Questa non è tecnicamente una risposta, ma dato che mi sono preso del tempo per analizzarla, potrei anche pubblicarla (anche se corro il rischio di essere declassato).
Non c'era modo di riprodurre il comportamento descritto.
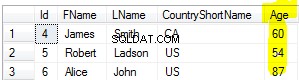
Questo è lo scenario:
declare @table table ([user id] int)
insert into @table values
(1),(1),(1),(1),(1),(1),(1),(2),(2),(2),(2),(2),(2),(null),(null)
Ed ecco alcune query e i relativi risultati:
SELECT COUNT(User ID) FROM @table --error: this does not run
SELECT COUNT(dsitinct User ID) FROM @table --error: this does not run
SELECT COUNT([User ID]) FROM @table --result: 13 (nulls not counted)
SELECT COUNT(distinct [User ID]) FROM @table --result: 2 (nulls not counted)
E qualcosa di interessante:
SELECT user --result: 'dbo' in my sandbox DB
SELECT count(user) from @table --result: 15 (nulls are counted because user value
is not null)
SELECT count(distinct user) from @table --result: 1 (user is the same
value always)
Trovo molto strano che tu sia in grado di eseguire le query esattamente come hai descritto. Dovresti farci sapere la struttura della tabella e i dati per ottenere ulteriore aiuto.