Nel nostro blog precedente abbiamo studiato Introduzione a Hadoop e Caratteristiche di Hadoop , Ora in questo blog tratteremo in dettaglio la funzione di alta disponibilità di NameNode HDFS.
Prima di tutto, discuteremo dell'architettura ad alta disponibilità NemNode HDFS, quindi dell'implementazione dell'architettura ad alta disponibilità Hadoop utilizzando Quorum Journal Nodes e Shared Storage.
Alta disponibilità di NameNode HDFS
In HDFS , i dati sono altamente disponibili e accessibili nonostante un guasto hardware. HDFS è il sistema di archiviazione più affidabile progettato per archiviare file di grandi dimensioni.
HDFS segue la topologia master/slave. In cui il master è NameNode e slave è DataNode . NameNode memorizza i metadati. I metadati includono il numero di blocchi, la loro posizione, le repliche e altri dettagli. Per il recupero più rapido dei dati, i metadati sono disponibili nel master. NameNode mantiene e assegna attività al nodo slave.
NameNode era il punto singolo di errore (SPOF) prima di Hadoop 2.0. Il cluster HDFS aveva un unico NameNode. Se il NameNode ha esito negativo, l'intero cluster si interrompe.
Un singolo punto di errore limita la disponibilità elevata nei seguenti modi:
- Se si attiva un evento non pianificato, come un arresto anomalo del nodo, il cluster non sarebbe disponibile a meno che un operatore non riavvii il nuovo namenode.
- Anche le attività di manutenzione pianificate come gli aggiornamenti hardware sul NameNode comporteranno tempi di inattività del cluster Hadoop.
Architettura ad alta disponibilità NameNode HDFS
L'introduzione di Hadoop 2.0 supera questoSPOF fornendo supporto a più NameNode. L'architettura HDFS NameNode High Availability offre la possibilità di eseguire due NameNode ridondanti nello stesso cluster in una configurazione attiva/passiva con hot standby.
- NomeNode attivo – Gestisce tutte le operazioni client HDFS nel cluster HDFS.
- NomePassivo – È un namenode in standby. Ha dati simili al NameNode attivo.
Quindi, ogni volta che Active NameNode fallisce, il NameNode passivo si assumerà tutta la responsabilità del nodo attivo. Pertanto, il cluster HDFS continua a funzionare.
I problemi nel mantenimento della coerenza nel cluster ad alta disponibilità HDFS sono i seguenti:
- Active e Standby NameNode dovrebbero essere sempre sincronizzati tra loro, ovvero dovrebbero avere gli stessi metadati. Questo consente di ripristinare il cluster Hadoop nello stesso stato dello spazio dei nomi in cui è stato arrestato in modo anomalo. E questo ci consentirà di avere un failover veloce.
- Ci dovrebbe essere un solo NameNode attivo alla volta. In caso contrario, due NameNode porteranno alla corruzione dei dati. Chiamiamo questo scenario come "Scenario del cervello diviso ”, dove un cluster viene diviso nel cluster più piccolo. Ognuno crede che sia l'unico cluster attivo. "Scherma" evita tale Scherma è un processo per garantire che un solo NameNode rimanga attivo in un determinato momento.
Implementazione dell'architettura ad alta disponibilità Hadoop
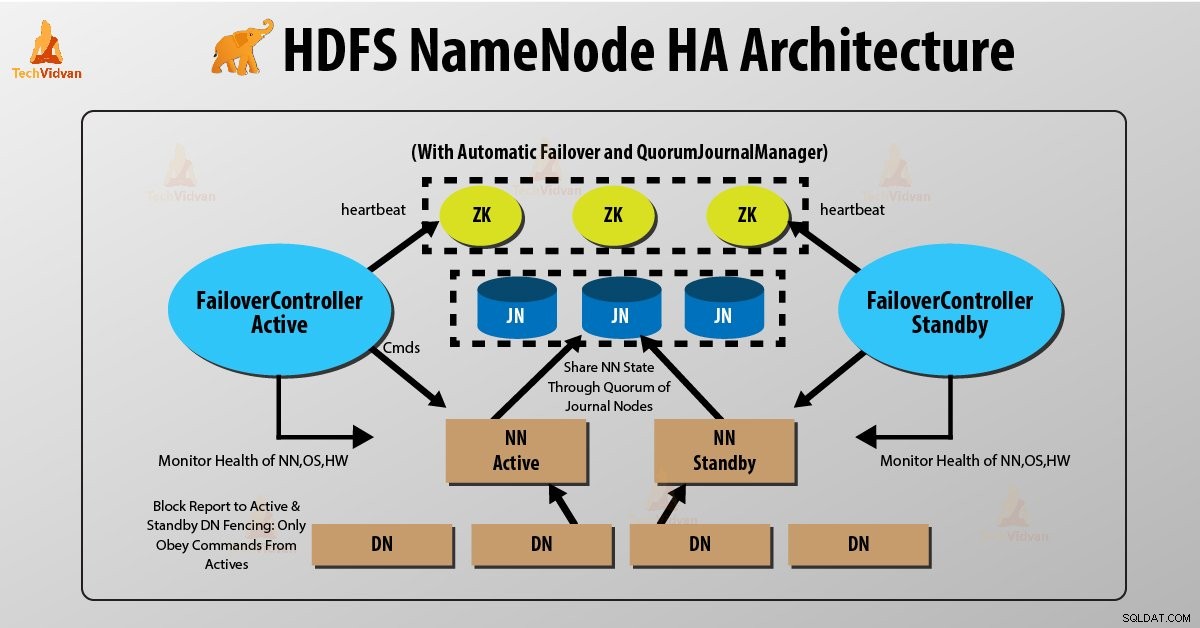
Due NameNode vengono eseguiti contemporaneamente nell'architettura ad alta disponibilità di NameNode HDFS. Il client HDFS può implementare la configurazione di NameNode attivo e standby nei due modi seguenti:
- Utilizzo dei nodi del diario del quorum
- Utilizzo dello spazio di archiviazione condiviso
1. Utilizzo dei nodi del diario del quorum
Nodi del diario del quorum è un'implementazione HDFS. QJN fornisce registri di modifica. Consente di condividere questi log di modifica tra il NameNode attivo e quello in standby.
Standby Namenode comunica e si sincronizza con il NameNode attivo per un'elevata disponibilità. Accadrà da un gruppo di demoni chiamati "Journal nodes". I nodi del giornale Quorum vengono eseguiti come un gruppo di nodi del giornale. Dovrebbero essere presenti almeno tre nodi journal.
Per N nodi journal, il sistema può tollerare al massimo (N-1)/2 errori. Il sistema continua così a funzionare. Quindi, per tre nodi journal, il sistema può tollerare il guasto di uno {(3-1)/2} di essi.
Ogni volta che un nodo attivo esegue una modifica, registra la modifica in tutti i nodi del journal.
Il nodo standby legge le modifiche dai nodi journal e si applica al proprio spazio dei nomi in modo costante. In caso di failover, lo standby si assicurerà di aver letto tutte le modifiche dai nodi del journal prima di passare allo stato Attivo. Ciò garantisce che lo stato dello spazio dei nomi sia completamente sincronizzato prima che si verifichi un errore.
Per fornire un failover rapido, il nodo di standby deve disporre di informazioni aggiornate sulla posizione dei blocchi di dati nel cluster. Affinché ciò avvenga, l'indirizzo IP di entrambi i NameNode è disponibile per tutti i datanode e inviano informazioni sulla posizione del blocco e heartbeat a entrambi i NameNode.
Recinzione di NameNode
Per il corretto funzionamento di un cluster HA, deve essere attivo solo uno dei NameNode alla volta. In caso contrario, lo stato dello spazio dei nomi si discosterebbe tra i due NameNode. Quindi, la scherma è un processo per garantire questa proprietà in un cluster.
- I nodi del journal eseguono questa scherma consentendo a un solo NameNode di essere lo scrittore alla volta.
- Il NameNode in standby si assume la responsabilità di scrivere sui nodi del journal e vietare a qualsiasi altro NameNode di rimanere attivo.
- Finalmente, il nuovo NameNode attivo può svolgere le sue attività.
2. Utilizzo dello spazio di archiviazione condiviso
I NameNode in standby e attivi si sincronizzano tra loro utilizzando il "dispositivo di archiviazione condiviso". Per questa implementazione, sia il NameNode attivo che il Namenode di standby devono avere accesso alla directory particolare sul dispositivo di archiviazione condiviso (cioè il file system di rete).
Quando il NameNode attivo esegue qualsiasi modifica dello spazio dei nomi, registra un record della modifica in un file di registro delle modifiche archiviato nella directory condivisa. Il NameNode in standby controlla questa directory per le modifiche e, quando si verificano modifiche, il NameNode in standby le applica al proprio spazio dei nomi. In caso di errore, il NameNode in standby si assicurerà di aver letto tutte le modifiche dalla memoria condivisa prima di passare allo stato Attivo. Ciò garantisce che lo stato dello spazio dei nomi sia completamente sincronizzato prima che si verifichi il failover.
Per evitare lo "scenario del cervello diviso" in cui lo stato dello spazio dei nomi devia tra i due NameNode, un amministratore deve configurare almeno un metodo di fencing per l'archiviazione condivisa.
Conclusione
Quindi, Hadoop 2.0 HDFS HA fornisce un singolo NameNode attivo e un singolo NameNode in standby. Ma alcune implementazioni richiedono un alto grado di tolleranza ai guasti . Hadoop nuova versione 3.0, consente all'utente di eseguire molti NameNode in standby.
Ad esempio, la configurazione di cinque journalnode e tre NameNode. Di conseguenza, il cluster hadoop è in grado di tollerare il guasto di due nodi anziché di uno.
Condividi la tua esperienza e i tuoi suggerimenti in relazione all'alta disponibilità di NameNode HDFS nella sezione commenti qui sotto.



