La scorsa settimana ho pubblicato un post chiamato #BackToBasics :DATEFROMPARTS() , dove ho mostrato come utilizzare questa funzione 2012+ per query di intervalli di date più pulite e modificabili. L'ho usato per dimostrare che se si utilizza un predicato di data aperto e si dispone di un indice nella colonna data/ora pertinente, è possibile ottenere un utilizzo dell'indice molto migliore e un I/O inferiore (o, nel peggiore dei casi , lo stesso, se una ricerca non può essere utilizzata per qualche motivo, o se non esiste un indice adatto):
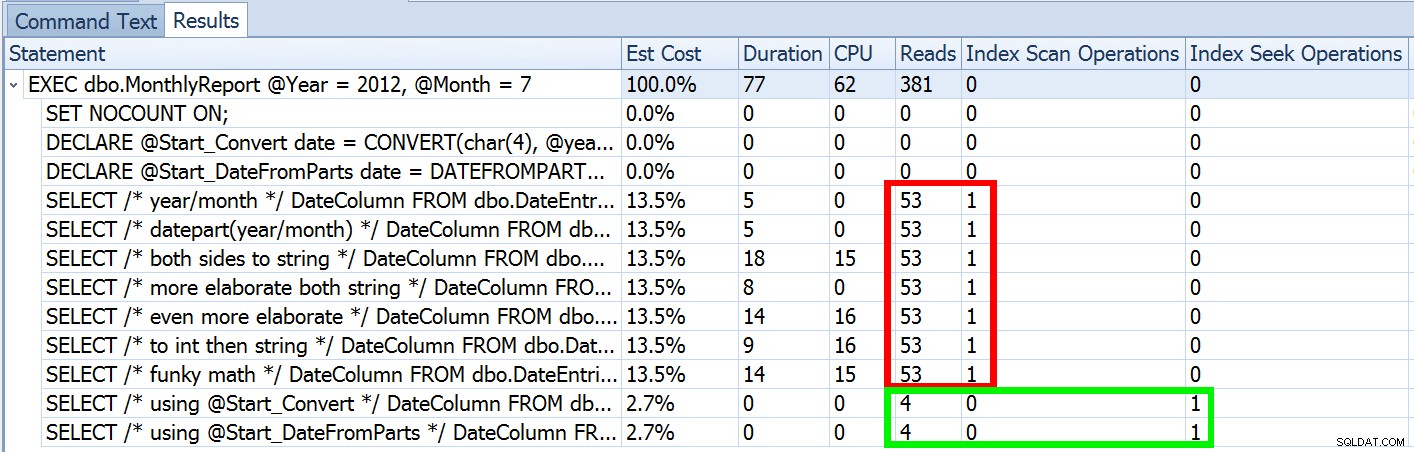
Ma questa è solo una parte della storia (e per essere chiari, DATEFROMPARTS() non è tecnicamente richiesto per ottenere una ricerca, è solo più pulito in quel caso). Se rimpiccioliamo un po', notiamo che le nostre stime sono tutt'altro che accurate, una complessità che non volevo introdurre nel post precedente:
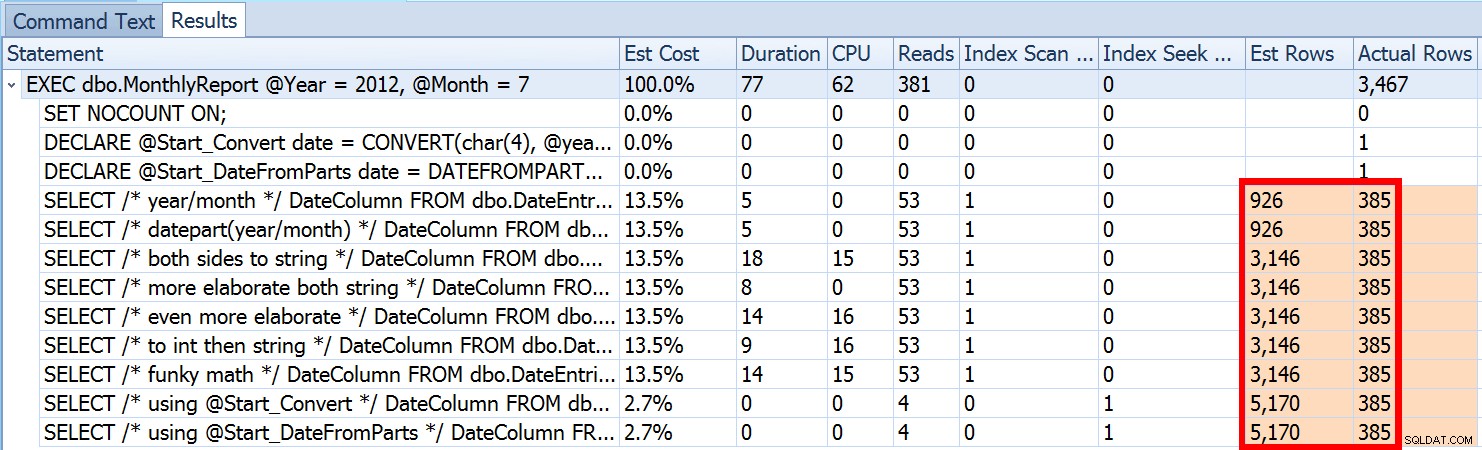
Questo non è raro sia per i predicati di disuguaglianza che con le scansioni forzate. E, naturalmente, il metodo che ho suggerito non produrrebbe le statistiche più imprecise? Ecco l'approccio di base (puoi ottenere lo schema della tabella, gli indici e i dati di esempio dal mio post precedente):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Ora, stime imprecise non saranno sempre un problema, ma possono causare problemi con scelte di piani inefficienti ai due estremi. Un singolo piano potrebbe non essere ottimale quando l'intervallo scelto produrrà una percentuale molto piccola o molto grande della tabella o dell'indice e questo può essere molto difficile da prevedere per SQL Server quando la distribuzione dei dati non è uniforme. Joseph Sack ha delineato le cose più tipiche che le stime sbagliate possono influenzare nel suo post "Dieci minacce comuni alla qualità del piano di esecuzione:"
"[…] stime di riga errate possono influire su una varietà di decisioni, tra cui la selezione dell'indice, le operazioni di ricerca rispetto a scansione, l'esecuzione parallela rispetto a quella seriale, la selezione dell'algoritmo di join, la selezione di join fisico interno rispetto a quello esterno (ad es. build vs. probe), la generazione di spool, ricerche di segnalibri rispetto all'accesso completo a cluster o tabella heap, selezione di flussi o aggregati hash e se una modifica dei dati utilizza o meno un piano ampio o ristretto".
Ce ne sono anche altri, come le concessioni di memoria che sono troppo grandi o troppo piccole. Continua descrivendo alcune delle cause più comuni di stime errate, ma la causa principale in questo caso manca dalla sua lista:le stime. Perché stiamo usando una variabile locale per cambiare il int in entrata parametri a una singola date locale variabile, SQL Server non sa quale sarà il valore, quindi effettua ipotesi standardizzate di cardinalità in base all'intera tabella.
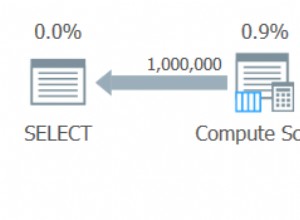
Abbiamo visto sopra che la stima per il mio approccio suggerito era di 5.170 righe. Ora sappiamo che con un predicato di disuguaglianza e con SQL Server che non conosce i valori dei parametri, indovinerà il 30% della tabella. 31,645 * 0.3 non è 5.170. Né 31,465 * 0.3 * 0.3 , quando ricordiamo che in realtà esistono due predicati che lavorano sulla stessa colonna. Quindi da dove viene questo valore di 5.170?
Come descrive Paul White nel suo post "Stima della cardinalità per predicati multipli", il nuovo stimatore di cardinalità in SQL Server 2014 utilizza il backoff esponenziale, quindi moltiplica il conteggio delle righe della tabella (31.465) per la selettività del primo predicato (0,3) , quindi lo moltiplica per la radice quadrata della selettività del secondo predicato (~0,547723).
31.645 * (0,3) * SQRT(0,3) ~=5.170,227Quindi, ora possiamo vedere dove è arrivato SQL Server con la sua stima; quali sono alcuni dei metodi che possiamo usare per fare qualcosa al riguardo?
OPTION (RECOMPILE) . Con un leggero costo di compilazione ogni volta che viene eseguita la query, ciò costringe SQL Server a eseguire l'ottimizzazione in base ai valori presentati ogni volta, invece di ottimizzare un singolo piano per valori di parametro sconosciuti, primi o medi. (Per una trattazione approfondita di questo argomento, vedere "Parameter Sniffing, Embedding, and the RECOMPILE Options" di Paul White.date costruita variabile forza la parametrizzazione corretta (proprio come se avessi chiamato una procedura memorizzata con un date parametro), ma è un po' brutto e più difficile da mantenere.Non ho intenzione di suggerire che questo sia un elenco esaustivo, e non ho intenzione di ribadire il consiglio di Paul su suggerimenti o flag di traccia, quindi mi concentrerò solo sul mostrare come i primi quattro approcci possono mitigare il problema con stime errate .
1. Parametri della data
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Procedura di confezionamento
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPZIONE (RICIMPILA)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. SQL dinamico
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Le prove
Con i quattro insiemi di procedure in atto, è stato facile costruire test che mi avrebbero mostrato i piani e le stime derivate da SQL Server. Poiché alcuni mesi sono più impegnativi di altri, ho scelto tre mesi diversi e li ho eseguiti tutti più volte.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Il risultato? Ogni singolo piano produce la stessa ricerca dell'indice, ma le stime sono corrette solo in tutti e tre gli intervalli di date nel OPTION (RECOMPILE) versione. Gli altri continuano a utilizzare le stime derivate dal primo set di parametri (luglio 2012), e così, mentre ottengono stime migliori per il primo esecuzione, tale stima non sarà necessariamente migliore per il successivo esecuzioni che utilizzano parametri diversi (un classico caso di sniffing dei parametri da manuale):
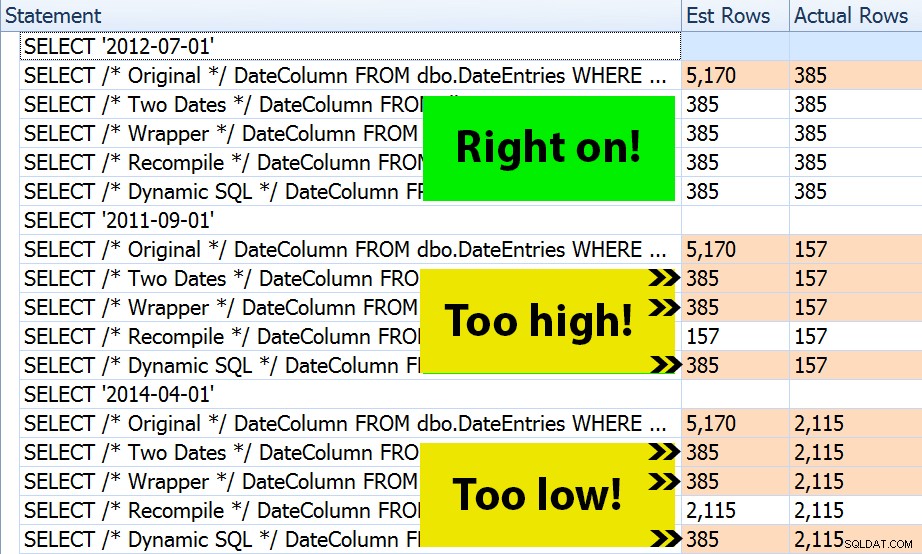
Si noti che quanto sopra non è un output *esatto* da SQL Sentry Plan Explorer:ad esempio, ho rimosso le righe dell'albero delle istruzioni che mostravano le chiamate della stored procedure esterna e le dichiarazioni dei parametri.
Starà a te determinare se la tattica di compilare ogni volta è la migliore per te o se devi "aggiustare" qualcosa in primo luogo. Qui, abbiamo finito con gli stessi piani e nessuna differenza evidente nelle metriche delle prestazioni di runtime. Ma su tabelle più grandi, con una distribuzione dei dati più distorta e varianze maggiori nei valori dei predicati (ad esempio, si consideri un rapporto che può coprire una settimana, un anno e qualsiasi altra via di mezzo), potrebbe valere la pena indagare. E nota che puoi combinare i metodi qui, ad esempio, puoi passare ai parametri della data corretti *e* aggiungere OPTION (RECOMPILE) , se vuoi.
Conclusione
In questo caso specifico, che è una semplificazione intenzionale, lo sforzo per ottenere le stime corrette non è stato davvero ripagato:non abbiamo ottenuto un piano diverso e le prestazioni di runtime erano equivalenti. Ci sono certamente altri casi, tuttavia, in cui questo farà la differenza, ed è importante riconoscere la disparità di stima e determinare se potrebbe diventare un problema man mano che i tuoi dati crescono e/o la tua distribuzione si inclina. Sfortunatamente, non esiste una risposta in bianco o nero, poiché molte variabili influenzeranno la giustificazione del sovraccarico di compilazione, come in molti scenari, IT DEPENDS™ …