Il miglioramento delle prestazioni del sistema, in particolare per le strutture dei computer, richiede un processo per ottenere una buona panoramica delle prestazioni. Questo processo è generalmente chiamato monitoraggio. Il monitoraggio è una parte essenziale della gestione del database e le informazioni dettagliate sulle prestazioni del tuo MongoDB non solo ti aiuteranno a misurarne lo stato funzionale; ma anche dare un indizio sulle anomalie, che è utile durante la manutenzione. È essenziale identificare i comportamenti insoliti e correggerli prima che si trasformino in guasti più gravi.
Alcuni dei tipi di guasti che potrebbero verificarsi sono...
- Lag o rallentamento
- Inadeguatezza delle risorse
- Singhiozzo del sistema
Il monitoraggio è spesso incentrato sull'analisi delle metriche. Alcune delle metriche chiave che vorrai monitorare includono...
- Prestazioni del database
- Utilizzo delle risorse (utilizzo della CPU, memoria disponibile e utilizzo della rete)
- Emergenti battute d'arresto
- Saturazione e limitazione delle risorse
- Operazioni di elaborazione
In questo blog discuteremo, in dettaglio, di queste metriche e esamineremo gli strumenti disponibili da MongoDB (come utilità e comandi). Esamineremo anche altri strumenti software come Pandora, FMS Open Source e Robo 3T. Per semplicità, in questo articolo utilizzeremo il software Robo 3T per dimostrare le metriche.
Prestazioni del database
La prima e più importante cosa da controllare su un database sono le sue prestazioni generali, ad esempio se il server è attivo o meno. Se esegui questo comando db.serverStatus() su un database in Robo 3T, ti verranno presentate queste informazioni che mostrano lo stato del tuo server.
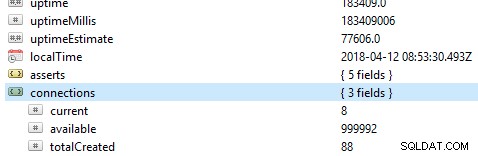

Set di repliche
Il set di repliche è un gruppo di processi mongod che mantengono lo stesso set di dati. Se si utilizzano set di repliche soprattutto nella modalità di produzione, i registri delle operazioni forniranno una base per il processo di replica. Tutte le operazioni di scrittura vengono tracciate utilizzando i nodi, ovvero un nodo primario e un nodo secondario, che memorizzano una raccolta di dimensioni limitate. Sul nodo primario vengono applicate ed elaborate le operazioni di scrittura. Tuttavia, se il nodo primario si guasta prima di essere copiato nei registri delle operazioni, viene eseguita la scrittura secondaria, ma in questo caso i dati potrebbero non essere replicati.
Metriche chiave da tenere d'occhio...
Ritardo di replica
Questo definisce la distanza del nodo secondario dietro il nodo primario. Uno stato ottimale richiede che il divario sia il più piccolo possibile. In un normale sistema operativo, questo ritardo è stimato a 0. Se il divario è troppo ampio, l'integrità dei dati verrà compromessa una volta che il nodo secondario viene promosso a primario. In questo caso è possibile impostare una soglia, ad esempio 1 minuto, e se viene superata viene impostato un avviso. Le cause comuni di un ampio ritardo di replica includono...
- Shard che potrebbero avere una capacità di scrittura insufficiente, spesso associata alla saturazione delle risorse.
- Il nodo secondario fornisce i dati a una velocità inferiore rispetto al nodo primario.
- I nodi possono anche essere impediti in qualche modo di comunicare, probabilmente a causa di una rete scadente.
- Anche le operazioni sul nodo primario potrebbero essere più lente, bloccando così la replica. In questo caso puoi eseguire i seguenti comandi:
- db.getProfilingLevel():se ottieni un valore pari a 0, le tue operazioni db sono ottimali.
Se il valore è 1, corrisponde a operazioni lente che possono essere di conseguenza dovute a query lente. - db.getProfilingStatus():in questo caso controlliamo il valore di slowms, di default è 100ms. Se il valore è maggiore di questo, è possibile che si verifichino operazioni di scrittura pesanti sulle risorse primarie o inadeguate su quelle secondarie. Per risolvere questo problema, puoi ridimensionare il secondario in modo che abbia tante risorse quanto il primario.
- db.getProfilingLevel():se ottieni un valore pari a 0, le tue operazioni db sono ottimali.
Cursori
Se fai una richiesta di lettura, ad esempio trova, ti verrà fornito un cursore che è un puntatore al set di dati del risultato. Se esegui questo comando db.serverStatus() e vai all'oggetto delle metriche, quindi al cursore, vedrai questo...

In questo caso, la proprietà cursor.timeOut è stata aggiornata in modo incrementale a 9 perché c'erano 9 connessioni interrotte senza chiudere il cursore. La conseguenza è che rimarrà aperto sul server e quindi consumerà memoria, a meno che non venga raccolto dall'impostazione predefinita di MongoDB. Un avviso per te dovrebbe identificare i cursori non attivi e raccoglierli per risparmiare memoria. Puoi anche evitare i cursori senza timeout perché spesso trattengono le risorse, rallentando così le prestazioni del sistema interno. Ciò può essere ottenuto impostando il valore della proprietà cursor.open.noTimeout su un valore di 0.
Diario
Considerando il WiredTiger Storage Engine, prima che i dati vengano registrati, vengono prima scritti sui file del disco. Questo è indicato come journaling. Il journaling garantisce la disponibilità e la durabilità dei dati su un evento di errore da cui è possibile eseguire un ripristino.
Ai fini del ripristino, utilizziamo spesso i checkpoint (soprattutto per il sistema di archiviazione WiredTiger) per eseguire il ripristino dall'ultimo checkpoint. Tuttavia, se MongoDB si arresta in modo imprevisto, utilizziamo la tecnica di journaling per recuperare tutti i dati elaborati o forniti dopo l'ultimo checkpoint.
Il journaling non dovrebbe essere disattivato nel primo caso, poiché ci vogliono solo 60 secondi per creare un nuovo checkpoint. Quindi, se si verifica un errore, MongoDB può riprodurre il journal per recuperare i dati persi entro questi secondi.
Il journaling generalmente riduce l'intervallo di tempo da quando i dati vengono applicati alla memoria fino a quando non sono durevoli su disco. L'oggetto storage.journal ha una proprietà che descrive la frequenza di commit, ovvero commitIntervalMs che è spesso impostato su un valore di 100 ms per WiredTiger. La regolazione su un valore più basso migliorerà la registrazione frequente delle scritture, riducendo così i casi di perdita di dati.
Blocco delle prestazioni
Ciò può essere causato da più richieste di lettura e scrittura da molti client. Quando ciò accade, è necessario mantenere la coerenza ed evitare conflitti di scrittura. Per raggiungere questo obiettivo MongoDB utilizza il blocco multi-granularità che consente di eseguire operazioni di blocco a diversi livelli, come globale, database o livello di raccolta.
Se disponi di schemi di progettazione dello schema scadenti, sarai vulnerabile ai blocchi mantenuti per lunghi periodi. Ciò si verifica spesso quando si eseguono due o più diverse operazioni di scrittura su un unico documento nella stessa raccolta, con la conseguenza di bloccarsi a vicenda. Per il motore di archiviazione WiredTiger possiamo utilizzare il sistema di ticket in cui le richieste di lettura o scrittura provengono da qualcosa come una coda o un thread.
Per impostazione predefinita, il numero simultaneo di operazioni di lettura e scrittura è definito dai parametri wiredTigerConcurrentWriteTransactions e wiredTigerConcurrentReadTransactions, entrambi impostati su un valore di 128.
Se ridimensioni questo valore troppo in alto, finirai per essere limitato dalle risorse della CPU. Per aumentare le operazioni di throughput, sarebbe consigliabile ridimensionare orizzontalmente fornendo più shard.
Multiplenines Diventa un DBA MongoDB - Portare MongoDB in produzioneScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare MongoDBScarica gratuitamenteUtilizzo delle risorse
Questo generalmente descrive l'uso delle risorse disponibili come la capacità della CPU/velocità di elaborazione e la RAM. Le prestazioni, in particolare per la CPU, possono cambiare drasticamente in base a carichi di traffico insoliti. Le cose da controllare includono...
- Numero di connessioni
- Stoccaggio
- Cache
Numero di connessioni
Se il numero di connessioni è superiore a quello che il sistema di database può gestire, ci saranno molte code. Di conseguenza, questo sovraccarica le prestazioni del database e rallenta l'esecuzione della configurazione. Questo numero può causare problemi con il driver o addirittura complicazioni con la tua applicazione.
Se controlli un certo numero di connessioni per un certo periodo e poi noti che quel valore ha raggiunto il picco, è sempre buona norma impostare un avviso se la connessione supera questo numero.
Se il numero sta diventando troppo alto, puoi aumentare per far fronte a questo aumento. Per fare ciò è necessario conoscere il numero di connessioni disponibili in un determinato periodo, altrimenti, se le connessioni disponibili non sono sufficienti, le richieste non verranno gestite in modo tempestivo.
Per impostazione predefinita MongoDB fornisce supporto per un massimo di 1 milione di connessioni. Con il tuo monitoraggio, assicurati sempre che le connessioni attuali non si avvicinino mai troppo a questo valore. Puoi controllare il valore nell'oggetto connessioni.

Stoccaggio
Ogni riga e record di dati in MongoDB viene definito documento. I dati del documento sono in formato BSON. Su un determinato database, se esegui il comando db.stats(), ti verranno presentati questi dati.
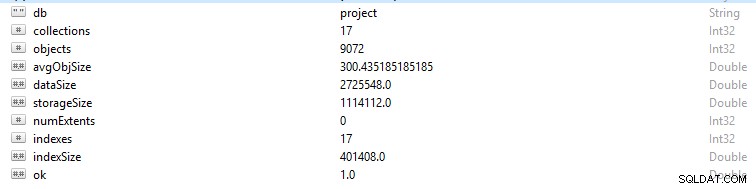
- StorageSize definisce la dimensione di tutte le estensioni di dati nel database.
- IndexSize delinea la dimensione di tutti gli indici creati all'interno di quel database.
- dataSize è una misura dello spazio totale occupato dai documenti nel database.
A volte puoi vedere un cambiamento nella memoria, specialmente se sono stati eliminati molti dati. In questo caso dovresti impostare un avviso per assicurarti che non sia dovuto ad attività dannose.
A volte, la dimensione complessiva dello spazio di archiviazione può aumentare mentre il grafico del traffico del database è costante e in questo caso, dovresti controllare la struttura dell'applicazione o del database per evitare di avere duplicati se non necessari.
Come la memoria generale di un computer, anche MongoDB dispone di cache in cui i dati attivi vengono temporaneamente archiviati. Tuttavia, un'operazione può richiedere dati che non si trovano in questa memoria attiva, effettuando quindi una richiesta dalla memoria del disco principale. Questa richiesta o situazione viene definita errore di pagina. Le richieste di errore di pagina hanno la limitazione di richiedere più tempo per l'esecuzione e possono essere dannose quando si verificano frequentemente. Per evitare questo scenario, assicurati che le dimensioni della tua RAM siano sempre sufficienti per soddisfare i set di dati con cui stai lavorando. Dovresti anche assicurarti di non avere ridondanza dello schema o indici non necessari.
Cache
La cache è un elemento di archiviazione dei dati temporali per i dati a cui si accede di frequente. In WiredTiger vengono spesso utilizzate la cache del file system e la cache del motore di archiviazione. Assicurati sempre che il tuo set di lavoro non si gonfi oltre la cache disponibile, altrimenti gli errori di pagina aumenteranno di numero causando alcuni problemi di prestazioni.
Ad un certo punto potresti decidere di modificare le tue operazioni frequenti, ma a volte le modifiche non si riflettono nella cache. Questi dati non modificati sono indicati come "Dati sporchi". Esiste perché non è stato ancora scaricato su disco. Si verificheranno colli di bottiglia se la quantità di "Dati sporchi" cresce fino a un valore medio definito da una scrittura lenta sul disco. L'aggiunta di più frammenti aiuterà a ridurre questo numero.
Utilizzo della CPU
L'indicizzazione impropria, la struttura dello schema scadente e le query progettate in modo ostile richiederanno una maggiore attenzione della CPU, quindi aumenteranno ovviamente il suo utilizzo.
Operazioni complete
In larga misura ottenere informazioni sufficienti su queste operazioni può consentire di evitare consequenziali battute d'arresto come errori, saturazione delle risorse e complicazioni funzionali.
Dovresti sempre prendere nota del numero di operazioni di lettura e scrittura nel database, ovvero una visione di alto livello delle attività del cluster. Conoscere il numero di operazioni generate per le richieste consentirà di calcolare il carico che il database dovrebbe gestire. Il carico può quindi essere gestito aumentando la scalabilità del database o aumentando la scalabilità orizzontale; a seconda del tipo di risorse che hai. Ciò consente di misurare facilmente il rapporto quoziente in cui le richieste si stanno accumulando e la velocità con cui vengono elaborate. Inoltre, puoi ottimizzare le tue query in modo appropriato per migliorare le prestazioni.
Per controllare il numero di operazioni di lettura e scrittura, eseguire questo comando db.serverStatus(), quindi passare all'oggetto locks.global, il valore della proprietà r rappresenta il numero di richieste di lettura e w il numero di scritture.
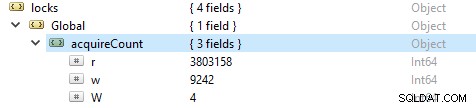
Più spesso le operazioni di lettura sono più delle operazioni di scrittura. Le metriche dei clienti attivi sono riportate in globalLock.
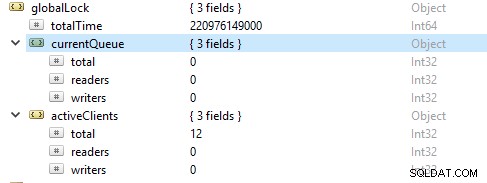
Saturazione e limitazione delle risorse
A volte il database potrebbe non riuscire a tenere il passo con la velocità di scrittura e lettura, come illustrato da un numero crescente di richieste in coda. In questo caso, devi aumentare il tuo database fornendo più shard per consentire a MongoDB di indirizzare le richieste abbastanza velocemente.
Emergenti battute d'arresto
I file di registro MongoDB forniscono sempre una panoramica generale sulle eccezioni di asserzione restituite. Questo risultato ti darà un indizio sulle possibili cause degli errori. Se esegui il comando db.serverStatus(), alcuni degli avvisi di errore che noterai includono:

- Affermazioni regolari:sono il risultato di un'operazione non riuscita. Ad esempio in uno schema se viene fornito un valore stringa a un campo intero, con conseguente errore nella lettura del documento BSON.
- Afferma di avviso:questi sono spesso avvisi su qualche problema ma non hanno un grande impatto sul suo funzionamento. Ad esempio, quando aggiorni il tuo MongoDB potresti essere avvisato utilizzando funzioni obsolete.
- Msg afferma:sono il risultato di eccezioni interne del server come una rete lenta o se il server non è attivo.
- Affermazioni utente:come le normali asserzioni, questi errori si verificano durante l'esecuzione di un comando ma vengono spesso restituiti al client. Ad esempio se ci sono chiavi duplicate, spazio su disco inadeguato o nessun accesso per scrivere nel database. Sceglierai di controllare la tua applicazione per correggere questi errori.



