Sfondo
Una delle prime cose che guardo durante la risoluzione di un problema di prestazioni sono le statistiche di attesa tramite il DMV sys.dm_os_wait_stats. Per vedere cosa sta aspettando SQL Server, utilizzo la query dell'attuale set di query diagnostiche di SQL Server di Glenn Berry. A seconda dell'output, inizio a scavare in aree specifiche all'interno di SQL Server.
Ad esempio, se vedo attese CXPACKET elevate, controllo il numero di core sul server, il numero di nodi NUMA e i valori per il massimo grado di parallelismo e la soglia di costo per il parallelismo. Si tratta di informazioni di base che utilizzo per comprendere la configurazione. Prima ancora di prendere in considerazione l'idea di apportare modifiche, ne raccolgo altro dati quantitativi, poiché un sistema con CXPACKET attende non ha necessariamente un'impostazione errata per il massimo grado di parallelismo.
Allo stesso modo, un sistema con attese elevate per i tipi di attesa relativi all'I/O come PAGEIOLATCH_XX, WRITELOG e IO_COMPLETION non ha necessariamente un sottosistema di archiviazione inferiore. Quando vedo i tipi di attesa relativi all'I/O mentre la parte superiore attende, voglio immediatamente saperne di più sullo storage sottostante. È uno storage collegato direttamente o una SAN? Qual è il livello RAID, quanti dischi esistono nell'array e qual è la velocità dei dischi? Voglio anche sapere se altri file o database condividono lo spazio di archiviazione. E sebbene sia importante comprendere la configurazione, un passaggio logico successivo consiste nell'esaminare le statistiche dei file virtuali tramite il DMV sys.dm_io_virtual_file_stats.
Introdotto in SQL Server 2005, questo DMV è un sostituto della funzione fn_virtualfilestats che quelli di voi che hanno eseguito su SQL Server 2000 e precedenti probabilmente conoscono e amano. Il DMV contiene informazioni I/O cumulative per ciascun file di database, ma i dati vengono reimpostati al riavvio dell'istanza, quando un database viene chiuso, portato offline, scollegato e ricollegato, ecc. È fondamentale comprendere che i dati delle statistiche dei file virtuali non sono rappresentativi di quelli correnti performance – è un'istantanea che è un'aggregazione di dati di I/O dall'ultima cancellazione da parte di uno degli eventi summenzionati. Anche se i dati non sono puntuali, possono comunque essere utili. Se le attese più elevate per un'istanza sono relative all'I/O, ma il tempo di attesa medio è inferiore a 10 ms, lo storage probabilmente non è un problema, ma vale comunque la pena di correlare l'output con ciò che vedi in sys.dm_io_virtual_stats per confermare basso latenze. Inoltre, anche se vedi latenze elevate in sys.dm_io_virtual_stats, non hai ancora dimostrato che lo storage sia un problema.
La configurazione
Per esaminare le statistiche dei file virtuali, ho impostato due copie del database AdventureWorks2012, che puoi scaricare da Codeplex. Per la prima copia, di seguito nota come EX_AdventureWorks2012, ho eseguito lo script di Jonathan Kehayias per espandere le tabelle Sales.SalesOrderHeader e Sales.SalesOrderDetail rispettivamente a 1,2 milioni e 4,9 milioni di righe. Per il secondo database, BIG_AdventureWorks2012, ho utilizzato lo script del mio precedente post di partizionamento per creare una copia della tabella Sales.SalesOrderHeader con 123 milioni di righe. Entrambi i database sono stati archiviati su un'unità USB esterna (Seagate Slim 500 GB), con tempdb sul mio disco locale (SSD).
Prima del test, ho creato quattro stored procedure personalizzate in ciascun database (Create_Custom_SPs.zip), che fungerebbero da carico di lavoro "normale". Il mio processo di test è stato il seguente per ogni database:
- Riavvia l'istanza.
- Acquisisci le statistiche dei file virtuali.
- Esegui il carico di lavoro "normale" per due minuti (procedure richiamate ripetutamente tramite uno script PowerShell).
- Acquisisci le statistiche dei file virtuali.
- Ricrea tutti gli indici per le tabelle SalesOrder appropriate.
- Acquisisci le statistiche dei file virtuali.
I dati
Per acquisire le statistiche dei file virtuali, ho creato una tabella per contenere informazioni storiche, quindi ho utilizzato una variazione della query di Jimmy May dal suo script DMV All-Stars per l'istantanea:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Ho riavviato l'istanza e quindi ho immediatamente acquisito le statistiche del file. Quando ho filtrato l'output per visualizzare solo i file di database EX_AdventureWorks2012 e tempdb, sono stati acquisiti solo i dati tempdb poiché non erano stati richiesti dati dal database EX_AdventureWorks2012:

Output dall'acquisizione iniziale di sys.dm_os_virtual_file_stats
Ho quindi eseguito il carico di lavoro "normale" per due minuti (il numero di esecuzioni di ciascuna procedura memorizzata variava leggermente) e dopo aver completato le statistiche del file acquisito:

Output da sys.dm_os_virtual_file_stats dopo il normale carico di lavoro
Vediamo una latenza di 57 ms per il file di dati EX_AdventureWorks2012. Non è l'ideale, ma nel tempo con il mio normale carico di lavoro, questo probabilmente si sarebbe stabilizzato. C'è una latenza minima per tempdb, che è prevista poiché il carico di lavoro che ho eseguito non genera molta attività di tempdb. Successivamente ho ricostruito tutti gli indici per le tabelle Sales.SalesOrderHeaderEnlarged e Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Le ricostruzioni hanno richiesto meno di un minuto e si nota il picco nella latenza di lettura per il file di dati EX_AdventureWorks2012 e i picchi nella latenza di scrittura per i dati EX_AdventureWorks2012 e file di registro:

Output da sys.dm_os_virtual_file_stats dopo la ricostruzione dell'indice
Secondo quell'istantanea delle statistiche dei file, la latenza è orribile; oltre 600 ms per le scritture! Se vedessi questo valore per un sistema di produzione, sarebbe facile sospettare immediatamente problemi di archiviazione. Tuttavia, vale anche la pena notare che anche AvgBPerWrite è aumentato e le scritture di blocchi più grandi richiedono più tempo per essere completate. L'aumento di AvgBPerWrite è previsto per l'attività di ricostruzione dell'indice.
Comprendi che se guardi questi dati, non ottieni un quadro completo. Un modo migliore per esaminare le latenze utilizzando le statistiche dei file virtuali è acquisire istantanee e quindi calcolare la latenza per il periodo di tempo trascorso. Ad esempio, lo script seguente utilizza due snapshot (Corrente e Precedente) e quindi calcola il numero di letture e scritture in quel periodo di tempo, la differenza nei valori io_stall_read_ms e io_stall_write_ms, quindi divide io_stall_read_ms delta per il numero di letture e io_stall_write_ms delta per numero di scritture. Con questo metodo, calcoliamo la quantità di tempo che SQL Server era in attesa di I/O per letture o scritture, quindi lo dividiamo per il numero di letture o scritture per determinare la latenza.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Quando eseguiamo questo per calcolare la latenza durante la ricostruzione dell'indice, otteniamo quanto segue:

Latenza calcolata da sys.dm_io_virtual_file_stats durante la ricostruzione dell'indice per EX_AdventureWorks2012
Ora possiamo vedere che la latenza effettiva durante quel periodo era alta, cosa che ci aspetteremmo. E se poi tornassimo al nostro normale carico di lavoro e lo eseguissimo per alcune ore, i valori medi calcolati dalle statistiche dei file virtuali diminuirebbero nel tempo. Infatti, se osserviamo i dati PerfMon che sono stati acquisiti durante il test (e quindi elaborati tramite PAL), notiamo picchi significativi nella media. Disco sec/lettura e media. Disk sec/Write che è correlato al tempo in cui era in esecuzione la ricostruzione dell'indice. Ma altre volte, i valori di latenza sono ben al di sotto dei valori accettabili:
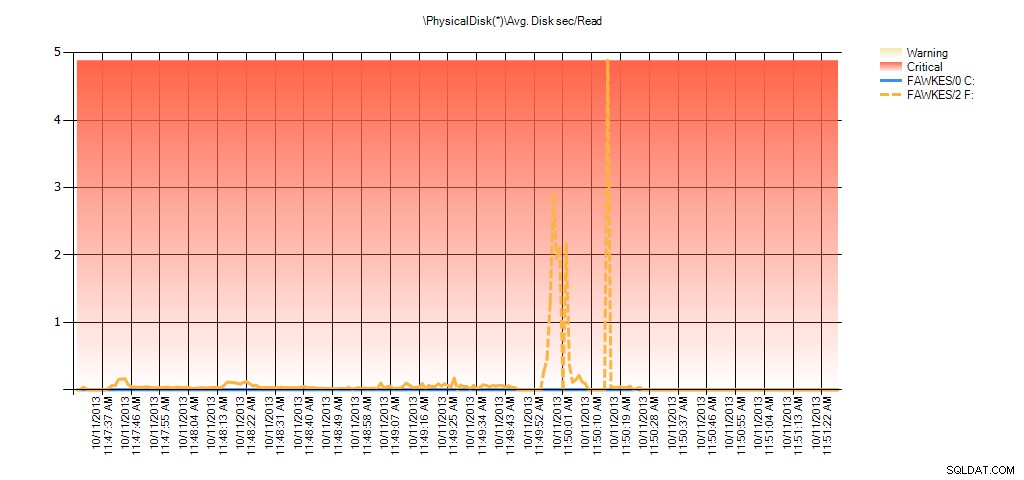
Riepilogo di media disco sec/lettura da PAL per EX_AdventureWorks2012 durante il test
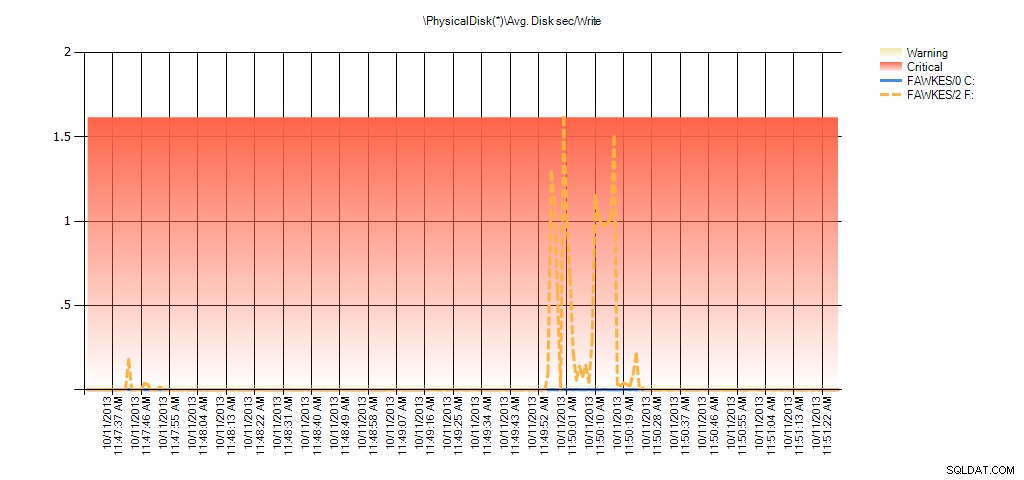
Riepilogo di Avg Disk Sec/Write da PAL per EX_AdventureWorks2012 durante il test
Puoi vedere lo stesso comportamento per il database BIG_AdventureWorks 2012. Ecco le informazioni sulla latenza basate sull'istantanea delle statistiche del file virtuale prima della ricostruzione dell'indice e dopo:

Latenza calcolata da sys.dm_io_virtual_file_stats durante la ricostruzione dell'indice per BIG_AdventureWorks2012
E i dati di Performance Monitor mostrano gli stessi picchi durante la ricostruzione:
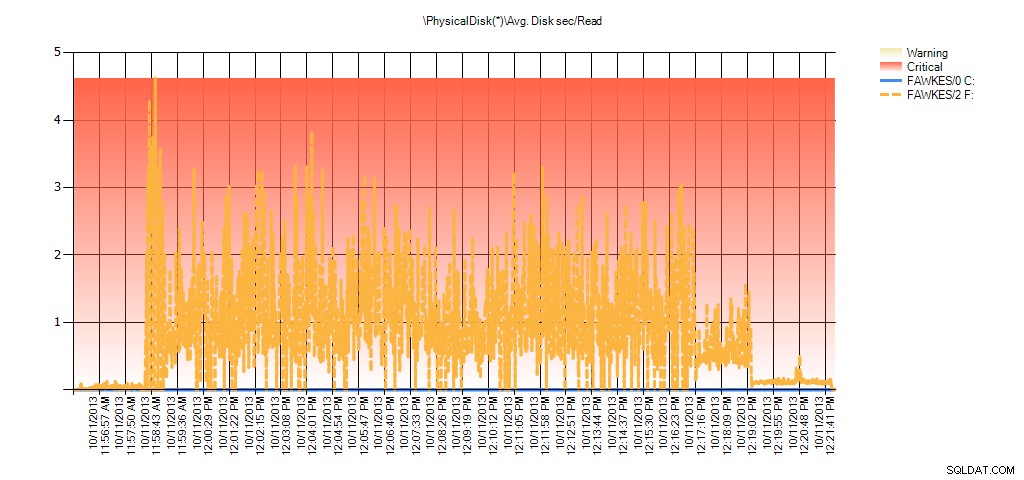
Riepilogo di Avg Disk Sec/Read da PAL per BIG_AdventureWorks2012 durante il test
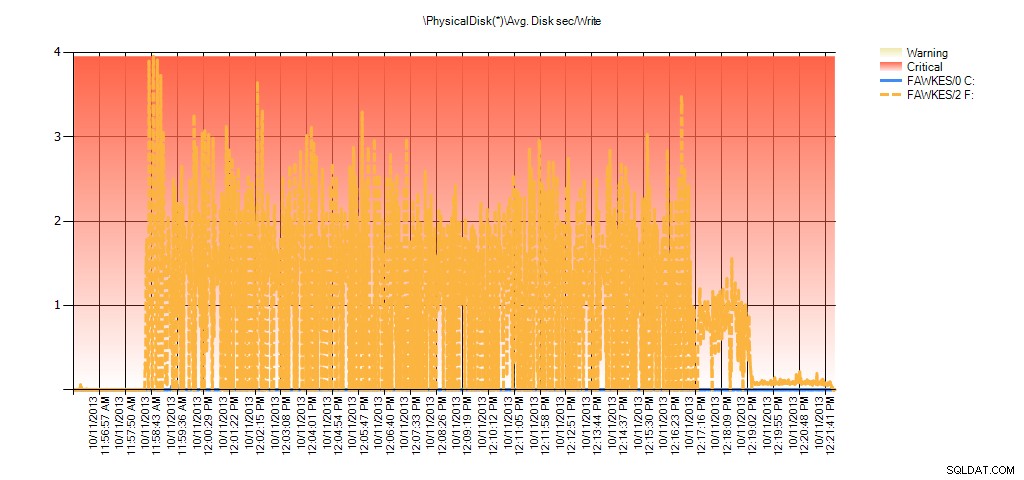
Riepilogo di Avg Disk Sec/Write da PAL per BIG_AdventureWorks2012 durante il test
Conclusione
Le statistiche sui file virtuali sono un ottimo punto di partenza quando si desidera comprendere le prestazioni di I/O per un'istanza di SQL Server. Se vedi le attese relative all'I/O quando guardi le statistiche di attesa, guardare sys.dm_io_virtual_file_stats è un passaggio logico successivo. Tuttavia, tieni presente che i dati che stai visualizzando sono un aggregato dall'ultima cancellazione delle statistiche da parte di uno degli eventi associati (riavvio dell'istanza, offline del database, ecc.). Se vedi basse latenze, il sottosistema di I/O sta tenendo il passo con il carico di prestazioni. Tuttavia, se vedi latenze elevate, non è scontato che lo storage sia un problema. Per sapere davvero cosa sta succedendo, puoi iniziare a creare un'istantanea delle statistiche dei file, come mostrato qui, oppure puoi semplicemente utilizzare Performance Monitor per esaminare la latenza in tempo reale. È molto semplice creare un set di agenti di raccolta dati in PerfMon che acquisisca la media dei contatori del disco fisico. Disco sec/lettura e media. Disk Sec/Read per tutti i dischi che ospitano file di database. Pianifica l'avvio e l'arresto del servizio di raccolta dati su base regolare e campiona ogni n secondi (ad es. 15) e una volta acquisiti i dati PerfMon per un tempo appropriato, eseguili tramite PAL per esaminare la latenza nel tempo.
Se scopri che la latenza di I/O si verifica durante il tuo normale carico di lavoro e non solo durante le attività di manutenzione che guidano l'I/O, comunque non può indicare l'archiviazione come problema sottostante. La latenza di archiviazione può esistere per una serie di motivi, ad esempio:
- SQL Server deve leggere troppi dati a causa di piani di query inefficienti o indici mancanti
- All'istanza viene allocata troppa poca memoria e gli stessi dati vengono letti continuamente dal disco perché non possono rimanere in memoria
- Le conversioni implicite causano scansioni di indici o tabelle
- Le query eseguono SELECT * quando non tutte le colonne sono richieste
- I problemi di record inoltrati negli heap causano I/O aggiuntivi
- Le densità di pagina basse dovute alla frammentazione dell'indice, alle divisioni di pagina o alle impostazioni errate del fattore di riempimento causano ulteriori I/O
Qualunque sia la causa principale, ciò che è essenziale comprendere sulle prestazioni, in particolare per quanto riguarda l'I/O, è che raramente esiste un punto dati che è possibile utilizzare per individuare il problema. Trovare il vero problema richiede più fatti che, se messi insieme, ti aiutano a scoprire il problema.
Infine, tieni presente che in alcuni casi la latenza di archiviazione potrebbe essere completamente accettabile. Prima di richiedere uno storage più rapido o modifiche al codice, rivedere i modelli di carico di lavoro e il Service Level Agreement (SLA) per il database. Nel caso di un Data Warehouse che fornisce report agli utenti, lo SLA per le query probabilmente non corrisponde agli stessi valori inferiori al secondo che ti aspetteresti per un sistema OLTP ad alto volume. Nella soluzione DW, latenze I/O superiori a un secondo potrebbero essere perfettamente accettabili e previste. Comprendere le aspettative dell'azienda e dei suoi utenti, quindi determinare l'eventuale azione da intraprendere. E se sono necessarie modifiche, raccogli i dati quantitativi di cui hai bisogno per supportare la tua argomentazione, vale a dire le statistiche di attesa, le statistiche sui file virtuali e le latenze da Performance Monitor.