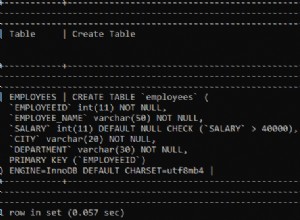
Ho visto quell'articolo, ma nota che per bassi tassi di errore preferirei il modello "JFDI". L'ho già usato su sistemi ad alto volume (40.000 righe/secondo).
Nel codice di Aaron, puoi comunque ottenere un duplicato quando esegui il test prima sotto carico elevato e molte scritture. (spiegato qui su dba.se ) Questo è importante:i tuoi duplicati accadono ancora, solo meno spesso. Hai ancora bisogno di gestire le eccezioni e sapere quando ignorare l'errore duplicato (2627)
Modifica:spiegato succintamente da Remus in un'altra risposta
Tuttavia, avrei un TRY/CATCH separato per testare solo per l'errore duplicato
BEGIN TRY
-- stuff
BEGIN TRY
INSERT etc
END TRY
BEGIN CATCH
IF ERROR_NUMBER() <> 2627
RAISERROR etc
END CATCH
--more stuff
BEGIN CATCH
RAISERROR etc
END CATCH