Motivo del problema :
TOKEN metodo in SSIS utilizza l'implementazione di strtok funzione in C++ . Ho raccolto queste informazioni durante la lettura del libro Microsoft® SQL Server® 2012 Integration Services
. È menzionato come nota a pagina 113 (Mi piace questo libro! Molte belle informazioni. ).
Ho cercato l'implementazione di strtok funzione e ho trovato i seguenti link.
INFO:strtok():Funzione C -- Supplemento alla documentazione - L'esempio di codice in questo collegamento mostra che la funzione ignora i caratteri delimitatori consecutivi.
Le risposte alle seguenti domande SO sottolineano che strtok la funzione è progettata per ignorare i delimitatori consecutivi.
comportamento di strtok_s con delimitatori consecutivi
Penso che il TOKEN e TOKENCOUNT le funzioni funzionano come previsto, ma se è così che dovrebbe comportarsi SSIS potrebbe essere una domanda per il team Microsoft SSIS.
Post originale - La sezione sopra è un aggiornamento:
Ho creato un semplice pacchetto in SSIS 2012 basato sui tuoi dati immessi. Come hai descritto nella tua domanda, il TOKEN la funzione non si comporta come previsto. Sono d'accordo con te che la funzione non sembra funzionare. Questo post non una risposta al tuo problema originale.
Ecco un modo alternativo per scrivere l'espressione in un modo relativamente più semplice. Funzionerà solo se l'ultimo segmento nel record di input avrà sempre un valore (ad esempio A1 , B2 , C3 ecc.).
L'espressione può essere riscritta come :
Questa istruzione prenderà il record di input come parametro, il cursore delimitatore (^) come secondo parametro. Il terzo parametro calcola il numero totale di segmenti nei record quando sono divisi per il delimitatore. Se disponi di dati nell'ultimo segmento, hai la garanzia di avere due segmenti. Puoi quindi sottrarre 1 per recuperare il penultimo segmento.
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
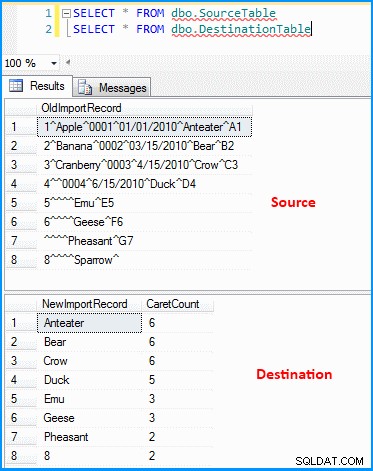
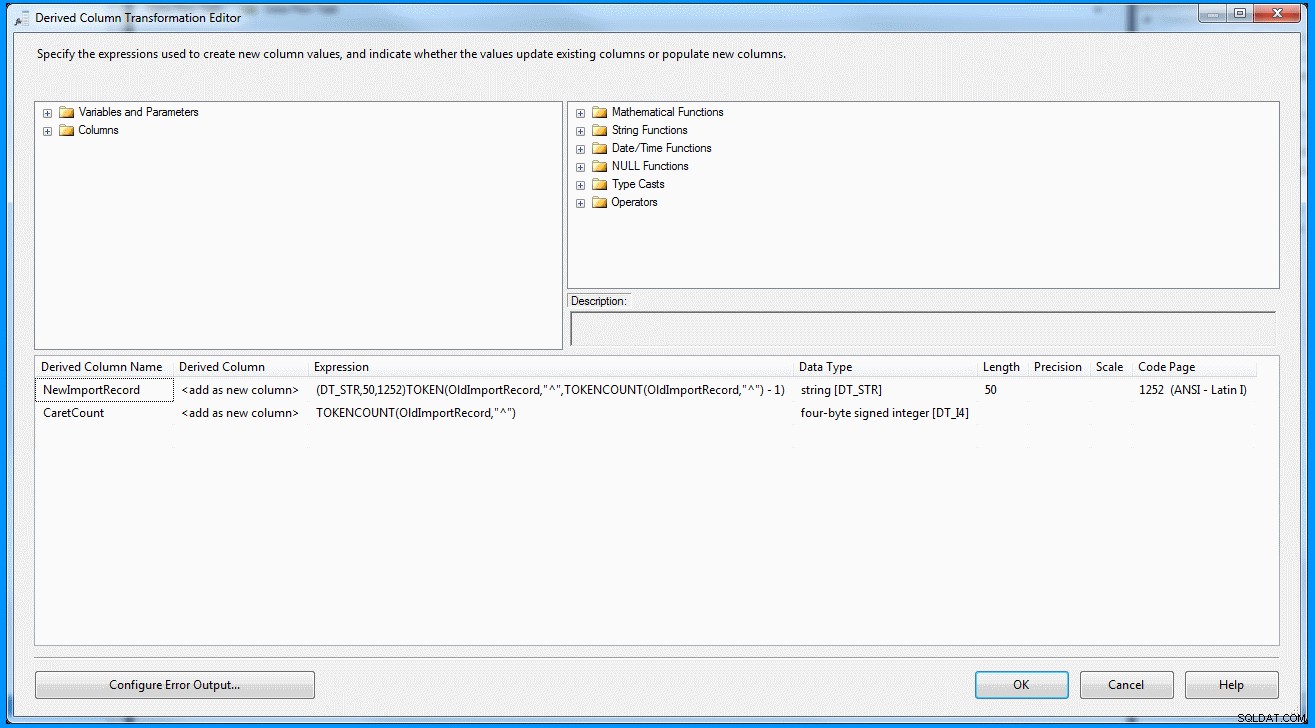
Ho creato un semplice pacchetto con attività di flusso di dati. L'origine OLE DB recupera i dati e la trasformazione derivata analizza e divide i dati secondo lo screenshot seguente. L'output viene quindi inserito nella tabella di destinazione. Puoi vedere le tabelle di origine e di destinazione nell'ultimo screenshot. La tabella di destinazione ha due colonne. La prima colonna memorizza i dati del penultimo segmento e i segmenti contano in base al delimitatore (che di nuovo non è corretto). Puoi notare che l'ultimo record non ha ottenuto i risultati corretti. Se l'ultimo record non aveva il valore 8 , l'espressione precedente avrà esito negativo perché l'espressione restituirà un indice zero.
Spero che questo aiuti a semplificare la tua espressione.
Se non hai notizie da nessun altro, ti consiglio di registrare questo problema nel sito Web Microsoft Connect> .
Crea tabelle e compila script :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Trasformazione derivata della colonna all'interno dell'attività del flusso di dati :
Dati nelle tabelle di origine e di destinazione :