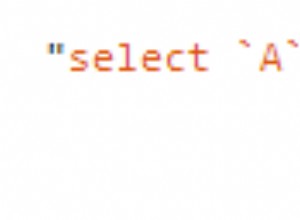
Due soluzioni, entrambe per trasformare il problema in uno più semplice. Di solito preferirei il T1 soluzione se è accettabile forzare un cambiamento sui consumatori:
create table dbo.T1 (
Lft int not null,
Rgt int not null,
constraint CK_T1 CHECK (Lft < Rgt),
constraint UQ_T1 UNIQUE (Lft,Rgt)
)
go
create table dbo.T2 (
Lft int not null,
Rgt int not null
)
go
create view dbo.T2_DRI
with schemabinding
as
select
CASE WHEN Lft<Rgt THEN Lft ELSE Rgt END as Lft,
CASE WHEN Lft<Rgt THEN Rgt ELSE Lft END as Rgt
from dbo.T2
go
create unique clustered index IX_T2_DRI on dbo.T2_DRI(Lft,Rgt)
go
In entrambi i casi, né T1 né T2 può contenere valori duplicati in Lft,Rgt coppie.