Non esiste un limite codificato rilevante (65.536 * La dimensione del pacchetto di rete di 4 KB è 268 MB e la lunghezza dello script non è affatto vicina a quella) sebbene sia sconsigliabile utilizzare questo metodo per una grande quantità di righe.
L'errore visualizzato viene generato dagli strumenti client non da SQL Server. Se costruisci la stringa SQL nella compilazione SQL dinamica è in grado almeno di avviarsi correttamente
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
Anche se ho ucciso quanto sopra dopo circa 30 minuti di compilazione e non aveva ancora prodotto una riga. I valori letterali devono essere archiviati all'interno del piano stesso come tabella di costanti e SQL Server spende molto tempo cercando di ricavare proprietà anche su di loro.
SSMS è un'applicazione a 32 bit e genera un std::bad_alloc eccezione durante l'analisi del batch
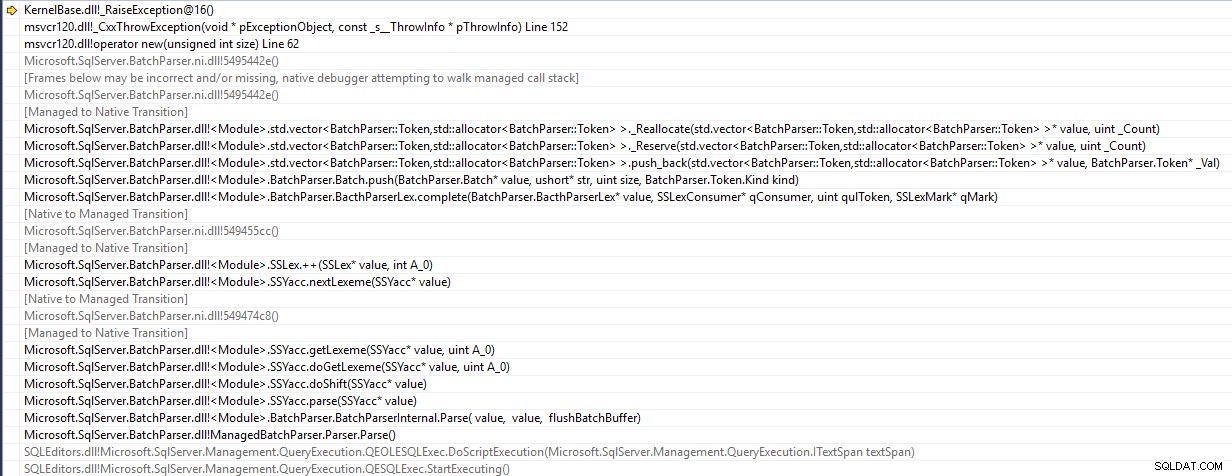
Cerca di spingere un elemento su un vettore di Token che ha raggiunto la capacità e il suo tentativo di ridimensionamento fallisce a causa dell'indisponibilità di un'area di memoria sufficientemente ampia e contigua. Quindi la dichiarazione non arriva nemmeno al server.
La capacità del vettore aumenta ogni volta del 50% (cioè seguendo la sequenza qui ). La capacità di cui il vettore deve crescere dipende da come è strutturato il codice.
Quanto segue deve crescere da una capacità di 19 a 28.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
e quanto segue richiede solo una dimensione di 2
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Quanto segue necessita di una capacità di> 63 e <=94.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
Per un milione di righe disposte come nel caso 1 la capacità del vettore deve crescere fino a 3.543.306.
Potresti scoprire che una delle seguenti opzioni consentirà all'analisi lato client di avere successo.
- Riduci il numero di interruzioni di riga.
- Riavvio di SSMS nella speranza che la richiesta di memoria contigua di grandi dimensioni abbia esito positivo quando la frammentazione dello spazio degli indirizzi è inferiore.
Tuttavia, anche se lo invii correttamente al server, finirà per uccidere il server solo durante la generazione del piano di esecuzione, come discusso sopra.
Farai molto meglio usando la procedura guidata di importazione e esportazione per caricare la tabella. Se devi farlo in TSQL, scoprirai che suddividerlo in batch più piccoli e/o utilizzare un altro metodo come la distruzione di XML funzionerà meglio dei costruttori con valori di tabella. Ad esempio, quanto segue viene eseguito in 13 secondi sulla mia macchina (sebbene se si utilizza SSMS è probabile che sia comunque necessario suddividere in più batch anziché incollare una stringa XML di grandi dimensioni letterale).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)