Completamente d'accordo con @PaulStock sul fatto che è meglio lasciare gli aggregati ai sistemi di origine. Un aggregato in SSIS è un componente di blocco completo molto simile a un ordinamento e ho ho già fatto la mia argomentazione su questo punto .
Ma ci sono momenti in cui queste operazioni nel sistema di origine non funzioneranno. Il meglio che sono stato in grado di trovare è stato sostanzialmente raddoppiare l'elaborazione dei dati. Sì, ick, ma non sono mai stato in grado di trovare un modo per far passare una colonna inalterato. Per gli scenari Min/Max, lo vorrei come opzione, ma ovviamente qualcosa come una Sum renderebbe difficile per il componente sapere a quale riga "sorgente" si legherebbe.
2005
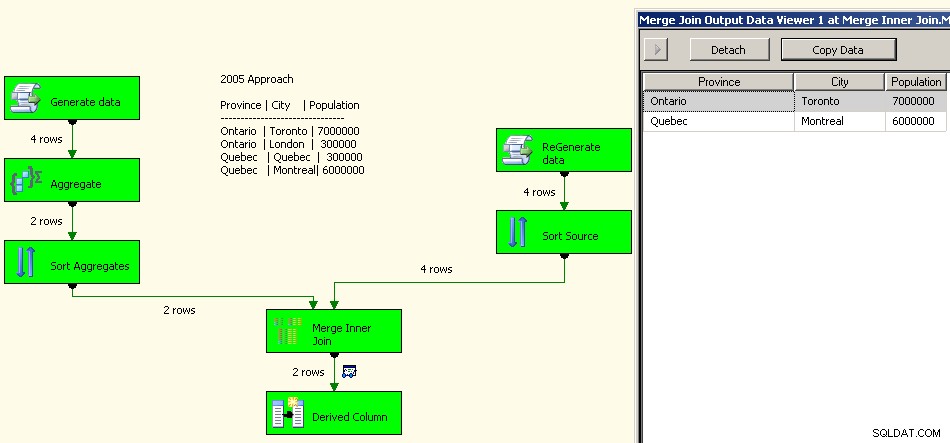
Un'implementazione del 2005 sarebbe simile a questa. Le tue prestazioni non saranno buone, in effetti a pochi ordini di grandezza da buone poiché avrai tutte queste trasformazioni di blocco lì oltre a dover rielaborare i tuoi dati di origine.
Unisci unisciti 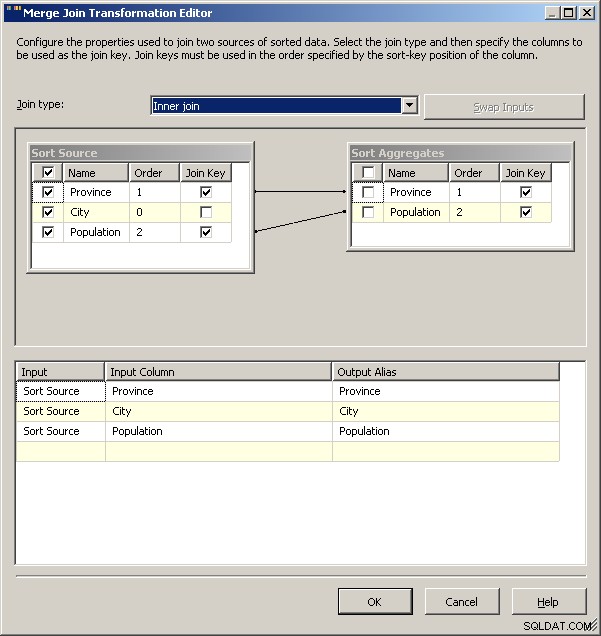
2008
Nel 2008 hai la possibilità di utilizzare Gestione connessione cache il che aiuterebbe a eliminare le trasformazioni di blocco, almeno dove conta, ma dovrai comunque pagare il costo della doppia elaborazione dei dati di origine.
Trascina due flussi di dati sull'area di disegno. Il primo popolerà il gestore della connessione della cache e dovrebbe essere il luogo in cui avviene l'aggregazione.
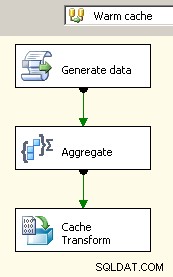
Ora che la cache contiene i dati aggregati, rilascia un'attività di ricerca nel flusso di dati principale ed esegui una ricerca nella cache.
Scheda di ricerca generale
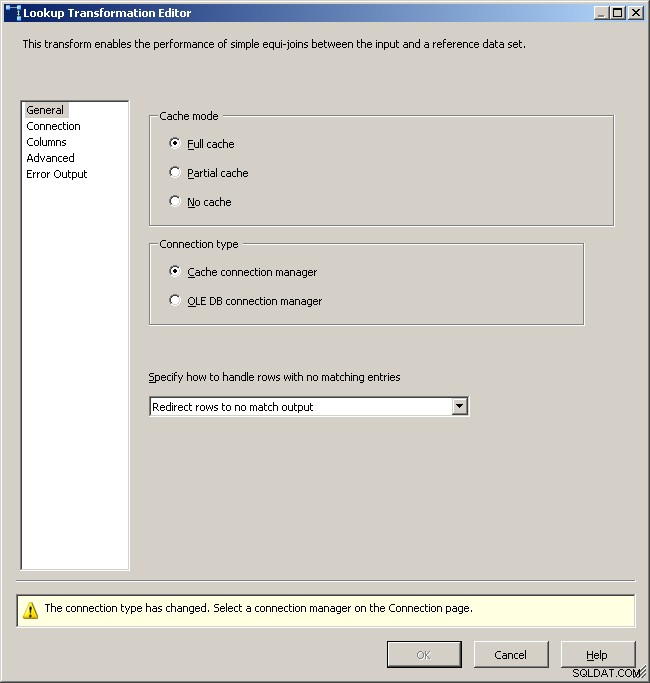
Seleziona il gestore della connessione cache
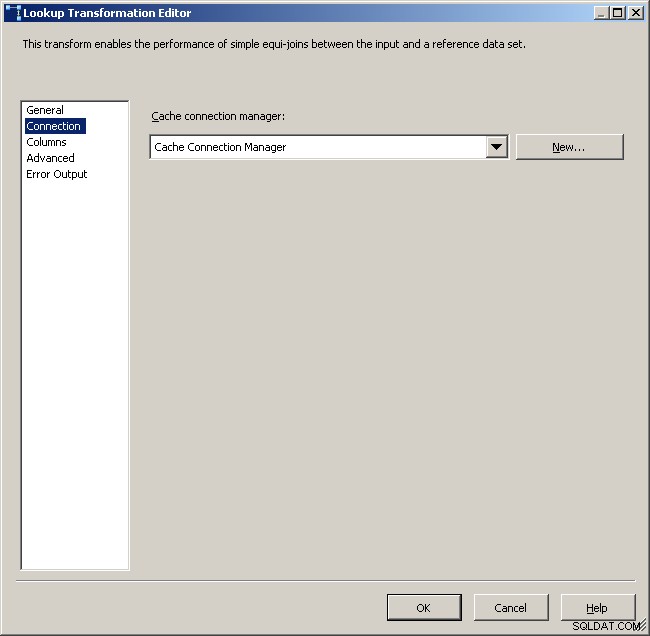
Mappa le colonne appropriate
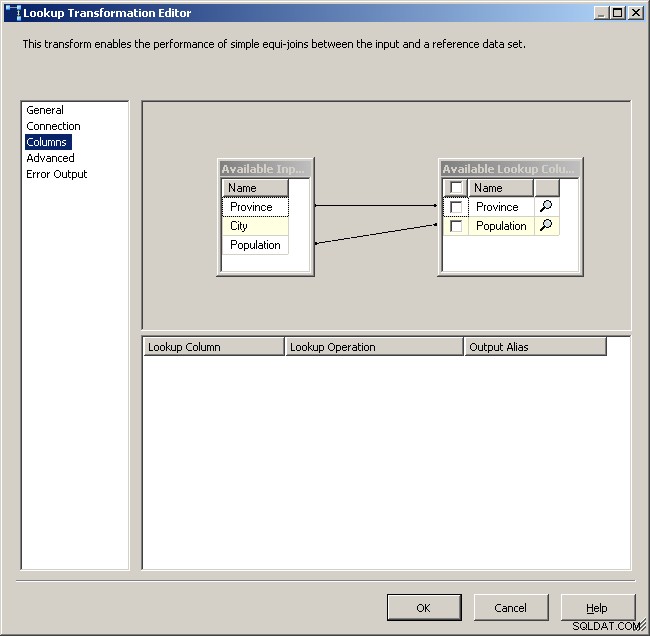
Grande successo 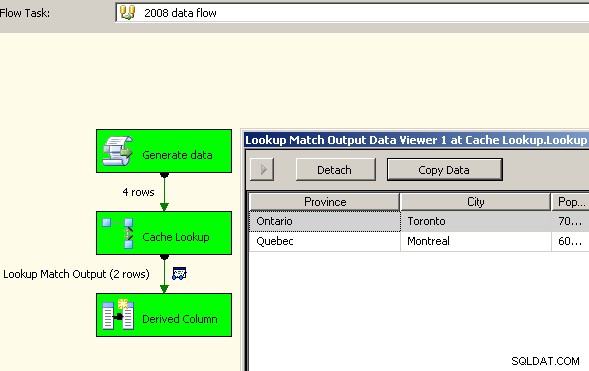
Attività script
Il terzo approccio che mi viene in mente, 2005 o 2008, è scriverlo da soli. Come regola generale, cerco di evitare le attività di script, ma questo è un caso in cui probabilmente ha senso. Dovrai renderlo un trasformazione asincrona dello script ma gestisci semplicemente le tue aggregazioni lì dentro. Più codice da mantenere ma puoi risparmiarti la fatica di rielaborare i tuoi dati di origine.
Infine, come avvertimento generale, indagherei sull'impatto dei legami sulla tua soluzione. Per questo set di dati, mi aspetterei che qualcosa come Guelph si gonfi e leghi improvvisamente Toronto, ma se lo facesse, cosa dovrebbe fare il pacchetto? In questo momento, entrambi risulteranno in 2 righe per l'Ontario, ma è questo il comportamento previsto? Lo script, ovviamente, ti permette di definire cosa succede in caso di pareggio. Probabilmente potresti sopportare la soluzione del 2008 memorizzando nella cache i dati "normali" e utilizzandoli come condizione di ricerca e utilizzando gli aggregati per annullare solo uno dei pareggi. 2005 può probabilmente fare lo stesso semplicemente inserendo l'aggregato come origine sinistra per l'unione di join
Modifiche
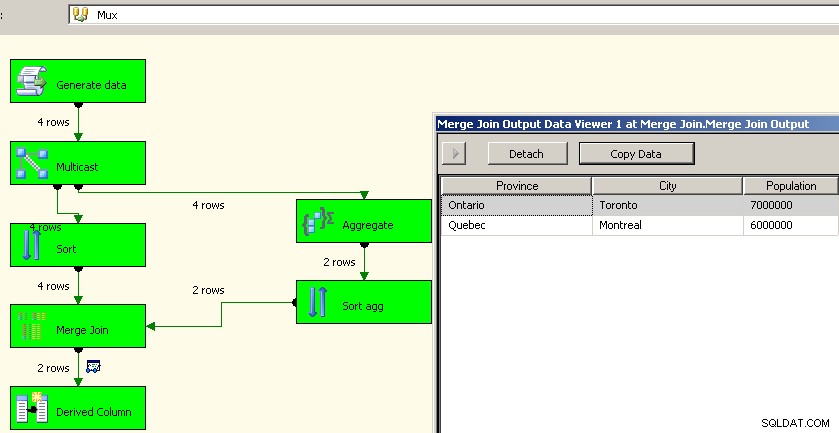
Jason Horner ha avuto una buona idea nel suo commento. Un approccio diverso consisterebbe nell'utilizzare una trasformazione multicast ed eseguire l'aggregazione in un flusso e riunirlo nuovamente. Non riuscivo a capire come farlo funzionare con un'unione, ma potremmo usare gli ordinamenti e unire unire proprio come sopra. Questo è probabilmente un approccio migliore in quanto ci evita la fatica di rielaborare i dati di origine.