Secondo La regina dell'indicizzazione - Kimberly Tripp:ciò che cerca in un indice cluster è principalmente:
- Unico
- Stretto
- Statico
E se puoi anche garantire:
- Modello in costante aumento
allora sei abbastanza vicino ad avere la tua chiave di clustering ideale!
Dai un'occhiata al suo intero Post del blog qui e un altro davvero interessante sul clustering degli impatti chiave sulle operazioni delle tabelle qui:Il dibattito sugli indici a grappolo continua .
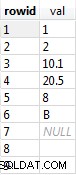
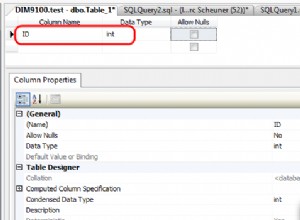
Qualcosa come un INT (in particolare un INT IDENTITY) o eventualmente un INT e un DATETIME sono candidati ideali. Per altri motivi, i GUID non sono affatto buoni candidati, quindi potresti avere un GUID come PK, ma non raggruppare la tabella su di esso:sarà frammentato in modo irriconoscibile e le prestazioni ne risentiranno.