Quando installi ClusterControl, ha una configurazione predefinita che forse non soddisfa i tuoi requisiti, quindi probabilmente dovrai personalizzare questa installazione. Per questo è possibile modificare i file di configurazione, ma anche controllare o modificare le impostazioni di ClusterControl di runtime. In questo blog, ti mostreremo dove puoi vedere questa configurazione e quali sono le opzioni disponibili da utilizzare qui.
Dove puoi vedere la configurazione del runtime di ClusterControl?
Ci sono due modi diversi per verificarlo. Per prima cosa, vai su ClusterControl -> Impostazioni globali -> Configurazioni runtime, quindi scegli il tuo Cluster.
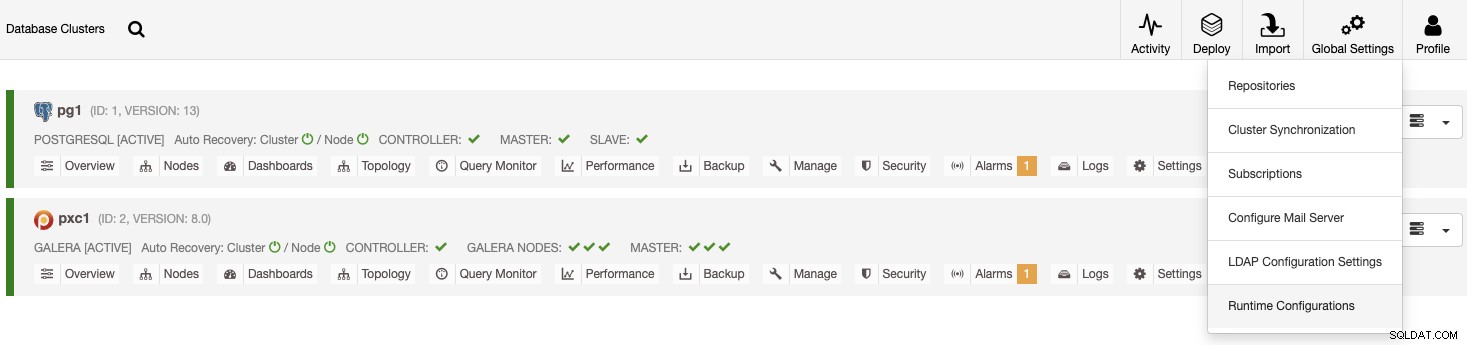
Un altro modo è ClusterControl -> Seleziona cluster -> Impostazioni -> Configurazioni runtime .
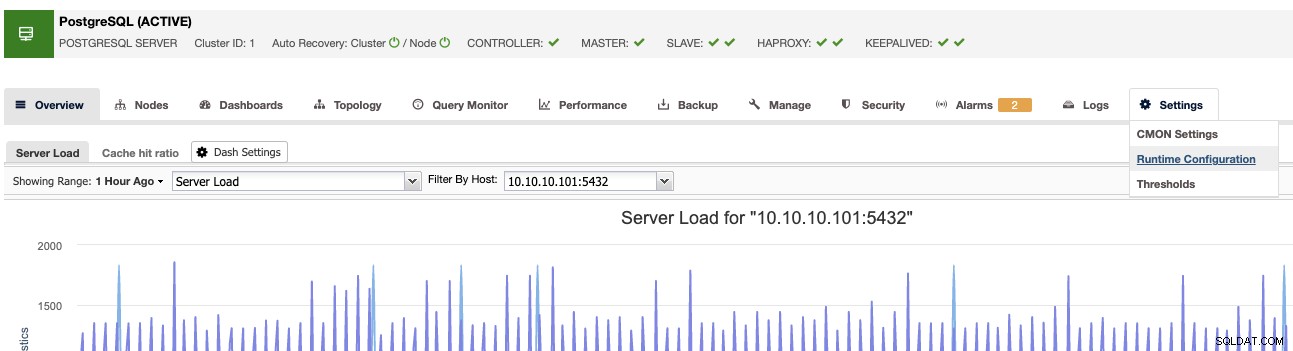
In entrambi i casi, andrai nello stesso posto, la configurazione del runtime sezione.
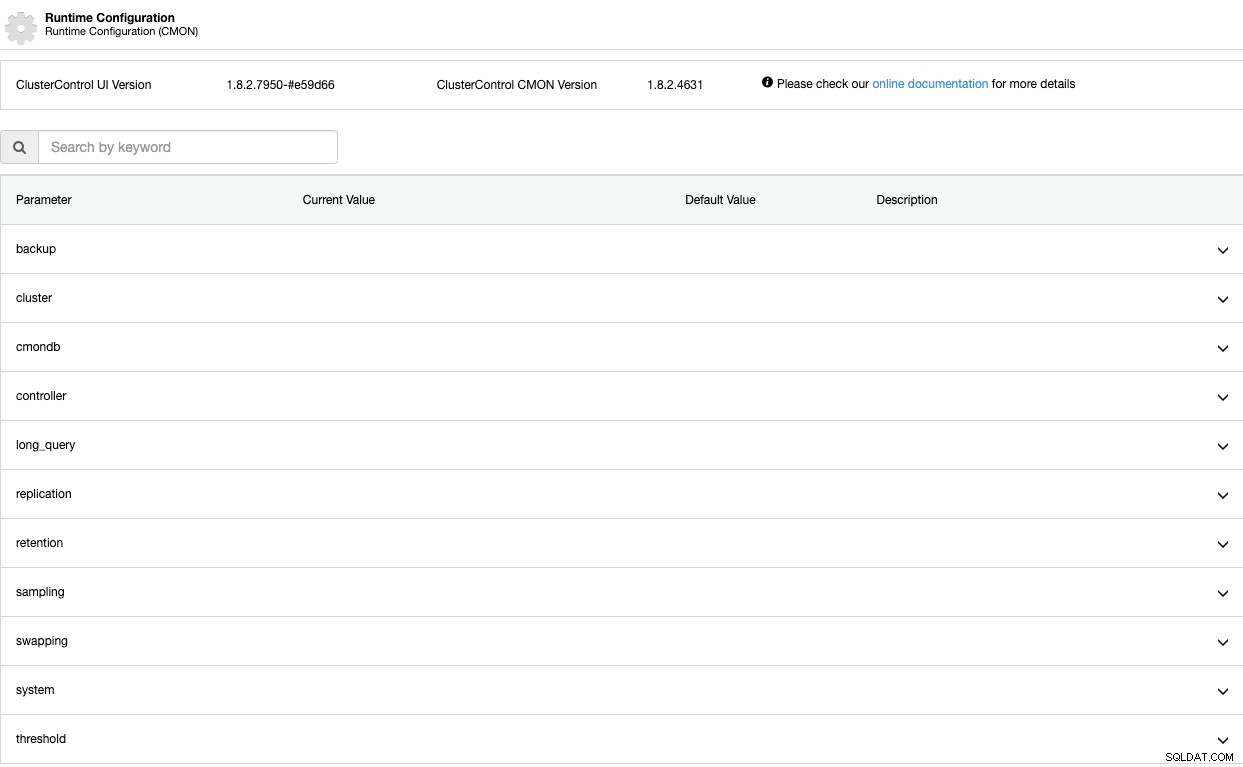
Parametri di configurazione del runtime
Ora, vediamo questi parametri uno per uno. Tieni presente che questi parametri dipendono dalla tecnologia di database che stai utilizzando, quindi molto probabilmente non li vedrai tutti contemporaneamente nello stesso cluster.
Backup
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| disable_backup_email | falso | Questa impostazione controlla se le email vengono inviate o meno se un backup è terminato o fallito. |
| utente_backup | utente di backup | Il nome utente dell'account del database utilizzato per la gestione dei backup. |
| backup_create_hash | vero | Configura ClusterControl se deve calcolare md5hash sui file di backup creati e verificarli. |
| pitr_retention_hours | 0 | Ore di conservazione (per cancellare i vecchi registri dell'archivio WAL) per PITR. |
| netcat_port | 9999,9990-9998 | Elenco di porte Netcat e intervalli di porte utilizzati per eseguire lo streaming dei backup. L'impostazione predefinita è "9999,9990-9998" e la porta 9999 sarà preferita se disponibile. |
| dir backup | /home/utente/backup | La directory di backup predefinita, da precompilare in Frontend. |
| backup_subdir | BACKUP-%I | Imposta il nome della sottodirectory di backup. Questa stringa può contenere separatori di campo "%X" standard, ad esempio "%06I" verrà sostituito dall'ID numerico del backup in formato 6 campi che utilizza "0" come caratteri di riempimento iniziali. Di seguito è riportato l'elenco dei campi attualmente supportati dal backend:- B La data e l'ora di inizio della creazione del backup. - H Il nome dell'host di backup, l'host che ha creato il backup. - i L'ID numerico del cluster. - I L'ID numerico del backup. - J L'ID numerico del lavoro che ha creato il backup. - M Il metodo di backup (ad es. "mysqldump"). - O Il nome dell'utente che ha avviato il processo di backup. - S Il nome dell'host di archiviazione, l'host che archivia i file di backup. - % Il segno di percentuale stesso. Usa due segni di percentuale, "%%" nello stesso modo in cui la funzione standard printf() lo interpreta come un segno di percentuale. |
| backup_retention | 31 | L'impostazione di quanti giorni conservare i backup. I backup corrispondenti al periodo di conservazione vengono rimossi. |
| backup_cloud_retention | 180 | L'impostazione di quanti giorni mantenere i backup caricati su un cloud. I backup corrispondenti al periodo di conservazione vengono rimossi. |
| backup_n_safety_copys | 1 | L'impostazione di quanti backup completi completati verranno conservati indipendentemente dal loro stato di conservazione. |
Gruppo
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| nome_cluster | Il nome del cluster per una facile identificazione. | |
| enable_node_autorecovery | vero | Impostazione di ripristino automatico del nodo. |
| enable_cluster_autorecovery | vero | Se true, ClusterControl eseguirà il ripristino automatico del cluster, se false non verrà eseguito automaticamente alcun ripristino del cluster. |
| configdir | /etc/ | La directory di configurazione del server del database. |
| created_by_job | L'ID del lavoro ha creato questo cluster. | |
| ssh_keypath | /home/user/.ssh/id_rsa | Il file della chiave SSH utilizzato per la connessione ai nodi. |
| server_selection_try_once | vero | Opzione URI connessione MongoDB. Definisce se la selezione del server deve essere ripetuta in caso di errore fino alla scadenza di un timeout di selezione del server o se deve essere restituita immediatamente con un errore. |
| selezione_server_timeout_ms | 30000 | Opzione URI connessione MongoDB. Definisce il valore di timeout fino a quando mongodriver dovrebbe tentare di eseguire con successo un'operazione di selezione del server. |
| proprietario | L'ID utente ClusterControl del proprietario dell'oggetto cluster. | |
| proprietario_gruppo | L'ID gruppo ClusterControl del gruppo che possiede l'oggetto cluster. | |
| percorso_cdt | La posizione dell'oggetto cluster nella struttura della directory ClusterControl. | |
| tag | / | Un insieme di stringhe che l'utente può specificare. |
| acl | L'elenco di controllo di accesso come stringa che controlla l'accesso all'oggetto cluster. | |
| mongodb_user | admindb | Il nome utente MongoDB. |
| mongodb_basedir | /usr/ | Il basedir per l'installazione di MongoDB. |
| mysql_basedir | /usr/ | La base per l'installazione di MySQL. |
| dir script | /usr/bin/ | La directory degli script dell'installazione di MySQL. |
| dir_staging | /home/user/s9s_tmp | Un percorso di gestione temporanea per i file temporanei. |
| raccoglitore | /usr/bin | La directory /bin dell'installazione di MySQL. |
| porta_mysql_monitorata | 3306 | Numero di porta del server MySQL monitorato. |
| ndb_connectstring | 127.0.0.1:1186 | L'impostazione della stringa di connessione NDB per MySQL Cluster. |
| ndbd_datadir | La datadir dei nodi NDBD. | |
| mgmd_datadir | La datadir dei nodi NDB MGMD. | |
| os_user | Il nome utente SSH utilizzato per accedere ai nodi. | |
| repl_user | cmon_replication | Il nome utente della replica. |
| fornitore | Il nome del fornitore del database utilizzato per le distribuzioni. | |
| versione_galera | Il numero di versione di Galera utilizzato. | |
| versione_server | La versione del server di database utilizzata per le distribuzioni. | |
| postgresql_user | admindb | Il nome utente di PostgreSQL. |
| galera_port | 4567 | La porta galera da utilizzare quando si aggiungono nodi/garbd e si costruisce wsrep_cluster_address. Non modificare in fase di esecuzione. |
| auto_manage_readonly | vero | Consenti a ClusterControl di gestire il flag di sola lettura dei server MySQL gestiti. |
| node_recovery_lock_file | Specificare un file di blocco e se presente su un nodo, il nodo non verrà ripristinato. È responsabilità dell'amministratore creare/rimuovere il file. |
Cmondb
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| cmon_db | cmon | Il nome del database ClusterControl locale. |
| cmondb_hostname | 127.0.0.1 | Il nome host del server MySQL del database ClusterControl locale. |
| mysql_port | 3306 | La porta del server MySQL del database ClusterControl locale. |
| cmon_user | cmon | Il nome dell'account per accedere al database ClusterControl locale. |
Controllore
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| controller_id | 5a3a993d-xxxx | Una stringa identificativa arbitraria di questa istanza del controller. |
| cmon_hostname | 192.168.xx.xx | Il nome host del controller. |
| error_report_dir | /home/user/s9s_tmp | Posizione di archiviazione dei rapporti di errore. |
Query_lunga
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| long_query_time | 0.5 | Valore di soglia per il controllo delle query lente. |
| query_monitor_alert_long_running_query | vero | Genera un allarme se una query viene eseguita per un periodo superiore a query_monitor_long_running_query_ms. |
| query_monitor_kill_long_running_query | falso | Chiudi la query se la query è stata eseguita per più di query_monitor_long_running_query_ms. |
| query_monitor_long_running_query_time_ms | 30000 | Genera un allarme se una query viene eseguita per un periodo superiore a query_monitor_long_running_query_ms. Il valore minimo è 1000. |
| query_monitor_long_running_query_matching_info | Corrisponde solo alle query con un 'Info' che corrisponde solo a questa espressione regolare POSIX. Nessun valore predefinito, corrisponde a qualsiasi Info. | |
| query_monitor_long_running_query_matching_info_negate | falso | Nega il risultato di query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Corrisponde solo alle query con un 'Host' che corrisponde solo a questa espressione regolare POSIX. Nessun valore predefinito, corrisponde a qualsiasi Host. | |
| query_monitor_long_running_query_matching_db | Corrisponde solo alle query con un 'Db' che corrisponde solo a questa espressione regolare POSIX. Nessun valore predefinito, corrisponde a qualsiasi Db. | |
| query_monitor_long_running_query_matching_user | Corrisponde solo alle query con un 'Utente' che corrisponde solo a questa espressione regolare POSIX. Nessun valore predefinito, corrisponde a qualsiasi Utente. | |
| query_monitor_long_running_query_matching_user_negate | falso | Nega il risultato di query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Interroga | Corrisponde solo alle query con un 'Comando' che corrisponde solo a questa espressione regolare POSIX. L'impostazione predefinita è "Query". |
Replica
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| max_replication_lag | 10 | Massimo ritardo di replica consentito in secondi prima dell'invio di un allarme. |
| replication_stop_on_error | vero | Controlla se le procedure di failover/switchover devono fallire se si verificano errori che possono causare la perdita di dati. |
| replica_auto_rebuild_slave | falso | Se il THREAD SQL viene interrotto e il codice di errore è diverso da zero, lo slave verrà ricostruito automaticamente. |
| replication_failover_blacklist | Elenco separato da virgole di hostname:coppie di porte. I server inseriti nella lista nera non saranno considerati candidati durante il failover. replication_failover_blacklist viene ignorato se è impostata replication_failover_whitelist. | |
| replication_failover_whitelist | Elenco separato da virgole di hostname:coppie di porte. Solo i server autorizzati verranno considerati candidati durante il failover. Se nessun server nella whitelist è disponibile (attivo/connesso), il failover avrà esito negativo. replication_failover_blacklist viene ignorato se è impostata replication_failover_whitelist. | |
| replication_onfail_failover_script | Questo script viene eseguito non appena viene scoperto che è necessario il failover. Se lo script restituisce un valore diverso da zero o non esiste, il failover verrà interrotto. Quattro argomenti vengono forniti allo script e impostati se sono noti, altrimenti vuoti:arg1='tutti i server' arg2='master fallito' arg3='candidato selezionato', arg4='slaves of oldmaster (i candidati)' e passati come this:'scripname arg1 arg2 arg3 arg4' Lo script deve essere accessibile sul controller ed eseguibile. | |
| replication_pre_failover_script | Questo script viene eseguito prima che avvenga il failover, ma dopo che un candidato è stato eletto ed è possibile continuare il processo di failover. Se lo script restituisce un valore diverso da zero o non esiste, il failover verrà interrotto. Quattro argomenti vengono forniti allo script e impostati se sono noti, altrimenti vuoti:arg1='tutti i server' arg2='master fallito' arg3='candidato selezionato', arg4='slaves of oldmaster (i candidati)' e passati come this:'scripname arg1 arg2 arg3 arg4' Lo script deve essere accessibile sul controller ed eseguibile. | |
| replication_post_failover_script | Questo script viene eseguito dopo che si verifica il failover (viene eletto un nuovo master attivo e funzionante). Se lo script restituisce un valore diverso da zero o non esiste, il failover verrà interrotto. Vengono forniti quattro argomenti allo script e impostati se sono noti, altrimenti vuoti.:arg1='tutti i server' arg2='master fallito' arg3='candidato selezionato', arg4='slaves of oldmaster (i candidati)' e passati in questo modo:'scripname arg1 arg2 arg3 arg4' Lo script deve essere accessibile sul controller ed eseguibile. | |
| replication_post_unsuccessful_failover_script | Questo script viene eseguito se il tentativo di failover fallisce. Se lo script restituisce un valore diverso da zero o non esiste, il failover verrà interrotto. Vengono forniti quattro argomenti allo script e impostati se sono noti, altrimenti vuoti.:arg1='tutti i server' arg2='master fallito' arg3='candidato selezionato', arg4='slaves of oldmaster (i candidati)' e passati in questo modo:'scripname arg1 arg2 arg3 arg4' Lo script deve essere accessibile sul controller ed eseguibile. |
Conservazione
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| ops_report_retention | 31 | L'impostazione di quanti giorni mantenere i rapporti operativi. I rapporti corrispondenti al periodo di conservazione vengono rimossi. |
Campionamento
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| enable_icmp_ping | vero | Commuta se ClusterControl deve misurare i tempi di ping ICMP sull'host. |
| host_stats_collection_interval | 30 | Impostazione per l'intervallo di raccolta dell'host (CPU, memoria, ecc.). |
| host_stats_window_size | 180 | Impostazione della dimensione della finestra (in secondi) per esaminare le statistiche per aumentare/cancellare gli allarmi delle statistiche dell'host. |
| db_stats_collection_interval | 30 | Impostazione per l'intervallo di raccolta delle statistiche del database. |
| db_proc_stats_collection_interval | 5 | Impostazione per l'intervallo di raccolta delle statistiche di processo del database. Il valore minimo consentito è 1 secondo. Richiede il riavvio del servizio cmon. |
| lb_stats_collection_interval | 15 | Impostazione per l'intervallo di raccolta delle statistiche del bilanciamento del carico. |
| db_schema_stats_collection_interval | 108000 | Impostazione per l'intervallo di monitoraggio delle statistiche dello schema. |
| db_deadlock_check_interval | 0 | Quanto spesso controllare i deadlock. Specificato in secondi. Il rilevamento del deadlock influirà sull'utilizzo della CPU sui nodi del database. |
| log_collection_interval | 600 | Controlla l'intervallo tra le raccolte di file di registro. |
| db_hourly_stats_collection_interval | 5 | Controlla quanti secondi ci sono tra ogni singolo campione nelle statistiche dell'intervallo orario. |
| punti di montaggio_monitorati | L'elenco dei punti di montaggio da monitorare. | |
| monitor_cpu_temperature | falso | Monitoraggio della temperatura della CPU. |
| log_queries_not_using_indexes | falso | Imposta il monitoraggio delle query in modo che rilevi le query che non utilizzano gli indici. |
| query_sample_interval | 1 | Controlla l'intervallo di monitoraggio delle query in secondi, -1 significa nessun monitoraggio delle query. |
| query_monitor_auto_purge_ps | falso | Se abilitata, la tabella P_S events_statements_summary_by_digest verrà eliminata automaticamente (TRUNCATE TABLE) ogni ora. |
| schema_change_detection_address | Verranno eseguiti controlli (usando SHOW TABLES/SHOW CREATE TABLE) per determinare se lo schema è cambiato. I controlli vengono eseguiti sull'indirizzo specificato e sono nel formato HOSTNAME:PORT. È necessario impostare anche lo schema_change_detection_databases. Viene creata una differenza di una tabella modificata. | |
| schema_change_detection_databases | Elenco separato da virgole di database da monitorare per le modifiche allo schema. Se vuoto, non vengono effettuati controlli. | |
| schema_change_detection_pause_time_ms | 0 | Tempo di pausa in ms tra ogni SHOW CREATE TABLE. Il tempo di pausa influenzerà la durata del processo di rilevamento. |
| enable_is_queries | vero | Specifica se le query allo schema_informazioni verranno eseguite o meno. Le query allo schema_informazioni potrebbero non essere adatte quando si hanno molti oggetti schema (centinaia di database, centinaia di tabelle in ogni database, trigger, utenti, eventi, sprocs). Se disabilitata, la query che verrebbe eseguita verrà registrata in modo da poter determinare se la query è adatta al tuo ambiente. |
Scambio
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| swap_warning | 20 | Soglia di avviso per l'utilizzo dello scambio. |
| swap_critical | 90 | Soglia di allarme critica per l'utilizzo dello scambio. |
| swap_inout_period | 0 | L'intervallo per lo scambio di allarmi I/O (<=0 disabilitato). |
| swap_inout_warning | 10240 | Il numero di pagine scambiate I/O nell'intervallo specificato (swap_inout_period, per impostazione predefinita 10 minuti) per l'avviso. |
| swap_inout_critical | 102400 | Il numero di pagine scambiate I/O nell'intervallo specificato (swap_inout_period, per impostazione predefinita 10 minuti) per critico. |
Sistema
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| cmon_config_path | /etc/cmon.d/cmon_x.cnf | Il percorso del file di configurazione. Questo valore di configurazione è di sola lettura. |
| os | debian/redhat | Il tipo di sistema operativo. I valori possibili sono 'debian' o 'redhat'. |
| libssh_timeout | 30 | Il valore di timeout di rete per le connessioni SSH. |
| sudo | sudo -n 2>/dev/null | Il comando utilizzato per ottenere i privilegi di superutente. |
| ssh_port | 22 | La porta per le connessioni SSH ai nodi. |
| nome_repo_locale | I nomi dei repository locali utilizzati per la distribuzione del cluster. | |
| frontend_url | L'URL inviato nelle e-mail per indirizzare il destinatario all'interfaccia web di ClusterControl. | |
| elimina | 7 | Per quanto tempo ClusterControl conserverà i dati. Misurati in giorni, lavori, messaggi di lavoro, allarmi, registri raccolti, rapporti operativi, informazioni sulla crescita del database precedenti a questo verranno eliminati. |
| os_user_home | /home/utente | La directory HOME dell'utente utilizzato sui nodi. |
| cmon_mail_sender | Il mittente e-mail utilizzato per le e-mail inviate. | |
| plugin_dir | Il percorso della directory dei plugin. | |
| use_internal_repos | falso | Impostazione che ha disabilitato la configurazione del repository di terze parti. |
| cmon_use_mail | falso | Impostazione per utilizzare il comando 'mail' per l'invio di e-mail. |
| enable_html_emails | vero | Abilita l'invio di email HTML. |
| send_clear_alarm | vero | Commuta l'invio dell'e-mail in caso di cancellazione degli allarmi del cluster. |
| dir pacchetto_software | Questa è la posizione di archiviazione dei pacchetti software, ovvero tutti i file necessari per installare correttamente un nodo, se non è disponibile un repository yum/apt, devono essere collocati qui. Si applica principalmente a MySQL Cluster o alle precedenti installazioni Codership/Galera. |
Soglia
| Nome | Valore predefinito | Descrizione |
|---|---|---|
| ram_warning | 80 | Soglia di avviso di allarme per l'utilizzo della RAM. |
| ram_critical | 90 | Soglia di allarme critica per l'utilizzo della RAM. |
| avviso_spazio_disco | 80 | Soglia di avviso di allarme per l'utilizzo del disco. |
| spazio su disco_critico | 90 | Soglia di allarme critica per l'utilizzo del disco. |
| cpu_warning | 80 | Soglia di avviso per l'utilizzo della CPU. |
| cpu_critical | 90 | Soglia di allarme critica per l'utilizzo della CPU. |
| cpu_steal_warning | 10 | Soglia di avviso di allarme per furto della CPU. |
| cpu_steal_critical | 20 | Soglia di allarme critica per il furto della CPU. |
| cpu_iowait_warning | 50 | Soglia di avviso di allarme per CPU IO Wait. |
| cpu_iowait_critical | 60 | Soglia di allarme critico per CPU IO Wait. |
| slow_ssh_warning | 6 | Verrà generato un avviso di avviso se è necessario più tempo del tempo specificato per impostare una connessione SSH (sec). |
| slow_ssh_critical | 12 | Verrà generato un allarme critico se la configurazione di una connessione SSH impiega più tempo del tempo specificato (sec). |
Conclusione
Come puoi vedere, ci sono molti parametri da modificare se devi adattare ClusterControl al tuo carico di lavoro o al tuo business. Potrebbe essere un'attività dispendiosa in termini di tempo rivedere tutti i valori e modificarli di conseguenza, ma alla fine della giornata si farà risparmiare tempo poiché è possibile ottenere il massimo da tutte le funzionalità di ClusterControl.



