Questa è la parte 2 di questa serie di blog. Puoi leggere la parte 1, qui: La trasformazione digitale è un viaggio di dati da Edge a Insight
Questa serie di blog segue i dati di produzione, operazioni e vendite di un produttore di veicoli connesso mentre i dati attraversano fasi e trasformazioni tipiche di una grande azienda manifatturiera all'avanguardia della tecnologia attuale. Il primo blog ha introdotto una finta azienda produttrice di veicoli connessi, The Electric Car Company (ECC), per illustrare il percorso dei dati di produzione attraverso il ciclo di vita dei dati. A tal fine, ECC sta sfruttando la Cloudera Data Platform (CDP) per prevedere gli eventi e avere una visione dall'alto del processo di produzione dell'auto all'interno dei suoi stabilimenti dislocati in tutto il mondo.
Dopo aver completato la fase di raccolta dei dati nel blog precedente, la fase successiva di ECC nel ciclo di vita dei dati è l'arricchimento dei dati. ECC arricchirà i dati raccolti e li renderà disponibili per essere utilizzati nell'analisi e nella creazione di modelli più avanti nel ciclo di vita dei dati. Di seguito è riportato l'intero insieme di passaggi del ciclo di vita dei dati e ogni passaggio del ciclo di vita sarà supportato da un post sul blog dedicato (vedi Fig. 1):
- Raccolta dati – acquisizione e monitoraggio dei dati all'edge (che si tratti di sensori industriali o persone in un'autosalone)
- Arricchimento dei dati – elaborazione, aggregazione e gestione della pipeline di dati per preparare i dati per ulteriori analisi
- Segnalazione – fornire informazioni dettagliate sul business (analisi e previsioni delle vendite, budget come esempi)
- Servizio – controllo e gestione delle operazioni aziendali essenziali (operazioni dei rivenditori, monitoraggio della produzione)
- Analisi predittiva – analisi predittiva basata sull'intelligenza artificiale e sull'apprendimento automatico (manutenzione predittiva, ottimizzazione dell'inventario basata sulla domanda come esempi)
- Sicurezza e governance – un insieme integrato di tecnologie di sicurezza, gestione e governance lungo l'intero ciclo di vita dei dati

Fig. 1 Il ciclo di vita dei dati aziendali
Sfida sull'arricchimento dei dati
ECC necessita di una visione completa e di una solida comprensione di tutti i dati relativi alla produzione, alle operazioni dei concessionari e alla spedizione dei loro veicoli. Dovranno anche identificare rapidamente problemi con i dati, come sensori operativi che producono dati che potrebbero includere falsi picchi di temperatura causati da arresti macchina non pianificati o avviamenti improvvisi. I dati che non hanno alcuna relazione con il processo quando gli addetti alla manutenzione rimuovono un sensore da un serbatoio a immersione di acido durante le ispezioni di routine, ad esempio, non dovrebbero essere presi in considerazione nell'analisi.
Inoltre, ECC deve affrontare le seguenti sfide relative ai dati che devono essere affrontate per spostare con successo la produzione di motori attraverso la sua catena di approvvigionamento. Queste sfide relative ai dati includono quanto segue:
- Recupero di dati in vari formati da diverse fonti: Le pipeline di ingegneria dei dati richiedono che i dati vengano importati da varie fonti e in molti formati diversi. Indipendentemente dal fatto che i dati provengano da sensori che si trovano sulla linea di produzione, che supportano le operazioni di produzione o da dati ERP che controllano la catena di approvvigionamento, è necessario riunirli tutti per ulteriori analisi.
- Filtraggio di dati ridondanti o irrilevanti: La rimozione dei dati duplicati o non validi e la garanzia dell'accuratezza dei dati rimanenti sono un passaggio fondamentale nella preparazione dei dati per un ulteriore utilizzo nell'analisi predittiva avanzata.
- Capacità di identificare processi inefficienti: L'ECC richiede la capacità di vedere quali processi di dati richiedono più tempo e risorse, semplificando il targeting di parti della pipeline con prestazioni insufficienti al fine di accelerare il processo complessivo.
- Possibilità di monitorare tutti i processi da un unico riquadro: ECC richiede un sistema centralizzato che consenta loro di monitorare tutti i processi di dati in corso, nonché una strada per espandere la propria infrastruttura attuale mantenendo la trasparenza.
Set di dati curati e di qualità sono la spina dorsale di qualsiasi iniziativa di analisi avanzata. A tal fine, è necessario utilizzare un framework di ingegneria dei dati per consentire la costruzione di tutte le tubazioni e gli impianti idraulici necessari per spostare, manipolare e gestire i dati delle diverse parti del veicolo nel ciclo di vita dei dati.
Costruzione di una pipeline utilizzando Cloudera Data Engineering
Prima che i dati vengano arricchiti e discussi nel primo blog, i flussi di dati IT e OT raccolti dalla fabbrica verranno puliti, manipolati e modificati. L'ID di fabbrica, l'ID macchina, il timestamp, il numero di parte e il numero di serie possono essere acquisiti da un codice QR stampato sul motore elettrico. Quando il motore viene assemblato nel veicolo connesso, vengono acquisiti dati come tipo di modello, VIN e costo base del veicolo.
Dopo la vendita del veicolo, le informazioni di vendita come il nome del cliente, le informazioni di contatto, il prezzo di vendita finale e l'ubicazione del cliente vengono registrate separatamente. Questi dati saranno fondamentali per contattare il cliente per eventuali richiami o manutenzioni preventive mirate. Vengono inoltre archiviati i dati di geolocalizzazione, che aiuteranno a mappare le posizioni dei clienti a latitudini e longitudini per capire meglio dove si trovano questi motori dopo essere stati venduti in un veicolo.
ECC utilizzerà Cloudera Data Engineering (CDE) per affrontare le sfide dei dati di cui sopra (vedi Fig. 2). CDE renderà quindi disponibili i dati a Cloudera Data Warehouse (CDW), dove saranno resi disponibili per analisi avanzate e report di business intelligence. I passaggi del CDE sono descritti di seguito.
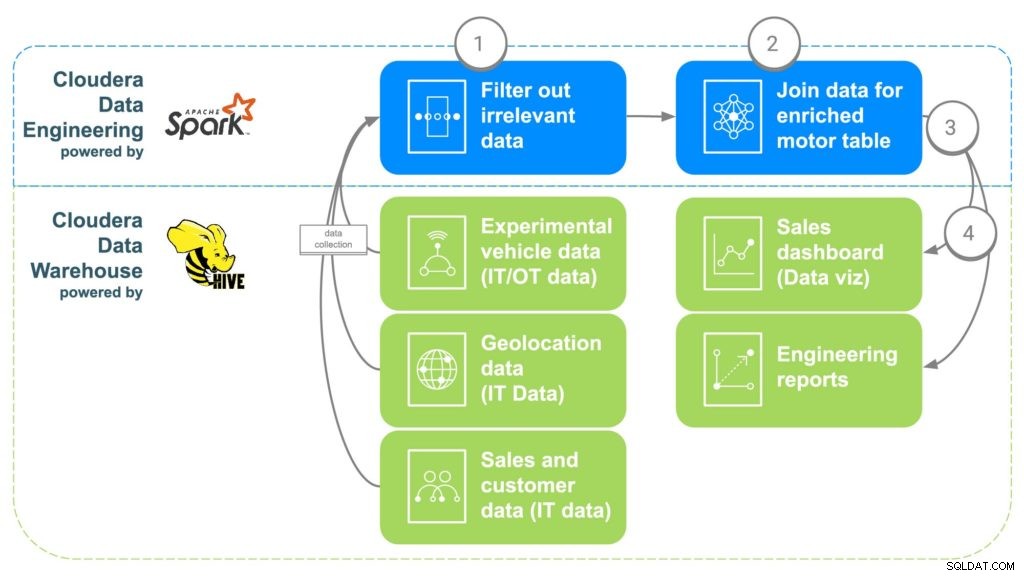
Fig. 2 Pipeline di arricchimento dei dati ECC
PASSAGGIO 1:Filtra e separa i dati
Il primo passaggio nell'utilizzo di CDE consiste nel creare un processo PySpark che porti i dati da queste varie fonti "grezze" dal passaggio 1. Questa è un'opportunità per filtrare tutti i dati irrilevanti come i clienti di età inferiore a 16 anni, ad esempio, dal momento che è in genere l'età minima per guidare. I dati duplicati e altri dati irrilevanti possono anche essere filtrati o separati.
PASSAGGIO 2:Combina i dati
Al fine di combinare tutti i dati, CDE metterà in correlazione i collegamenti comuni tra loro. In primo luogo, i dati di vendita dell'auto saranno collegati al cliente che ha acquistato l'auto per ottenere i metadati del cliente, come informazioni di contatto, età, stipendio, ecc. I dati di geolocalizzazione verranno quindi utilizzati per ottenere informazioni sulla posizione più precise per il cliente , che aiuterà a mappare i motori in seguito. I dati di installazione delle parti verranno utilizzati per identificare i numeri di serie di ciascun motore installato nell'auto del cliente. Infine, i dati di fabbrica verranno allineati per corrispondere al numero di serie del motore che identificherà quale fabbrica, macchina e quando è stato creato ciascun motore specifico.
PASSAGGIO 3:invia i dati a Cloudera Data Warehouse
Una volta che tutti i dati sono stati riuniti in una tabella arricchita, un semplice comando Apache Spark scriverà i dati in una nuova tabella all'interno di Cloudera Data Warehouse. Ciò renderà i dati accessibili a tutti i data scientist che potrebbero voler accedervi per eseguire ulteriori analisi.
PASSAGGIO 4:Genera dashboard e report per la visualizzazione dei dati
Con i dati tutti in un unico posto, ora è possibile creare report che consentiranno ai dipendenti di prendere decisioni più informate e di aprire capacità che non esistevano. È possibile creare mappe di calore per tracciare la posizione del motore e correlare eventuali problemi con potenziali posizioni geografiche, come guasti dovuti a freddo o caldo estremi. Questi dati potrebbero essere utilizzati anche per tracciare esattamente ciò che i clienti potrebbero essere interessati se si verificasse un problema in una determinata fabbrica in un intervallo di tempo, rendendo facile rintracciare i clienti che potrebbero aver bisogno di un richiamo o di una manutenzione preventiva.
Conclusione
Cloudera Data Engineering consente a ECC di creare una pipeline in grado di correlare i dati di produzione e parti, il tipo di utilizzo del cliente, le condizioni ambientali, le informazioni sulle vendite e altro al fine di migliorare la soddisfazione del cliente e l'affidabilità del veicolo. ECC ha raggiunto i suoi obiettivi e affrontato le loro sfide tracciando i dati relativi alla produzione dei suoi motori e traendo vantaggio nei seguenti modi:
- ECC ha accelerato il time to value orchestrando e automatizzando le pipeline di dati per fornire set di dati curati e di qualità in modo sicuro e trasparente da varie origini dati.
- ECC è stato in grado di identificare i dati rilevanti e filtrare i dati ridondanti e duplicati.
- ECC è stato in grado di ottenere il monitoraggio della pipeline di dati da un unico riquadro, pur essendo in grado di essere avvisato per rilevare tempestivamente i problemi attraverso la risoluzione dei problemi visivi per risolvere rapidamente i problemi prima che l'azienda ne risentisse.
Cerca il prossimo blog che approfondirà i rapporti e mostrerà come gli ingegneri ECC eseguono query ad hoc in CDW su questi dati curati e uniscono i dati ad altre fonti pertinenti all'interno di un data warehouse aziendale. CDW facilita l'unione di tutti i dati e fornisce uno strumento di visualizzazione dei dati integrato per passare dai risultati delle query ai dashboard. Resta sintonizzato per il prossimo!
Più risorse per la raccolta dei dati
Per vedere tutto questo in azione, fare clic sui collegamenti correlati di seguito per ulteriori informazioni sull'arricchimento dei dati:
- Video – Se vuoi vedere e ascoltare come è stato costruito, guarda il video al link.
- Tutorial:se desideri farlo al tuo ritmo, guarda una procedura dettagliata con schermate e istruzioni riga per riga su come configurarlo ed eseguirlo.
- Meetup – Se vuoi parlare direttamente con gli esperti di Cloudera, partecipa a un meetup virtuale per vedere una presentazione in live streaming. Alla fine ci sarà tempo per domande e risposte dirette.
- Utenti:per visualizzare più contenuti tecnici specifici per gli utenti, fare clic sul collegamento.



