Presumo che il motivo sia che non l'hanno considerata una caratteristica prioritaria che vale la pena implementare. Sembra Postgres fa supporta entrambi
UNION e UNION ALL .
Se sei convinto di questa funzionalità, puoi fornire un feedback su Connect (o qualunque sia l'URL della sua sostituzione).
Impedire l'aggiunta di duplicati potrebbe essere utile poiché una riga duplicata aggiunta in un passaggio successivo a una precedente finirà quasi sempre per causare un ciclo infinito o superare il limite massimo di ricorsione.
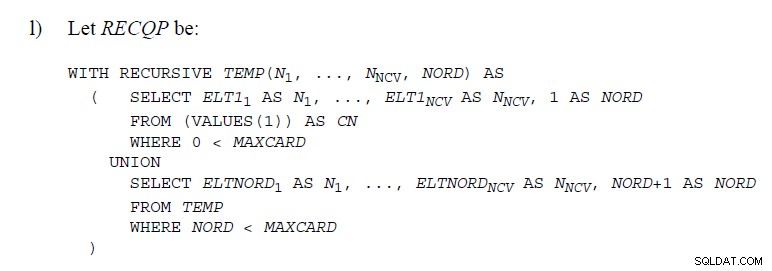
Ci sono alcuni punti negli standard SQL
dove viene utilizzato il codice per dimostrare UNION come di seguito
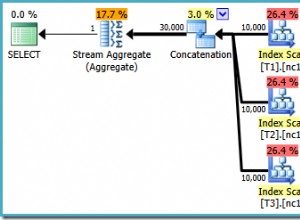
Questo articolo spiega come vengono implementati in SQL Server . Non stanno facendo niente del genere "sotto il cofano". Lo spooling dello stack elimina le righe man mano che procede, quindi non sarebbe possibile sapere se una riga successiva è un duplicato di una eliminata. Supportare UNION avrebbe bisogno di un approccio leggermente diverso.
Nel frattempo puoi facilmente ottenere lo stesso risultato in un TVF a più dichiarazioni.
Per fare un esempio sciocco di seguito (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Modifica del UNION a UNION ALL e aggiungendo un DISTINCT alla fine non ti salverà dalla ricorsione infinita.
Ma puoi implementarlo come
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Quanto sopra usa IGNORE_DUP_KEY per eliminare i duplicati. Se l'elenco delle colonne è troppo ampio per essere indicizzato, avrai bisogno di DISTINCT e NOT EXISTS invece. Probabilmente vorresti anche un parametro per impostare il numero massimo di ricorsioni ed evitare loop infiniti.