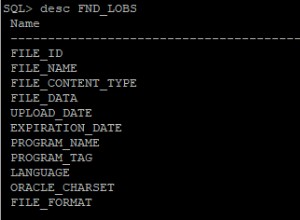
In realtà, per come l'hai scritta, la tua prima opzione sarà più veloce.
-
Il tuo secondo esempio ha un problema. Stai facendo sql =+ sql + ecc. Ciò causerà la creazione di un nuovo oggetto stringa per ogni iterazione del ciclo. (Dai un'occhiata alla classe StringBuilder). Tecnicamente, in prima istanza creerai anche un nuovo oggetto stringa, ma la differenza è che non è necessario copiare tutte le informazioni dall'opzione stringa precedente.
-
Il modo in cui lo hai impostato, SQL Server dovrà potenzialmente valutare una query enorme quando finalmente la invii, il che richiederà sicuramente del tempo per capire cosa dovrebbe fare. Dovrei affermare, questo dipende da quanto è grande il numero di inserti che devi fare. Se n è piccolo, probabilmente starai bene, ma man mano che cresce il tuo problema peggiorerà.
Gli inserimenti in blocco sono più veloci di quelli individuali a causa del modo in cui SQL Server gestisce le transazioni batch. Se intendi inserire dati da C#, dovresti adottare il primo approccio e avvolgere, ad esempio, ogni 500 inserimenti in una transazione e eseguirne il commit, quindi eseguire i 500 successivi e così via. Questo ha anche il vantaggio che se un batch fallisce, puoi intercettarli e capire cosa è andato storto e reinserire solo quelli. Ci sono altri modi per farlo, ma sarebbe sicuramente un miglioramento rispetto ai due esempi forniti.
var iCounter = 0;
foreach (Employee item in employees)
{
if (iCounter == 0)
{
cmd.BeginTransaction;
}
string sql = @"INSERT INTO Mytable (id, name, salary)
values ('@id', '@name', '@salary')";
// replace @par with values
cmd.CommandText = sql; // cmd is IDbCommand
cmd.ExecuteNonQuery();
iCounter ++;
if(iCounter >= 500)
{
cmd.CommitTransaction;
iCounter = 0;
}
}
if(iCounter > 0)
cmd.CommitTransaction;