@rob_farley la tua recente soluzione di stackoverflow per ordinare prima un valore poi un campo è genio! Volevo ringraziarti personalmente.
— Joel Sacco (@Jsac90) 11 agosto 2016
Ho visto questo tweet arrivare...
E mi ha fatto guardare a cosa si riferiva, perché non avevo scritto nulla "di recente" su StackOverflow sull'ordinazione dei dati. Si scopre che era questa risposta che avevo scritto , che pur non essendo stata la risposta accettata, ha raccolto oltre cento voti.
La persona che ha posto la domanda ha avuto un problema molto semplice:desiderare che alcune righe appaiano per prime. E la mia soluzione era semplice:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Sembra sia stata una risposta popolare, anche per Joel Sacco (secondo quel tweet sopra).
L'idea è di formare un'espressione, e ordinare in base a quella. ORDER BY non importa se si tratta di una colonna effettiva o meno. Avresti potuto fare lo stesso usando APPLY, se davvero preferisci usare una "colonna" nella tua clausola ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Se utilizzo alcune query su WideWorldImporters, posso mostrarti perché queste due query sono davvero esattamente le stesse. Interrogherò la tabella Sales.Orders, chiedendo che venga visualizzato per primo Orders for Salesperson 7. Creerò anche un indice di copertura appropriato:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
I piani per queste due query sembrano identici. Funzionano in modo identico:stesse letture, stesse espressioni, sono davvero la stessa query. Se c'è una leggera differenza nella CPU o nella durata effettiva, è un caso a causa di altri fattori.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
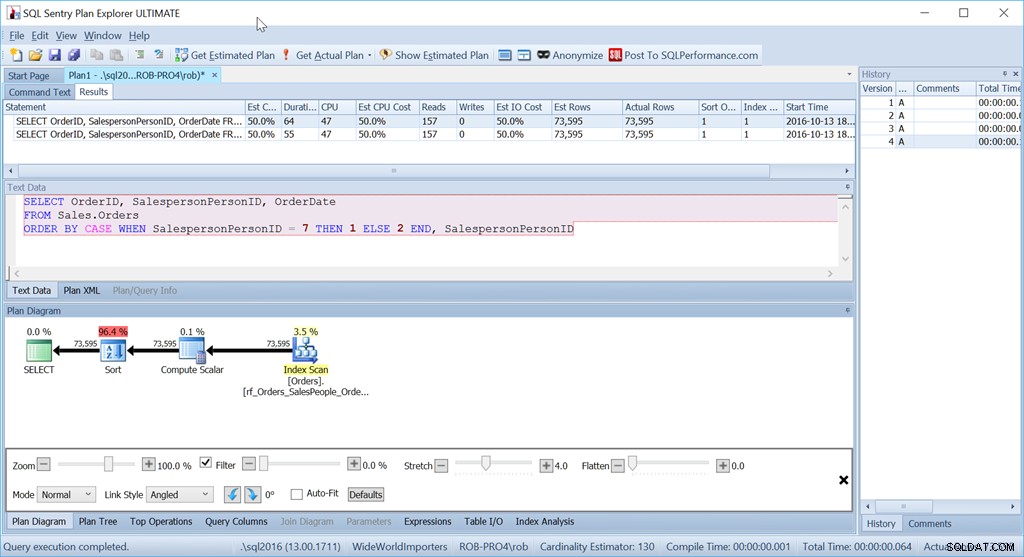
Eppure questa non è la query che userei effettivamente in questa situazione. Non se le prestazioni fossero importanti per me. (Di solito lo è, ma non sempre vale la pena scrivere una query a lungo se la quantità di dati è piccola.)
Quello che mi infastidisce è quell'operatore di ordinamento. È il 96,4% del costo!
Considera se vogliamo semplicemente ordinare per SalespersonPersonID:
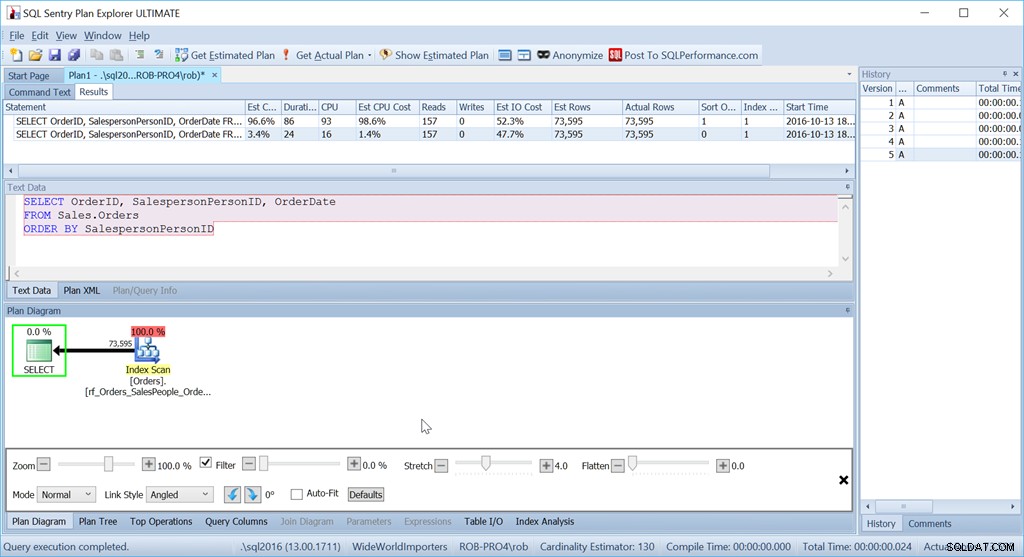
Vediamo che il costo stimato della CPU di questa query più semplice è dell'1,4% del batch, mentre la versione con ordinamento personalizzato è del 98,6%. Questo è SETTANTA VOLTE peggio. Le letture sono le stesse però – va bene. La durata è decisamente peggiore, così come la CPU.
Non mi piacciono i tipi. Possono essere cattivi.
Un'opzione che ho qui è quella di aggiungere una colonna calcolata alla mia tabella e indicizzarla, ma ciò avrà un impatto su tutto ciò che cerca tutte le colonne della tabella, come ORM, Power BI o qualsiasi cosa SELECT * . Quindi non è così eccezionale (sebbene se dovessimo mai aggiungere colonne calcolate nascoste, sarebbe un'opzione davvero interessante qui).
Un'altra opzione, che è più prolissa (alcuni potrebbero suggerire che sarebbe adatto a me - e se lo pensassi:Oi! Non essere così scortese!), e utilizza più letture, è considerare cosa faremmo nella vita reale se dovevamo farlo.
Se avessi una pila di 73.595 ordini, ordinati per ordine del venditore, e dovessi prima restituirli con un particolare venditore, non ignorerei l'ordine in cui si trovavano e li ordinerei semplicemente tutti, inizierei immergendomi e trovando quelli per il venditore 7 – mantenendoli nell'ordine in cui si trovavano. Poi avrei trovato quelli che non erano quelli che non erano quelli che non erano il venditore 7 – mettendoli dopo, e di nuovo mantenendoli nell'ordine in cui erano già dentro.
In T-SQL, è fatto in questo modo:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Questo ottiene due set di dati e li concatena. Ma Query Optimizer può vedere che deve mantenere l'ordine SalespersonPersonID, una volta che i due set sono concatenati, quindi esegue un tipo speciale di concatenazione che mantiene quell'ordine. È un join di unione (concatenazione) e il piano è simile al seguente:
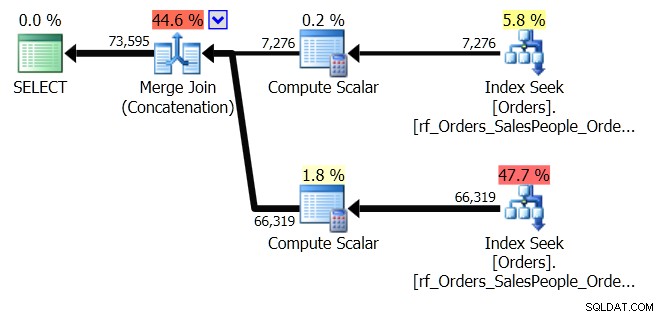
Puoi vedere che è molto più complicato. Ma si spera che noterai anche che non esiste un operatore di ordinamento. Il Merge Join (Concatenazione) estrae i dati da ciascun ramo e produce un set di dati nell'ordine corretto. In questo caso, estrarrà prima tutte le 7.276 righe per il venditore 7, quindi le altre 66.319, perché questo è l'ordine richiesto. All'interno di ogni set, i dati sono nell'ordine SalespersonPersonID, che viene mantenuto durante il flusso dei dati.
Ho detto prima che usa più letture e lo fa. Se mostro l'output SET STATISTICS IO, confrontando le due query, vedo questo:
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.Tabella 'Ordini'. Conteggio scansioni 1, letture logiche 157, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Ordini '. Conteggio scansioni 3, letture logiche 163, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Utilizzando la versione "Ordinamento personalizzato", è solo una scansione dell'indice, utilizzando 157 letture. Utilizzando il metodo "Union All", sono tre scansioni:una per SalespersonPersonID =7, una per SalespersonPersonID <7 e una per SalespersonPersonID> 7. Possiamo vedere queste ultime due osservando le proprietà del secondo Index Seek:
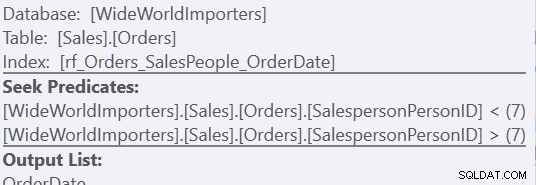
Per me, però, il vantaggio deriva dalla mancanza di un tavolo da lavoro.
Guarda il costo stimato della CPU:

Non è piccolo come il nostro 1,4% quando evitiamo completamente l'ordinamento, ma è comunque un grande miglioramento rispetto al nostro metodo di ordinamento personalizzato.
Ma un avvertimento...
Supponiamo di aver creato quell'indice in modo diverso e di avere OrderDate come colonna chiave anziché come colonna inclusa.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Ora, il mio metodo "Union All" non funziona affatto come previsto.
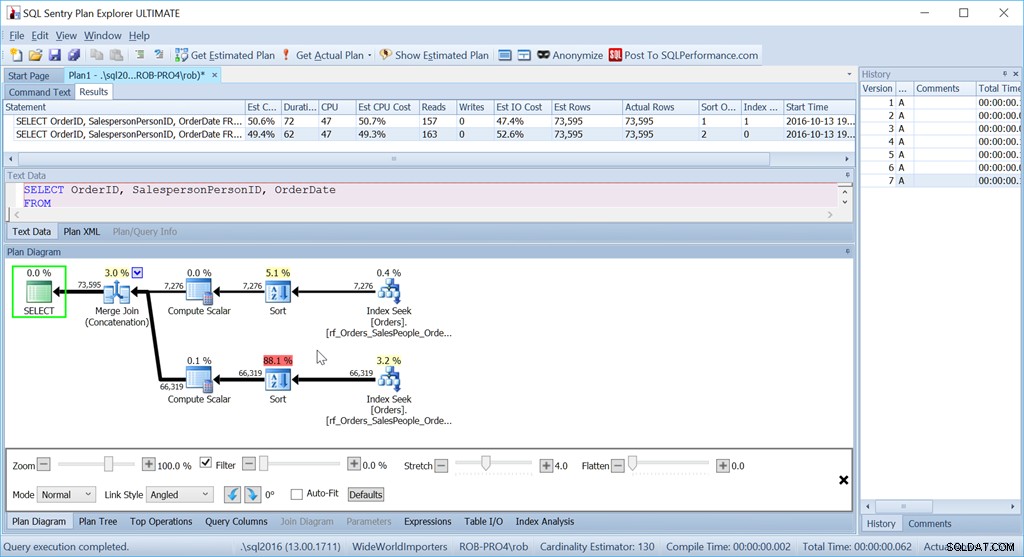
Nonostante utilizzi esattamente le stesse query di prima, il mio bel piano ora ha due operatori di ordinamento e funziona quasi quanto la mia versione originale Scan + Sort.
La ragione di ciò è una stranezza dell'operatore Merge Join (Concatenation) e l'indizio è nell'operatore Sort.

Sta ordinando per SalespersonPersonID seguito da OrderID, che è la chiave di indice cluster della tabella. Lo sceglie perché è noto che è univoco ed è un insieme più piccolo di colonne da ordinare rispetto a SalespersonPersonID seguito da OrderDate seguito da OrderID, che è l'ordine del set di dati prodotto da tre scansioni di intervalli di indici. Una di quelle volte in cui Query Optimizer non nota un'opzione migliore che è proprio lì.
Con questo indice, avremmo bisogno anche del nostro set di dati ordinato da OrderDate per produrre il nostro piano preferito.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
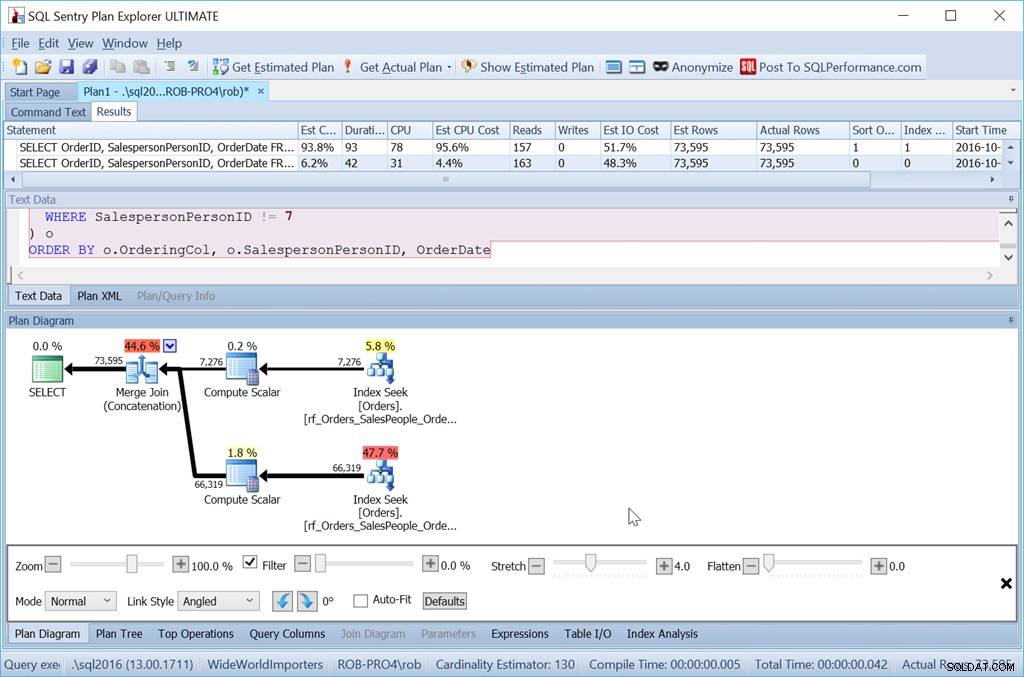
Quindi è sicuramente uno sforzo maggiore. La query è più lunga per me da scrivere, è più letture e devo avere un indice senza colonne chiave aggiuntive. Ma è sicuramente più veloce. Con ancora più righe, l'impatto è ancora maggiore e non devo nemmeno rischiare che un Sort si riversi su tempdb.
Per piccoli set, la mia risposta StackOverflow è ancora buona. Ma quando quell'operatore di ordinamento mi costa in termini di prestazioni, allora scelgo il metodo Union All / Merge Join (Concatenation).