La ricerca di dati di stringa per una corrispondenza di sottostringa arbitraria può essere un'operazione costosa in SQL Server. Query del modulo Column LIKE '%match%' non può utilizzare le capacità di ricerca di un indice b-tree, quindi il Query Processor deve applicare il predicato a ciascuna riga individualmente. Inoltre, ogni test deve applicare correttamente l'intera serie di complicate regole di confronto. Combinando tutti questi fattori insieme, non sorprende che questi tipi di ricerche possano essere lente e dispendiose in termini di risorse.
La ricerca full-text è un potente strumento per la corrispondenza linguistica e la più recente ricerca semantica statistica è ottima per trovare documenti con significati simili. Ma a volte, devi solo trovare stringhe che contengano una particolare sottostringa, una sottostringa che potrebbe non essere nemmeno una parola, in qualsiasi lingua.
Se i dati cercati non sono di grandi dimensioni o i requisiti di tempo di risposta non sono critici, utilizzare LIKE '%match%' potrebbe essere una soluzione adatta. Ma, nella strana occasione in cui la necessità di una ricerca super veloce supera tutte le altre considerazioni (incluso lo spazio di archiviazione), potresti prendere in considerazione una soluzione personalizzata utilizzando n-grammi. La variazione specifica esplorata in questo articolo è un trigramma di tre caratteri.
Ricerca con caratteri jolly utilizzando i trigrammi
L'idea di base di una ricerca trigramma è abbastanza semplice:
- Persistere sottostringhe di tre caratteri (trigrammi) dei dati di destinazione.
- Dividi i termini di ricerca in trigrammi.
- Abbina i trigrammi di ricerca ai trigrammi memorizzati (ricerca di uguaglianza)
- Interseca le righe qualificate per trovare le stringhe che corrispondono a tutti i trigrammi
- Applica il filtro di ricerca originale all'intersezione molto ridotta
Lavoreremo attraverso un esempio per vedere esattamente come funziona e quali sono i compromessi.
Tabella di esempio e dati
Lo script seguente crea una tabella di esempio e la popola con un milione di righe di dati stringa. Ogni stringa è lunga 20 caratteri, con i primi 10 caratteri numerici. I restanti 10 caratteri sono una combinazione di numeri e lettere dalla A alla F, generati utilizzando NEWID() . Non c'è niente di terribilmente speciale in questi dati di esempio; la tecnica del trigramma è abbastanza generale.
-- The test table
CREATE TABLE dbo.Example
(
id integer IDENTITY NOT NULL,
string char(20) NOT NULL,
CONSTRAINT [PK dbo.Example (id)]
PRIMARY KEY CLUSTERED (id)
);
GO
-- 1 million rows
INSERT dbo.Example WITH (TABLOCKX)
(string)
SELECT TOP (1 * 1000 * 1000)
-- 10 numeric characters
REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') +
-- plus 10 mixed numeric + [A-F] characters
RIGHT(NEWID(), 10)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
OPTION (MAXDOP 1); Occorrono circa 3 secondi per creare e popolare i dati sul mio modesto laptop. I dati sono pseudocasuali, ma a titolo indicativo assomiglieranno a questo:
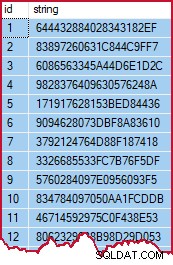
Campione di dati
Generazione di trigrammi
La seguente funzione inline genera trigrammi alfanumerici distinti da una determinata stringa di input:
--- Generate trigrams from a string
CREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING
AS RETURN
WITH
N16 AS
(
SELECT V.v
FROM
(
VALUES
(0),(0),(0),(0),(0),(0),(0),(0),
(0),(0),(0),(0),(0),(0),(0),(0)
) AS V (v)),
-- Numbers table (256)
Nums AS
(
SELECT n = ROW_NUMBER() OVER (ORDER BY A.v)
FROM N16 AS A
CROSS JOIN N16 AS B
),
Trigrams AS
(
-- Every 3-character substring
SELECT TOP (CASE WHEN LEN(@string) > 2 THEN LEN(@string) - 2 ELSE 0 END)
trigram = SUBSTRING(@string, N.n, 3)
FROM Nums AS N
ORDER BY N.n
)
-- Remove duplicates and ensure all three characters are alphanumeric
SELECT DISTINCT
T.trigram
FROM Trigrams AS T
WHERE
-- Binary collation comparison so ranges work as expected
T.trigram COLLATE Latin1_General_BIN2 NOT LIKE '%[^A-Z0-9a-z]%'; Come esempio del suo utilizzo, la seguente chiamata:
SELECT
GT.trigram
FROM dbo.GenerateTrigrams('SQLperformance.com') AS GT; Produce i seguenti trigrammi:

Trigrammi SQLperformance.com
Il piano di esecuzione è una traduzione abbastanza diretta del T-SQL in questo caso:
- Generazione di righe (unione incrociata di scansioni costanti)
- Numerazione delle righe (progetto di segmenti e sequenze)
- Limitazione dei numeri necessari in base alla lunghezza della stringa (Top)
- Rimuovi i trigrammi con caratteri non alfanumerici (Filtro)
- Rimuovi duplicati (ordinamento distinto)

Pianifica la generazione di trigrammi
Caricamento dei trigrammi
Il passaggio successivo consiste nel persistere i trigrammi per i dati di esempio. I trigrammi verranno mantenuti in una nuova tabella, popolata utilizzando la funzione inline appena creata:
-- Trigrams for Example table
CREATE TABLE dbo.ExampleTrigrams
(
id integer NOT NULL,
trigram char(3) NOT NULL
);
GO
-- Generate trigrams
INSERT dbo.ExampleTrigrams WITH (TABLOCKX)
(id, trigram)
SELECT
E.id,
GT.trigram
FROM dbo.Example AS E
CROSS APPLY dbo.GenerateTrigrams(E.string) AS GT; Ci vogliono circa 20 secondi da eseguire sulla mia istanza laptop SQL Server 2016. Questa particolare corsa ha prodotto 17.937.972 righe di trigrammi per 1 milione di righe di dati di test di 20 caratteri. Il piano di esecuzione mostra essenzialmente il piano delle funzioni in corso di valutazione per ogni riga della tabella Esempio:
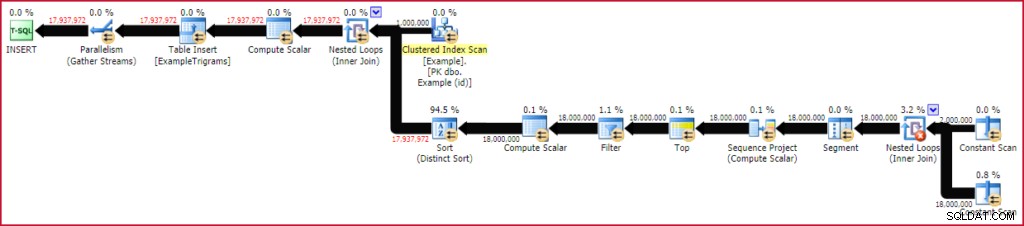
Popolare la tabella del trigramma
Poiché questo test è stato eseguito su SQL Server 2016 (caricamento di una tabella heap, con livello di compatibilità del database 130 e con un TABLOCK suggerimento), il piano beneficia dell'inserimento parallelo. Le righe vengono distribuite tra i thread dalla scansione parallela della tabella di esempio e rimangono sullo stesso thread in seguito (nessuno scambio di partizionamento).
L'operatore di ordinamento potrebbe sembrare un po' imponente, ma i numeri mostrano il numero totale di righe ordinate, su tutte le iterazioni del join del ciclo nidificato. In effetti, ci sono un milione di tipi separati, di 18 righe ciascuno. A un grado di parallelismo di quattro (due core con hyperthreading nel mio caso), ci sono un massimo di quattro tipi minuscoli in corso in qualsiasi momento e ogni istanza di ordinamento può riutilizzare la memoria. Questo spiega perché l'utilizzo massimo della memoria di questo piano di esecuzione è di soli 136 KB (sebbene siano stati concessi 2.152 KB).
La tabella dei trigrammi contiene una riga per ogni trigramma distinto in ciascuna riga della tabella di origine (identificata da id ):
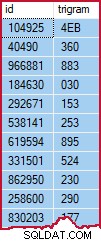
Esempio di tabella dei trigrammi
Ora creiamo un indice b-tree in cluster per supportare la ricerca di corrispondenze del trigramma:
-- Trigram search index
CREATE UNIQUE CLUSTERED INDEX
[CUQ dbo.ExampleTrigrams (trigram, id)]
ON dbo.ExampleTrigrams (trigram, id)
WITH (DATA_COMPRESSION = ROW); Questa operazione richiede circa 45 secondi , anche se parte di ciò è dovuto alla fuoriuscita di ordinamento (la mia istanza è limitata a 4 GB di memoria). Un'istanza con più memoria disponibile potrebbe probabilmente completare la compilazione dell'indice parallelo con registrazione minima un po' più velocemente.
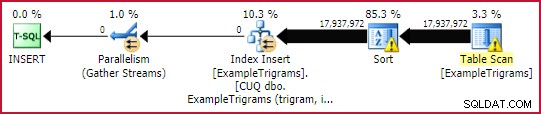
Indice piano edilizio
Si noti che l'indice è specificato come univoco (usando entrambe le colonne nella chiave). Avremmo potuto creare un indice cluster non univoco solo sul trigramma, ma SQL Server avrebbe comunque aggiunto unificatori a 4 byte a quasi tutte le righe. Una volta calcolato che gli unificatori sono memorizzati nella parte a lunghezza variabile della riga (con l'overhead associato), ha più senso includere id nella chiave e basta.
La compressione delle righe è specificata perché riduce utilmente le dimensioni della tabella dei trigrammi da 277 MB a 190 MB (per confronto, la tabella di esempio è 32 MB). Se non utilizzi almeno SQL Server 2016 SP1 (in cui la compressione dei dati è diventata disponibile per tutte le edizioni), puoi omettere la clausola di compressione, se necessario.
Come ottimizzazione finale, creeremo anche una vista indicizzata sulla tabella dei trigrammi per rendere facile e veloce trovare i trigrammi più e meno comuni nei dati. Questo passaggio può essere omesso, ma è consigliato per le prestazioni.
-- Selectivity of each trigram (performance optimization)
CREATE VIEW dbo.ExampleTrigramCounts
WITH SCHEMABINDING
AS
SELECT ET.trigram, cnt = COUNT_BIG(*)
FROM dbo.ExampleTrigrams AS ET
GROUP BY ET.trigram;
GO
-- Materialize the view
CREATE UNIQUE CLUSTERED INDEX
[CUQ dbo.ExampleTrigramCounts (trigram)]
ON dbo.ExampleTrigramCounts (trigram); 
Vista indicizzata pianta dell'edificio
Questo richiede solo un paio di secondi per essere completato. La dimensione della vista materializzata è minuscola, solo 104 KB .
Ricerca trigramma
Data una stringa di ricerca (ad es. '%find%this%' ), il nostro approccio sarà:
- Genera il set completo di trigrammi per la stringa di ricerca
- Utilizza la vista indicizzata per trovare i tre trigrammi più selettivi
- Trova gli ID corrispondenti a tutti i trigrammi disponibili
- Recupera le stringhe tramite id
- Applica il filtro completo alle righe qualificate per il trigramma
Trovare trigrammi selettivi
I primi due passaggi sono piuttosto semplici. Abbiamo già una funzione per generare trigrammi per una stringa arbitraria. È possibile trovare il più selettivo di quei trigrammi unendosi alla vista indicizzata. Il codice seguente racchiude l'implementazione per la nostra tabella di esempio in un'altra funzione inline. Inverte i tre trigrammi più selettivi in un'unica riga per facilità d'uso in seguito:
-- Most selective trigrams for a search string
-- Always returns a row (NULLs if no trigrams found)
CREATE FUNCTION dbo.Example_GetBestTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING AS
RETURN
SELECT
-- Pivot
trigram1 = MAX(CASE WHEN BT.rn = 1 THEN BT.trigram END),
trigram2 = MAX(CASE WHEN BT.rn = 2 THEN BT.trigram END),
trigram3 = MAX(CASE WHEN BT.rn = 3 THEN BT.trigram END)
FROM
(
-- Generate trigrams for the search string
-- and choose the most selective three
SELECT TOP (3)
rn = ROW_NUMBER() OVER (
ORDER BY ETC.cnt ASC),
GT.trigram
FROM dbo.GenerateTrigrams(@string) AS GT
JOIN dbo.ExampleTrigramCounts AS ETC
WITH (NOEXPAND)
ON ETC.trigram = GT.trigram
ORDER BY
ETC.cnt ASC
) AS BT; Ad esempio:
SELECT
EGBT.trigram1,
EGBT.trigram2,
EGBT.trigram3
FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT; resi (per i miei dati di esempio):
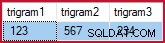
Trigrammi selezionati
Il piano di esecuzione è:
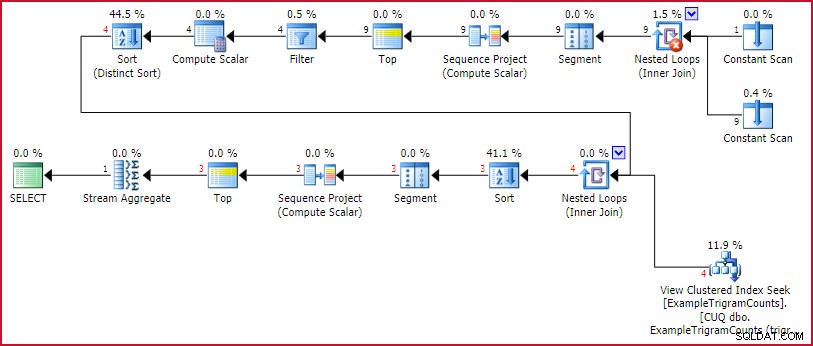
Piano di esecuzione di GetBestTrigrams
Questo è il familiare piano di generazione del trigramma di prima, seguito da una ricerca nella vista indicizzata per ciascun trigramma, ordinando in base al numero di corrispondenze, numerando le righe (progetto sequenza), limitando l'insieme a tre righe (in alto), quindi ruotando il risultato (Stream Aggregate).
Trovare ID corrispondenti a tutti i trigrammi
Il passaggio successivo consiste nel trovare gli ID di riga della tabella di esempio che corrispondono a tutti i trigrammi non null recuperati dalla fase precedente. Il problema qui è che potremmo avere zero, uno, due o tre trigrammi disponibili. La seguente implementazione racchiude la logica necessaria in una funzione a più istruzioni, restituendo gli ID di qualificazione in una variabile di tabella:
-- Returns Example ids matching all provided (non-null) trigrams
CREATE FUNCTION dbo.Example_GetTrigramMatchIDs
(
@Trigram1 char(3),
@Trigram2 char(3),
@Trigram3 char(3)
)
RETURNS @IDs table (id integer PRIMARY KEY)
WITH SCHEMABINDING AS
BEGIN
IF @Trigram1 IS NOT NULL
BEGIN
IF @Trigram2 IS NOT NULL
BEGIN
IF @Trigram3 IS NOT NULL
BEGIN
-- 3 trigrams available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.id
FROM dbo.ExampleTrigrams AS ET2
WHERE ET2.trigram = @Trigram2
INTERSECT
SELECT ET3.id
FROM dbo.ExampleTrigrams AS ET3
WHERE ET3.trigram = @Trigram3
OPTION (MERGE JOIN);
END;
ELSE
BEGIN
-- 2 trigrams available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.id
FROM dbo.ExampleTrigrams AS ET2
WHERE ET2.trigram = @Trigram2
OPTION (MERGE JOIN);
END;
END;
ELSE
BEGIN
-- 1 trigram available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1;
END;
END;
RETURN;
END; Il piano di esecuzione stimato per questa funzione mostra la strategia:
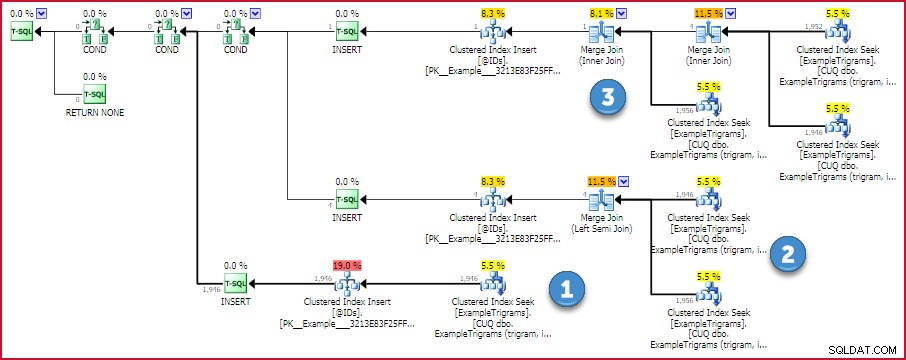
Piano ID corrispondenza Trigram
Se è disponibile un trigramma, viene eseguita una singola ricerca nella tabella dei trigrammi. In caso contrario, vengono eseguite due o tre ricerche e l'intersezione degli ID viene trovata utilizzando un'efficiente unione uno a molti. Non ci sono operatori che consumano memoria in questo piano, quindi nessuna possibilità di hash o sort spill.
Continuando la ricerca di esempio, possiamo trovare id corrispondenti ai trigrammi disponibili applicando la nuova funzione:
SELECT EGTMID.id
FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT
CROSS APPLY dbo.Example_GetTrigramMatchIDs
(EGBT.trigram1, EGBT.trigram2, EGBT.trigram3) AS EGTMID; Questo restituisce un set come il seguente:

ID corrispondenti
Il piano effettivo (post-esecuzione) per la nuova funzione mostra la forma del piano con tre input di trigramma utilizzati:
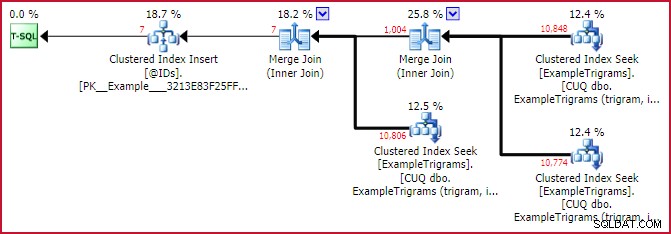
Piano di abbinamento ID effettivo
Questo mostra la potenza della corrispondenza dei trigrammi abbastanza bene. Sebbene tutti e tre i trigrammi identifichino ciascuno circa 11.000 righe nella tabella di esempio, la prima intersezione riduce questo set a 1.004 righe e la seconda intersezione lo riduce a solo 7 .
Implementazione completa della ricerca del trigramma
Ora che abbiamo gli ID corrispondenti ai trigrammi, possiamo cercare le righe corrispondenti nella tabella Esempio. Dobbiamo ancora applicare la condizione di ricerca originale come controllo finale, perché i trigrammi possono generare falsi positivi (ma non falsi negativi). L'ultimo problema da affrontare è che le fasi precedenti potrebbero non aver trovato alcun trigramma. Ciò potrebbe essere dovuto, ad esempio, al fatto che la stringa di ricerca contiene troppo poche informazioni. Una stringa di ricerca di '%FF%' non è possibile utilizzare la ricerca trigramma perché due caratteri non sono sufficienti per generare nemmeno un singolo trigramma. Per gestire questo scenario con garbo, la nostra ricerca rileverà questa condizione e ricadrà su una ricerca senza trigramma.
La seguente funzione inline finale implementa la logica richiesta:
-- Search implementation
CREATE FUNCTION dbo.Example_TrigramSearch
(
@Search varchar(255)
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
Result.string
FROM dbo.Example_GetBestTrigrams(@Search) AS GBT
CROSS APPLY
(
-- Trigram search
SELECT
E.id,
E.string
FROM dbo.Example_GetTrigramMatchIDs
(GBT.trigram1, GBT.trigram2, GBT.trigram3) AS MID
JOIN dbo.Example AS E
ON E.id = MID.id
WHERE
-- At least one trigram found
GBT.trigram1 IS NOT NULL
AND E.string LIKE @Search
UNION ALL
-- Non-trigram search
SELECT
E.id,
E.string
FROM dbo.Example AS E
WHERE
-- No trigram found
GBT.trigram1 IS NULL
AND E.string LIKE @Search
) AS Result;
La caratteristica chiave è il riferimento esterno a GBT.trigram1 su entrambi i lati del UNION ALL . Questi si traducono in Filtri con espressioni di avvio nel piano di esecuzione. Un filtro di avvio esegue il suo sottoalbero solo se la sua condizione restituisce true. L'effetto netto è che verrà eseguita solo una parte dell'unione, a seconda che abbiamo trovato un trigramma o meno. La parte rilevante del piano di esecuzione è:
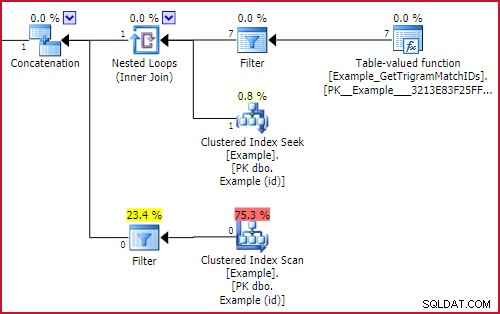
Effetto filtro di avvio
O il Example_GetTrigramMatchIDs verrà eseguita la funzione (e i risultati verranno cercati nell'esempio utilizzando una ricerca su id) o la scansione dell'indice cluster dell'esempio con un LIKE residuo il predicato verrà eseguito, ma non entrambi.
Prestazioni
Il codice seguente verifica le prestazioni della ricerca del trigramma rispetto all'equivalente LIKE :
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT F2.string
FROM dbo.Example AS F2
WHERE
F2.string LIKE '%1234%5678%'
OPTION (MAXDOP 1);
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
GO
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%1234%5678%') AS ETS;
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
Entrambi producono le stesse righe di risultati ma LIKE la query viene eseguita per 2100 ms , mentre la ricerca del trigramma richiede 15 ms .
Sono possibili prestazioni ancora migliori. In genere, le prestazioni migliorano man mano che i trigrammi diventano più selettivi e di numero inferiore (al di sotto del massimo di tre in questa implementazione). Ad esempio:
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%BEEF%') AS ETS;
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
Quella ricerca ha restituito 111 righe alla griglia SSMS in 4 ms . Il LIKE l'equivalente è stato eseguito per 1950 ms .
Mantenimento dei trigrammi
Se la tabella di destinazione è statica, ovviamente non ci sono problemi a mantenere sincronizzata la tabella di base e la relativa tabella di trigramma. Allo stesso modo, se non è necessario che i risultati della ricerca siano sempre completamente aggiornati, un aggiornamento pianificato delle tabelle di trigramma potrebbe funzionare bene.
Altrimenti, possiamo utilizzare alcuni trigger abbastanza semplici per mantenere sincronizzati i dati di ricerca del trigramma con le stringhe sottostanti. L'idea generale è quella di generare trigrammi per le righe eliminate e inserite, quindi aggiungerli o eliminarli nella tabella dei trigrammi a seconda dei casi. I trigger di inserimento, aggiornamento ed eliminazione riportati di seguito mostrano questa idea in pratica:
-- Maintain trigrams after Example inserts
CREATE TRIGGER MaintainTrigrams_AI
ON dbo.Example
AFTER INSERT
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Insert related trigrams
INSERT dbo.ExampleTrigrams
(id, trigram)
SELECT
INS.id, GT.trigram
FROM Inserted AS INS
CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;
END; -- Maintain trigrams after Example deletes
CREATE TRIGGER MaintainTrigrams_AD
ON dbo.Example
AFTER DELETE
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Deleted related trigrams
DELETE ET
WITH (SERIALIZABLE)
FROM Deleted AS DEL
CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT
JOIN dbo.ExampleTrigrams AS ET
ON ET.trigram = GT.trigram
AND ET.id = DEL.id;
END; -- Maintain trigrams after Example updates
CREATE TRIGGER MaintainTrigrams_AU
ON dbo.Example
AFTER UPDATE
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Deleted related trigrams
DELETE ET
WITH (SERIALIZABLE)
FROM Deleted AS DEL
CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT
JOIN dbo.ExampleTrigrams AS ET
ON ET.trigram = GT.trigram
AND ET.id = DEL.id;
-- Insert related trigrams
INSERT dbo.ExampleTrigrams
(id, trigram)
SELECT
INS.id, GT.trigram
FROM Inserted AS INS
CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;
END;
I trigger sono piuttosto efficienti e gestiranno modifiche sia a riga singola che a più righe (incluse le molteplici azioni disponibili quando si utilizza un MERGE dichiarazione). La vista indicizzata sulla tabella dei trigrammi verrà gestita automaticamente da SQL Server senza che sia necessario scrivere alcun codice trigger.
Operazione trigger
Ad esempio, esegui un'istruzione per eliminare una riga arbitraria dalla tabella Esempio:
-- Single row delete DELETE TOP (1) dbo.Example;
Il piano di esecuzione post-esecuzione (effettivo) include una voce per il trigger dopo l'eliminazione:
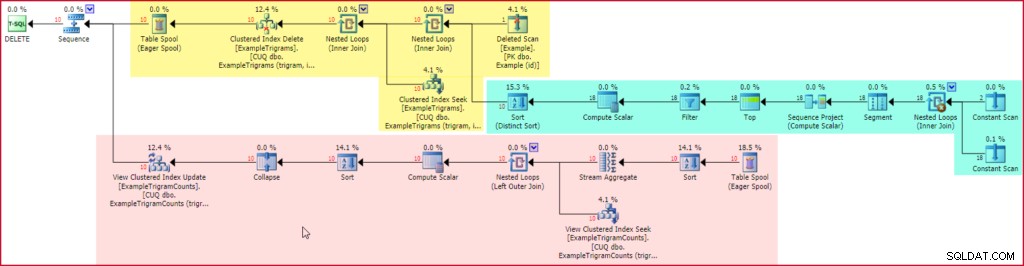
Elimina il piano di esecuzione del trigger
La sezione gialla del piano legge le righe dei eliminati pesudo-table, genera trigrammi per ogni stringa di esempio eliminata (usando il piano familiare evidenziato in verde), quindi individua ed elimina le voci della tabella trigram associate. La sezione finale del piano, mostrata in rosso, viene aggiunta automaticamente da SQL Server per mantenere aggiornata la vista indicizzata.
Il piano per il trigger di inserimento è estremamente simile. Gli aggiornamenti vengono gestiti eseguendo un'eliminazione seguita da un inserimento. Esegui il seguente script per visualizzare questi piani e confermare che le righe nuove e aggiornate possono essere individuate utilizzando la funzione di ricerca del trigramma:
-- Single row insert
INSERT dbo.Example (string)
VALUES ('SQLPerformance.com');
-- Find the new row
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%perf%') AS ETS;
-- Single row update
UPDATE TOP (1) dbo.Example
SET string = '12345678901234567890';
-- Multi-row insert
INSERT dbo.Example WITH (TABLOCKX)
(string)
SELECT TOP (1000)
REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') +
RIGHT(NEWID(), 10)
FROM master.dbo.spt_values AS SV1;
-- Multi-row update
UPDATE TOP (1000) dbo.Example
SET string = '12345678901234567890';
-- Search for the updated rows
SELECT ETS.string
FROM dbo.Example_TrigramSearch('12345678901234567890') AS ETS; Esempio di unione
Lo script successivo mostra un MERGE istruzione utilizzata per inserire, eliminare e aggiornare la tabella di esempio tutto in una volta:
-- MERGE demo
DECLARE @MergeData table
(
id integer UNIQUE CLUSTERED NULL,
operation char(3) NOT NULL,
string char(20) NULL
);
INSERT @MergeData
(id, operation, string)
VALUES
(NULL, 'INS', '11223344556677889900'), -- Insert
(1001, 'DEL', NULL), -- Delete
(2002, 'UPD', '00000000000000000000'); -- Update
DECLARE @Actions table
(
action$ nvarchar(10) NOT NULL,
old_id integer NULL,
old_string char(20) NULL,
new_id integer NULL,
new_string char(20) NULL
);
MERGE dbo.Example AS E
USING @MergeData AS MD
ON MD.id = E.id
WHEN MATCHED AND MD.operation = 'DEL'
THEN DELETE
WHEN MATCHED AND MD.operation = 'UPD'
THEN UPDATE SET E.string = MD.string
WHEN NOT MATCHED AND MD.operation = 'INS'
THEN INSERT (string) VALUES (MD.string)
OUTPUT $action, Deleted.id, Deleted.string, Inserted.id, Inserted.string
INTO @Actions (action$, old_id, old_string, new_id, new_string);
SELECT * FROM @Actions AS A; L'output mostrerà qualcosa come:

Risultato dell'azione
Pensieri finali
Forse c'è un certo margine per accelerare le operazioni di eliminazione e aggiornamento di grandi dimensioni facendo riferimento direttamente agli ID invece di generare trigrammi. Questo non è implementato qui perché richiederebbe un nuovo indice non cluster sulla tabella dei trigrammi, raddoppiando lo spazio di archiviazione (già significativo) utilizzato. La tabella dei trigrammi contiene un singolo intero e un char(3) per riga; un indice non cluster sulla colonna intera otterrebbe il char(3) colonna a tutti i livelli (per gentile concessione dell'indice cluster e della necessità che le chiavi dell'indice siano univoche a ogni livello). C'è anche spazio di memoria da considerare, poiché le ricerche trigramma funzionano meglio quando tutte le letture provengono dalla cache.
L'indice aggiuntivo renderebbe l'integrità referenziale a cascata un'opzione, ma spesso è più problematico di quanto ne valga la pena.
La ricerca del trigramma non è una panacea. I requisiti di archiviazione aggiuntivi, la complessità dell'implementazione e l'impatto sulle prestazioni degli aggiornamenti pesano molto a sfavore. La tecnica è inutile anche per ricerche che non generano trigrammi (minimo 3 caratteri). Sebbene l'implementazione di base mostrata qui possa gestire molti tipi di ricerca (inizia con, contiene, finisce con più caratteri jolly), non copre tutte le possibili espressioni di ricerca che possono essere fatte funzionare con LIKE . Funziona bene per le stringhe di ricerca che generano trigrammi di tipo AND; è necessario più lavoro per gestire le stringhe di ricerca che richiedono la gestione del tipo OR o opzioni più avanzate come le espressioni regolari.
Detto questo, se la tua domanda è davvero deve hanno ricerche veloci di stringhe con caratteri jolly, gli n-grammi sono qualcosa da considerare seriamente.
Contenuti correlati:un modo per ottenere un indice cerca un %wildcard principale di Aaron Bertrand.