Per rispondere a questa domanda, guarda i piani di query prodotti da entrambi.
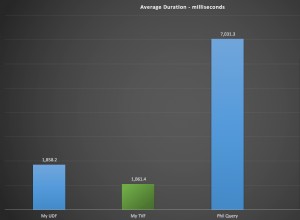
Il primo SELECT è una semplice scansione della tabella, il che significa che produce righe in ordine di allocazione. Poiché si tratta di una nuova tabella, corrisponde all'ordine in cui hai inserito i record.
Il secondo SELECT aggiunge un GROUP BY, che SQL Server implementa tramite un ordinamento distinto poiché il conteggio delle righe stimato è così basso. Se dovessi avere più righe o aggiungere un aggregato al tuo SELECT, questo operatore potrebbe cambiare.
Ad esempio, prova:
CREATE TABLE #Values ( FieldValue varchar(50) )
;WITH FieldValues AS
(
SELECT '4' FieldValue UNION ALL
SELECT '3' FieldValue UNION ALL
SELECT '2' FieldValue UNION ALL
SELECT '1' FieldValue
)
INSERT INTO #Values ( FieldValue )
SELECT
A.FieldValue
FROM FieldValues A
CROSS JOIN FieldValues B
CROSS JOIN FieldValues C
CROSS JOIN FieldValues D
CROSS JOIN FieldValues E
CROSS JOIN FieldValues F
SELECT
FieldValue
FROM #Values
GROUP BY
FieldValue
DROP TABLE #Values
A causa del numero di righe, questo si trasforma in un aggregato hash e ora non è presente alcun ordinamento nel piano di query.
Senza ORDER BY, SQL Server può restituire i risultati in qualsiasi ordine e l'ordine in cui ritorna è un effetto collaterale di come pensa di poter restituire i dati più rapidamente.