX l'output è:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Conteggio righe =64512
Intestazione RLE:
Tipo Lob =3 Conteggio array RLE (in termini di unità native) =2
Dimensione voce array RLE =8
Dati RLE:
Indice =0 Indice dell'array del pacchetto di bit =0 Conteggio =64512
Indice =1 Valore =0 Conteggio =0
Intestazione dati Bitpack:
Dimensione voce bitpack =10 Conteggio unità bitpack =10752 ID minimo bitpack =3
Dimensione dati bitpack =86016
Dati bitpack:
Unità 0 Sottounità 0 =766
Unità 0 Sottounità 1 =509
Unità 0 Sottounità 2 =254
Unità 0 Sottounità 3 =1020
Unità 0 Sottounità 4 =764
Unità 0 Sottounità 5 =506
Unità 1 Sottounità 0 =250
Unità 1 Sottounità 1 =1018
Unità 1 Sottounità 2 =760
Unità 1 Sottounità 3 =504
Unità 1 Sottounità 4 =247
Unità 1 Sottounità 5 =1014
Dal momento che l'impuro le chiavi di raggruppamento utilizzano una dimensione minore o uguale a 10, ci aspetteremmo pushdown aggregati raggruppati per lavorare qui. Ma questo non è ciò che accade . Il piano di esecuzione mostra che 54.612 delle 64.512 righe sono state aggregate nell'Hash Match Aggregate operatore:
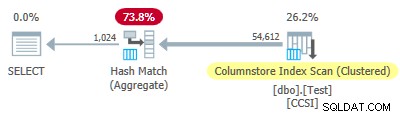
Il piano xml contiene ActualLocallyAggregatedRows="9900" nelle informazioni di runtime per la scansione dell'indice. Ciò significa pushdown aggregato raggruppato è stato utilizzato per 9.900 righe, ma non per le altre 54.612!
Il meccanismo di feedback
SQL Server ha iniziato utilizzando download aggregato raggruppato per questa esecuzione perché le chiavi di raggruppamento impure soddisfano i criteri di 10 bit o meno. Questo è durato per un totale di 11 batch (di 900 righe ciascuna =9.900 righe in totale). A quel punto, un meccanismo di feedback che misura l'efficacia del pushdown aggregato raggruppato ha deciso che non funzionava e l'ha disattivato . I batch rimanenti sono stati tutti elaborati con il pushdown disabilitato.
Il feedback essenzialmente confronta il numero di righe aggregate con il numero di gruppi prodotti. Inizia con un valore di 100 e viene regolato alla fine di ogni batch di output pushdown. Se il valore scende a 10 o meno, il pushdown è disabilitato per l'operazione di raggruppamento corrente.
La "misura del beneficio pushdown" viene ridotta più o meno a seconda di quanto sta andando male lo sforzo di aggregazione spinto verso il basso. Se nel batch di output sono presenti in media meno di 8 righe per chiave di raggruppamento, il valore del vantaggio corrente viene ridotto del 22%. Se sono presenti più di 8 ma meno di 16, la metrica viene ridotta dell'11%.
D'altra parte, se le cose migliorano e vengono successivamente rilevate 16 o più righe per chiave di raggruppamento per un batch di output, la metrica viene reimpostata su 100 e continua a essere modificata man mano che vengono prodotti batch aggregati parziali dalla scansione.
I dati in questo test sono stati presentati in un ordine particolarmente inutile per il pushdown a causa dell'indice cluster b-tree originale sulla colonna c1 . Se presentati in questo modo, i valori nella colonna c2 iniziano da 0 e aumentano di 1 fino a raggiungere 1.023, quindi ricominciano il ciclo. I 1.023 valori distinti sono più che sufficienti per garantire che ogni batch di output di 900 righe contenga solo una riga parzialmente aggregata per ogni chiave. Questo non è uno stato felice.
Se ci fossero stati 64 duplicati per valore invece di 63, SQL Server avrebbe preso in considerazione l'ordinamento per c2 durante la creazione dell'indice columnstore e così ha prodotto la compressione RLE. Così com'è, la penalità del 22% entra in gioco dopo ogni batch. A partire da 100 e utilizzando la stessa aritmetica intera arrotondata, la sequenza di valori metrici è:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
L'undicesimo batch riduce la metrica a 10 o meno e il pushdown è disabilitato. Gli 11 batch di 900 righe rappresentano le 9.900 righe aggregate localmente mostrate nel piano di esecuzione.
Variazione con 900 valori distinti
Lo stesso comportamento può essere visto nel test 4 con un minimo di 901 valori distinti, supponendo che le righe siano presentate nello stesso ordine inutile.
Modifica di @values parametro a 900 mantenendo tutto il resto uguale ha un effetto drammatico sul piano di esecuzione:
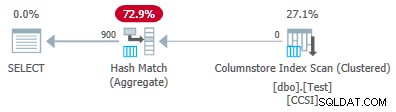
Ora tutti i 900 gruppi vengono aggregati alla scansione! Le proprietà del piano xml mostrano ActualLocallyAggregatedRows="56700" . Questo perché il pushdown aggregato raggruppato mantiene 900 chiavi di raggruppamento e aggregati parziali in un unico batch. It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Note: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.