Dove memorizziamo le immagini?
Soluzione n. 1 in MongoDB
Quindi la prima soluzione è archiviare le immagini all'interno di MongoDB. Può contenere file di immagine o qualsiasi tipo di file. Quindi puoi prendere un file e legarlo a un record all'interno di MongoDB e salvarlo direttamente nel tuo database.
Con questo approccio, legare una pagina di descrizione di un particolare capo di abbigliamento con la sua immagine corrispondente diventa facile perché puoi incorporare questa immagine direttamente nello sviluppo di quella pagina e il tuo cliente sarebbe felice di quell'approccio perché quando l'utente recupera una descrizione dettagliata pagina di quel capo di abbigliamento viene fornito con l'immagine.
Quindi questa è una possibile soluzione, prendi l'immagine e salvala direttamente in MongoDB.
Tuttavia, sto per suggerire che questo è un approccio sbagliato. Il motivo per cui puoi dire al tuo cliente in caso di respingimento è che di solito pagherà per la sua istanza Mongo in termini di quantità di spazio di archiviazione utilizzata dalla sua copia Mongo.
Quindi, più spazio di archiviazione consumano, pagano di più al mese.
Ad esempio, l'ultima volta che ho controllato l'uso di MLab, stavano addebitando $ 15 per GB. Quindi sono $ 15 dalla tasca dei tuoi clienti per l'hosting di 1 GB di immagini.
Per l'ennesimo sito di e-commerce si parla di 3GB easy che si traducono in 330 immagini in più o in meno, pari a 15$ al mese.
Quindi, se uno dei loro project manager carica un nuovo capo di abbigliamento una volta al giorno, stiamo parlando di un costo enorme molto rapidamente.
Quindi, personalmente penso che archiviare qualsiasi tipo di file direttamente all'interno di MongoDB non sia davvero un'opzione perché diventerebbe molto costoso.
Quindi questa è solo una possibile soluzione.
Soluzione n. 2 in HD collegata al server
Quindi diamo un'occhiata a una seconda soluzione che potrebbe essere disponibile per te. Potresti usare un disco rigido collegato al tuo server Express. Quindi, quando questa applicazione viene distribuita in un ambiente cloud come Heroku, Digital Ocean, Linode o AWS, di solito ottieni un disco rigido associato alla tua applicazione.
Quindi forse prendi le immagini e le metti all'interno del disco rigido locale. Questo approccio è ciò che la stragrande maggioranza dei post e degli articoli online sosterrà:
Come per caricare, visualizzare e salvare immagini utilizzando node.js ed express
https://appdividend. com/2019/02/14/node-express-image-upload-and-resize-tutorial-example/
https://medium.com/@nitinpatel_20236/image-upload -via-nodejs-server-3fe7d3faa642
Solo con i tre che ho raccolto sopra hai un progetto piuttosto robusto con cui iniziare.
Ognuno dice di prendere il file e salvarlo sul disco rigido locale. In questo particolare articolo:
https://alligator.io/nodejs/uploading-files-multer-express/
stanno mostrando questo codice:
const storage = multer.diskStorage({
destination: 'some-destination',
filename: function (req, file, callback) {
//..
}
});
Stanno usando la libreria di caricamento delle immagini chiamata multer che fornisce diskStorage() motore per caricare le immagini su disco.
Quindi questo è un approccio con cui la comunità di sviluppo in generale è d'accordo.
Questo è un buon approccio nel contesto di una mappatura uno-a-uno.
I problemi con questo approccio iniziano a sorgere quando abbiamo più macchine.
Un esempio è se hai più macchine ospitate su Digital Ocean o Linode in cui ogni ambiente è un'istanza separata.
Se hai tutte le tue immagini archiviate nel disco rigido di accompagnamento e poi inizi a ridimensionare il tuo server, ciascuna avrà il proprio disco rigido separato.
Quindi potresti avere una richiesta che arriva tramite un sistema di bilanciamento del carico e il sistema di bilanciamento del carico decide dove inviare la richiesta come nel diagramma seguente:
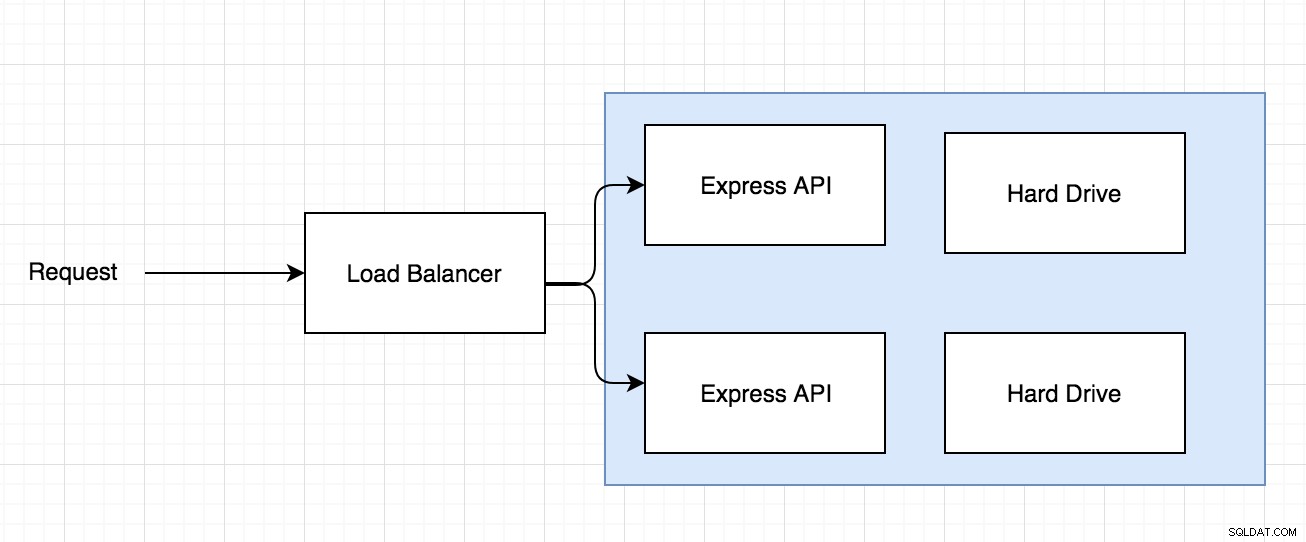
Quindi il problema con l'architettura di cui sopra è se l'immagine viene salvata su uno dei due dischi rigidi e successivamente arriva una richiesta per accedere alla stessa immagine, ma immagina che la richiesta venga instradata all'altro server Express con un disco rigido diverso dove l'immagine non esiste.
Questo è un problema che si presenta quando inizi a utilizzare un fornitore di servizi come Linode o Digital Ocean in cui hai una mappatura uno-a-uno tra server e disco rigido.
È una soluzione a breve termine se per ora è tutto ciò di cui hai bisogno, ma una volta che l'applicazione inizierà a scalare, diventerà un problema.
Soluzione n. 3 al di fuori dell'archivio dati
Questa terza soluzione è quella che ho usato in passato con le applicazioni React with Node e anche con le applicazioni Ruby on Rails. In effetti, il mio sito Web portfolio Ruby on Rails utilizza questa soluzione e si trova sulla piattaforma Heroku.
Quindi, quando l'immagine viene caricata, anziché l'API Express che tenta di archiviare il file localmente come sul proprio disco rigido, prenderà l'immagine e utilizzerà un archivio dati esterno per contenere tutte le diverse immagini dall'app.
Quello che uso per il mio sito Web portfolio e quello che ho usato per le applicazioni Node with React è stato Amazon S3, ma esistono anche Azure File Storage e Google Cloud Storage. Questi sistemi sono fatti per contenere un'enorme quantità di dati e possono essere qualsiasi tipo di file che possiate immaginare. Non solo immagini come nel tuo caso, ma file video, file audio, ecc.
Non c'è limite alla quantità di spazio di archiviazione che puoi avere con S3, ma non devi usare S3, ma è visto come uno standard del settore in questo momento, ma puoi facilmente usare altrettanto bene Azure e Google Cloud.
Il vantaggio di questa soluzione, che penso apprezzeranno i tuoi clienti, è che Amazon S3 ti addebita circa due penny per gigabyte al mese per l'archiviazione.



