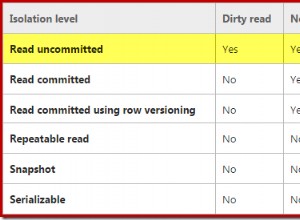
Praticamente tutti i problemi di prestazioni relativi alle colonne calcolate che ho riscontrato nel corso degli anni hanno avuto una (o più) delle seguenti cause principali:
- Limiti di implementazione
- Mancanza di supporto del modello di costo in Query Optimizer
- Espansione calcolata della definizione delle colonne prima dell'inizio dell'ottimizzazione
Un esempio di limite di implementazione non è in grado di creare un indice filtrato su una colonna calcolata (anche se persistente). Non c'è molto che possiamo fare per questa categoria di problemi; dobbiamo utilizzare soluzioni alternative mentre attendiamo l'arrivo dei miglioramenti del prodotto.
La mancanza del supporto del modello di costo dell'ottimizzatore significa che SQL Server assegna un piccolo costo fisso ai calcoli scalari, indipendentemente dalla complessità o dall'implementazione. Di conseguenza, il server decide spesso di ricalcolare un valore di colonna calcolato memorizzato invece di leggere direttamente il valore persistente o indicizzato. Ciò è particolarmente doloroso quando l'espressione calcolata è costosa, ad esempio quando implica la chiamata di una funzione scalare definita dall'utente.
I problemi relativi all'espansione della definizione sono un po' più coinvolti e hanno effetti ad ampio raggio.
I problemi dell'espansione calcolata delle colonne
SQL Server normalmente espande le colonne calcolate nelle definizioni sottostanti durante la fase di associazione della normalizzazione della query. Questa è una fase molto precoce nel processo di compilazione della query, molto prima che venga presa qualsiasi decisione sulla selezione del piano (incluso il piano banale).
In teoria, l'esecuzione di un'espansione anticipata potrebbe consentire ottimizzazioni che altrimenti sarebbero perse. Ad esempio, l'ottimizzatore potrebbe essere in grado di applicare semplificazioni date altre informazioni nella query e nei metadati (ad es. vincoli). Questo è lo stesso tipo di ragionamento che porta a visualizzare le definizioni che vengono espanse (a meno che un NOEXPAND viene utilizzato il suggerimento).
Più avanti nel processo di compilazione (ma ancora prima ancora che sia stato preso in considerazione un piano banale), l'ottimizzatore cerca di abbinare le espressioni a colonne calcolate persistenti o indicizzate. Il problema è che le attività di ottimizzazione nel frattempo potrebbero aver modificato le espressioni espanse in modo tale che non sia più possibile eseguire la corrispondenza.
Quando ciò si verifica, il piano di esecuzione finale sembra che l'ottimizzatore abbia perso un'opportunità "ovvia" di utilizzare una colonna calcolata persistente o indicizzata. Ci sono pochi dettagli nei piani di esecuzione che possono aiutare a determinare la causa, rendendo questo un problema potenzialmente frustrante per il debug e la risoluzione.
Abbinamento di espressioni a colonne calcolate
Vale la pena di essere particolarmente chiaro che ci sono due processi separati qui:
- Espansione anticipata delle colonne calcolate; e
- Successivamente tenta di abbinare le espressioni alle colonne calcolate.
In particolare, tieni presente che qualsiasi espressione di query può essere abbinata in seguito a una colonna calcolata adatta, non solo alle espressioni generate dall'espansione di colonne calcolate.
La corrispondenza calcolata delle espressioni di colonna può consentire miglioramenti del piano anche quando non è possibile modificare il testo della query originale. Ad esempio, la creazione di una colonna calcolata che corrisponda a un'espressione di query nota consente all'ottimizzatore di utilizzare statistiche e indici associati alla colonna calcolata. Questa funzionalità è concettualmente simile alla corrispondenza della vista indicizzata in Enterprise Edition. La corrispondenza calcolata delle colonne è funzionale in tutte le edizioni.
Da un punto di vista pratico, la mia esperienza personale è stata che la corrispondenza di espressioni di query generali con colonne calcolate può effettivamente avvantaggiare le prestazioni, l'efficienza e la stabilità del piano di esecuzione. D'altra parte, raramente (se mai) ho ritenuto utile l'espansione delle colonne calcolate. Sembra che non produca mai ottimizzazioni utili.
Usi delle colonne calcolate
Colonne calcolate che non sono nessuna delle due persistenti né indicizzati hanno usi validi. Ad esempio, possono supportare statistiche automatiche se la colonna è deterministica e precisa (nessun elemento a virgola mobile). Possono anche essere usati per risparmiare spazio di archiviazione (a scapito di un piccolo utilizzo extra del processore di runtime). Come ultimo esempio, possono fornire un modo accurato per garantire che un semplice calcolo venga sempre eseguito correttamente, invece di essere scritto esplicitamente nelle query ogni volta.
Persistito colonne calcolate sono state aggiunte al prodotto specificamente per consentire la creazione di indici su colonne deterministiche ma "imprecise" (virgola mobile). Nella mia esperienza, questo utilizzo previsto è relativamente raro. Forse è semplicemente perché non incontro molto i dati in virgola mobile.
Indici a virgola mobile a parte, le colonne persistenti sono piuttosto comuni. In una certa misura, ciò potrebbe essere dovuto al fatto che gli utenti inesperti presumono che una colonna calcolata debba sempre essere mantenuta prima di poter essere indicizzata. Gli utenti più esperti possono utilizzare colonne persistenti semplicemente perché hanno scoperto che le prestazioni tendono a essere migliori in questo modo.
Indicizzato colonne calcolate (persistenti o meno) possono essere utilizzate per fornire l'ordinamento e un metodo di accesso efficiente. Può essere utile memorizzare un valore calcolato in un indice senza mantenerlo anche nella tabella di base. Allo stesso modo, colonne calcolate adatte possono anche essere incluse negli indici anziché essere colonne chiave.
Prestazioni scarse
Una delle principali cause di scarso rendimento è un semplice errore nell'utilizzo di un valore di colonna calcolato indicizzato o persistente come previsto. Ho perso il conto del numero di domande che ho avuto nel corso degli anni chiedendo perché l'ottimizzatore avrebbe scelto un piano di esecuzione terribile quando esiste un piano ovviamente migliore che utilizza una colonna calcolata indicizzata o persistente.
La causa precisa in ogni caso varia, ma è quasi sempre una decisione errata basata sui costi (perché agli scalari viene assegnato un basso costo fisso); o la mancata corrispondenza di un'espressione espansa a una colonna oa un indice calcolato persistente.
I fallimenti del match-back sono particolarmente interessanti per me, perché spesso implicano interazioni complesse con le caratteristiche del motore ortogonale. Altrettanto spesso, la mancata "corrispondenza" lascia un'espressione (piuttosto che una colonna) in una posizione nell'albero delle query interno che impedisce la corrispondenza di un'importante regola di ottimizzazione. In entrambi i casi, il risultato è lo stesso:un piano di esecuzione non ottimale.
Ora, penso che sia giusto dire che le persone generalmente indicizzano o mantengono una colonna calcolata con la forte aspettativa che il valore memorizzato verrà effettivamente utilizzato. Può essere un vero shock vedere SQL Server ricalcolare ogni volta l'espressione sottostante, ignorando il valore memorizzato fornito deliberatamente. Le persone non sono sempre molto interessate alle interazioni interne e alle carenze del modello di costo che hanno portato al risultato indesiderabile. Anche laddove esistono soluzioni alternative, queste richiedono tempo, abilità e impegno per essere scoperte e testate.
In breve:molte persone preferirebbero semplicemente che SQL Server utilizzi il valore persistente o indicizzato. Sempre.
Una nuova opzione
Storicamente, non c'era modo di forzare SQL Server a utilizzare sempre il valore archiviato (nessun equivalente a NOEXPAND suggerimento per le visualizzazioni). Ci sono alcune circostanze in cui una guida del piano funzionerà, ma non è sempre possibile generare in primo luogo la forma del piano richiesta e non tutti gli elementi e le posizioni del piano possono essere forzati (filtri e calcolo scalari, ad esempio).
Non esiste ancora una soluzione chiara e completamente documentata, ma un recente aggiornamento di SQL Server 2016 ha fornito un nuovo approccio interessante. Si applica alle istanze di SQL Server 2016 corrette con almeno l'aggiornamento cumulativo 2 per SQL Server 2016 SP1 o l'aggiornamento cumulativo 4 per SQL Server 2016 RTM.
L'aggiornamento pertinente è documentato in:FIX:impossibile ricostruire la partizione online per una tabella che contiene una colonna di partizionamento calcolata in SQL Server 2016
Come spesso accade con la documentazione di supporto, questo non dice esattamente cosa è stato modificato nel motore per risolvere il problema. Certamente non sembra terribilmente rilevante per le nostre attuali preoccupazioni, a giudicare dal titolo e dalla descrizione. Tuttavia, questa correzione introduce un nuovo flag di traccia supportato 176 , che viene verificato in un metodo di codice chiamato FDontExpandPersistedCC . Come suggerisce il nome del metodo, ciò impedisce l'espansione di una colonna calcolata persistente.
Ci sono tre avvertimenti importanti a questo:
- La colonna calcolata deve essere persistente . Anche se indicizzata, anche la colonna deve essere resa persistente.
- La corrispondenza tra le espressioni di query generali e le colonne calcolate persistenti è disabilitata .
- La documentazione non descrive la funzione del flag di traccia e non lo prescrive per nessun altro uso. Se scegli di utilizzare il flag di traccia 176 per impedire l'espansione delle colonne calcolate persistenti, sarà quindi a tuo rischio.
Questo flag di traccia è efficace come –T di avvio opzione, sia a livello globale che di sessione utilizzando DBCC TRACEON e per query con OPTION (QUERYTRACEON) .
Esempio
Questa è una versione semplificata di una domanda (basata su un problema del mondo reale) a cui ho risposto su Database Administrators Stack Exchange alcuni anni fa. La definizione della tabella include una colonna calcolata persistente:
CREATE TABLE dbo.T
(
ID integer IDENTITY NOT NULL,
A varchar(20) NOT NULL,
B varchar(20) NOT NULL,
C varchar(20) NOT NULL,
D date NULL,
Computed AS A + '-' + B + '-' + C PERSISTED,
CONSTRAINT PK_T_ID
PRIMARY KEY CLUSTERED (ID),
);
GO
INSERT dbo.T WITH (TABLOCKX)
(A, B, C, D)
SELECT
A = STR(SV.number % 10, 2),
B = STR(SV.number % 20, 2),
C = STR(SV.number % 30, 2),
D = DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())
FROM master.dbo.spt_values AS SV
WHERE SV.[type] = N'P'; La query seguente restituisce tutte le righe della tabella in un ordine particolare, restituendo anche il valore successivo della colonna D nello stesso ordine:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D; Un ovvio indice di copertura per supportare l'ordinamento finale e le ricerche nella sottoquery è:
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
Il piano di esecuzione fornito dall'ottimizzatore è sorprendente e deludente:
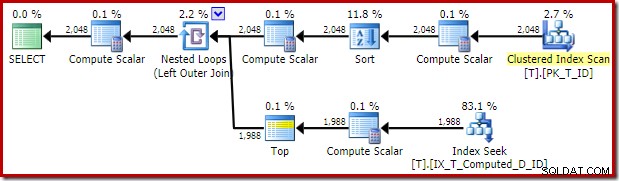
L'Index Seek sul lato interno del Nested Loops Join sembra essere tutto a posto. La scansione e l'ordinamento dell'indice raggruppato sull'input esterno, tuttavia, sono imprevisti. Avremmo invece sperato di vedere una scansione ordinata del nostro indice non cluster di copertura.
Possiamo forzare l'ottimizzatore a utilizzare l'indice non cluster con un suggerimento per la tabella:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
WITH (INDEX(IX_T_Computed_D_ID)) -- New!
ORDER BY
T1.Computed, T1.D; Il piano di esecuzione risultante è:
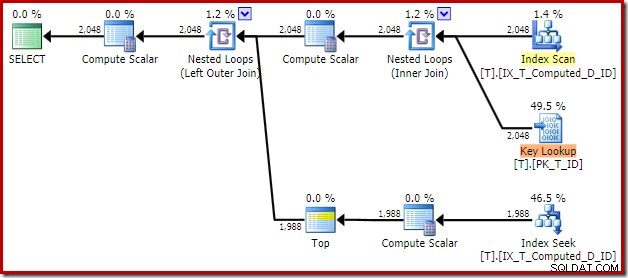
La scansione dell'indice non cluster rimuove l'ordinamento, ma aggiunge una ricerca chiave! Le ricerche in questo nuovo piano sono sorprendenti, dato che il nostro indice copre definitivamente tutte le colonne necessarie per la query.
Osservando le proprietà dell'operatore Key Lookup:
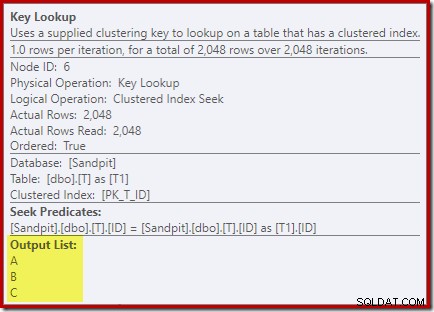
Per qualche ragione, l'ottimizzatore ha deciso che tre colonne non menzionate nella query devono essere recuperate dalla tabella di base (poiché non sono presenti nel nostro indice non cluster in base alla progettazione).
Osservando il piano di esecuzione, scopriamo che le colonne cercate sono necessarie per il lato interno di Index Seek:

La prima parte di questo predicato di ricerca corrisponde alla correlazione T2.Computed = T1.Computed nella query originale. L'ottimizzatore ha ampliato le definizioni di entrambe le colonne calcolate, ma è riuscito a far corrispondere solo la colonna calcolata persistente e indicizzata per l'alias lato interno T1 . Lasciando il T2 il riferimento espanso ha portato il lato esterno del join a dover fornire le colonne della tabella di base (A , B e C ) necessario per calcolare quell'espressione per ogni riga.
Come a volte accade, è possibile riscrivere questa query in modo che il problema scompaia (un'opzione è mostrata nella mia vecchia risposta alla domanda di Stack Exchange). Utilizzando SQL Server 2016, possiamo anche provare il flag di traccia 176 per impedire che le colonne calcolate vengano espanse:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D
OPTION (QUERYTRACEON 176); -- New! Il piano di esecuzione è ora molto migliorato:
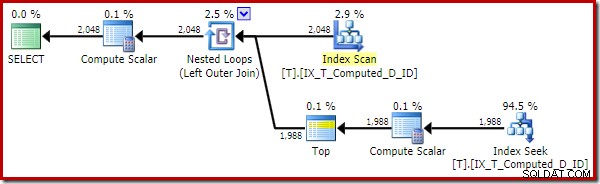
Questo piano di esecuzione contiene solo riferimenti alle colonne calcolate. I Compute Scalar non fanno nulla di utile e verrebbero ripuliti se l'ottimizzatore fosse un po' più ordinato in casa.
Il punto importante è che l'indice ottimale è ora utilizzato correttamente e che l'ordinamento e la ricerca chiave sono stati eliminati. Il tutto impedendo a SQL Server di fare qualcosa che non ci saremmo mai aspettati che facesse in primo luogo (l'espansione di una colonna calcolata persistente e indicizzata).
Utilizzo di LEAD
La domanda originale di Stack Exchange era mirata a SQL Server 2008, dove LEAD Non è disponibile. Proviamo a esprimere il requisito su SQL Server 2016 utilizzando la sintassi più recente:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed; Il piano di esecuzione di SQL Server 2016 è:
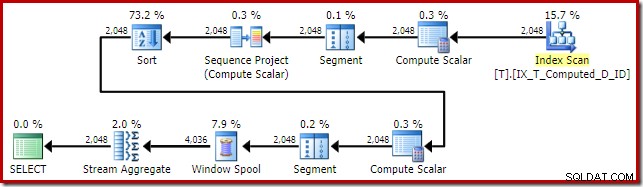
Questa forma del piano è abbastanza tipica per una semplice funzione di finestra in modalità riga. L'unico elemento imprevisto è l'operatore di ordinamento nel mezzo. Se il set di dati fosse di grandi dimensioni, questo ordinamento potrebbe avere un grande impatto sulle prestazioni e sull'utilizzo della memoria.
Il problema, ancora una volta, è l'espansione calcolata delle colonne. In questo caso, una delle espressioni espanse si trova in una posizione che impedisce la normale logica dell'ottimizzatore semplificando l'ordinamento.
Provare esattamente la stessa query con il flag di traccia 176:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed
OPTION (QUERYTRACEON 176); Produce il piano:
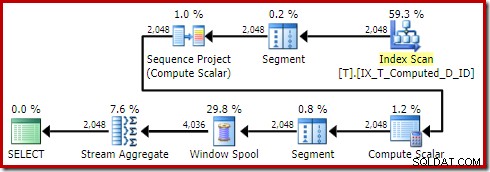
Il Sort è scomparso come dovrebbe. Nota anche di passaggio che questa query si qualificava per un piano banale, evitando del tutto l'ottimizzazione basata sui costi.
Corrispondenza espressioni generali disabilitata
Uno degli avvertimenti menzionati in precedenza era che il flag di traccia 176 disabilita anche la corrispondenza dalle espressioni nella query di origine alle colonne calcolate persistenti.
Per illustrare, si consideri la seguente versione della query di esempio. Il LEAD il calcolo è stato rimosso e i riferimenti alla colonna calcolata in SELECT e ORDER BY le clausole sono state sostituite con le espressioni sottostanti. Eseguilo prima senza il flag di traccia 176:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C; Le espressioni vengono abbinate alla colonna calcolata persistente e il piano di esecuzione è una semplice scansione ordinata dell'indice non cluster:
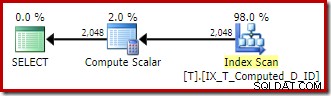
Il Compute Scalar è ancora una volta solo spazzatura architettonica avanzata.
Ora prova la stessa query con il flag di traccia 176 abilitato:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); -- New! Il nuovo piano di esecuzione è:
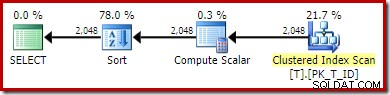
La scansione dell'indice non in cluster è stata sostituita con una scansione dell'indice in cluster. Compute Scalar valuta l'espressione e Ordina in base al risultato. Privato della capacità di abbinare le espressioni alle colonne calcolate persistenti, l'ottimizzatore non può utilizzare il valore persistente o l'indice non cluster.
Tieni presente che la limitazione della corrispondenza delle espressioni si applica solo a persistente colonne calcolate quando il flag di traccia 176 è attivo. Se rendiamo la colonna calcolata indicizzata ma non persistente, la corrispondenza delle espressioni funziona correttamente.
Per eliminare l'attributo persistente, dobbiamo prima eliminare l'indice non cluster. Una volta apportata la modifica, possiamo riportare l'indice direttamente indietro (perché l'espressione è deterministica e precisa):
DROP INDEX IX_T_Computed_D_ID ON dbo.T; GO ALTER TABLE dbo.T ALTER COLUMN Computed DROP PERSISTED; GO CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
L'ottimizzatore ora non ha problemi a far corrispondere l'espressione della query alla colonna calcolata quando il flag di traccia 176 è attivo:
-- Computed column no longer persisted
-- but still indexed. TF 176 active.
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); Il piano di esecuzione torna alla scansione dell'indice non cluster ottimale senza un ordinamento:
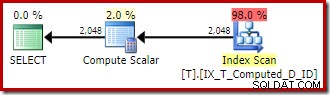
Per riassumere:il flag di traccia 176 impedisce l'espansione continua della colonna calcolata. Come effetto collaterale, impedisce anche la corrispondenza delle espressioni di query solo alle colonne calcolate persistenti.
I metadati dello schema vengono caricati una sola volta, durante la fase di associazione. Il flag di traccia 176 impedisce l'espansione in modo che la definizione di colonna calcolata non venga caricata in quel momento. La successiva corrispondenza tra espressione e colonna non può funzionare senza la definizione di colonna calcolata con cui eseguire la corrispondenza.
Il caricamento iniziale dei metadati include tutte le colonne, non solo quelle a cui si fa riferimento nella query (l'ottimizzazione viene eseguita in seguito). Ciò rende tutte le colonne calcolate disponibili per la corrispondenza, il che è generalmente una buona cosa. Sfortunatamente, se una delle colonne calcolate caricate contiene una funzione scalare definita dall'utente, la sua presenza disabilita il parallelismo per l'intera query anche quando la colonna problematica non viene utilizzata. Anche il flag di traccia 176 può aiutare in questo, se la colonna in questione è persistente. Non caricando la definizione, una funzione scalare definita dall'utente non è mai presente, quindi il parallelismo non è disabilitato.
Pensieri finali
Mi sembra che il mondo di SQL Server sia un posto migliore se l'ottimizzatore trattasse colonne calcolate persistenti o indicizzate più come colonne normali. In quasi tutti i casi, questo corrisponderebbe meglio alle aspettative degli sviluppatori rispetto all'attuale accordo. L'espansione delle colonne calcolate nelle loro espressioni sottostanti e il successivo tentativo di associarle non è un successo nella pratica come potrebbe suggerire la teoria.
Fino a quando SQL Server non fornisce un supporto specifico per impedire l'espansione delle colonne calcolate persistenti o indicizzate, il nuovo flag di traccia 176 è un'opzione allettante per gli utenti di SQL Server 2016, anche se imperfetta. È un po' sfortunato che disabiliti la corrispondenza delle espressioni generali come effetto collaterale. È anche un peccato che la colonna calcolata debba essere mantenuta durante l'indicizzazione. Esiste quindi il rischio di utilizzare un flag di traccia per scopi diversi da quelli documentati da considerare.
È corretto affermare che la maggior parte dei problemi con le query di colonna calcolate può essere risolta in definitiva in altri modi, con tempo, impegno e competenza sufficienti. D'altra parte, il flag di traccia 176 sembra spesso funzionare come per magia. La scelta, come si suol dire, è tua.
Per finire, ecco alcuni interessanti problemi di colonne calcolate che beneficiano del flag di traccia 176:
- Indice colonna calcolato non utilizzato
- Colonna calcolata PERSISTED non utilizzata nel partizionamento delle funzioni di windowing
- Colonna calcolata persistente che causa la scansione
- Indice colonna calcolato non utilizzato con i tipi di dati MAX
- Grave problema di prestazioni con colonne e join calcolati persistenti
- Perché SQL Server "calcola scalare" quando SELEZIONO una colonna calcolata persistente?
- Colonne di base utilizzate al posto delle colonne calcolate persistenti dal motore
- La colonna calcolata con UDF disabilita il parallelismo per le query su *altre* colonne