Breve riepilogo
- Le prestazioni del metodo delle sottoquery dipendono dalla distribuzione dei dati.
- Le prestazioni dell'aggregazione condizionale non dipendono dalla distribuzione dei dati.
Il metodo delle sottoquery può essere più veloce o più lento dell'aggregazione condizionale, dipende dalla distribuzione dei dati.
Naturalmente, se la tabella ha un indice adatto, è probabile che le sottoquery ne traggano vantaggio, perché index consentirebbe di scansionare solo la parte rilevante della tabella invece della scansione completa. È improbabile che disporre di un indice adatto possa avvantaggiare in modo significativo il metodo di aggregazione condizionale, poiché eseguirà comunque la scansione dell'intero indice. L'unico vantaggio sarebbe se l'indice è più stretto della tabella e il motore dovrebbe leggere meno pagine in memoria.
Sapendo questo puoi decidere quale metodo scegliere.
Primo test
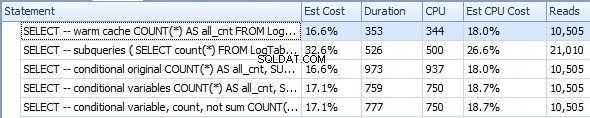
Ho creato una tabella di prova più grande, con 5 milioni di righe. Non c'erano indici sul tavolo. Ho misurato le statistiche di IO e CPU usando SQL Sentry Plan Explorer. Ho usato SQL Server 2014 SP1-CU7 (12.0.4459.0) Express a 64 bit per questi test.
In effetti, le tue query originali si sono comportate come hai descritto, ovvero le sottoquery erano più veloci anche se le letture erano 3 volte superiori.
Dopo alcuni tentativi su una tabella senza un indice ho riscritto il tuo aggregato condizionale e aggiunto variabili per mantenere il valore di DATEADD espressioni.
Il tempo complessivo è diventato notevolmente più veloce.
Poi ho sostituito SUM con COUNT ed è diventato di nuovo un po' più veloce.
Dopotutto, l'aggregazione condizionale è diventata più o meno veloce delle sottoquery.
Riscalda la cache (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subquery (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Aggregazione condizionale originale (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Aggregazione condizionale con variabili (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Aggregazione condizionale con variabili e COUNT invece di SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Sulla base di questi risultati, la mia ipotesi è che CASE invocato DATEADD per ogni riga, mentre WHERE era abbastanza intelligente da calcolarlo una volta. Più COUNT è leggermente più efficiente di SUM .
Alla fine, l'aggregazione condizionale è solo leggermente più lenta delle sottoquery (1062 vs 1031), forse perché WHERE è un po' più efficiente di CASE di per sé, e inoltre, WHERE filtra alcune righe, quindi COUNT deve elaborare meno righe.
In pratica userei l'aggregazione condizionale, perché penso che il numero di letture sia più importante. Se la tua tabella è piccola per adattarsi e rimanere nel pool di buffer, qualsiasi query sarà veloce per l'utente finale. Tuttavia, se la tabella è più grande della memoria disponibile, mi aspetto che la lettura dal disco rallentino notevolmente le sottoquery.
Secondo test
D'altra parte, è importante anche filtrare le righe il prima possibile.
Ecco una leggera variazione del test, che lo dimostra. Qui ho impostato la soglia su GETDATE() + 100 anni, per assicurarmi che nessuna riga soddisfi i criteri di filtro.
Riscalda la cache (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subquery (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Aggregazione condizionale originale (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Aggregazione condizionale con variabili (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Aggregazione condizionale con variabili e COUNT invece di SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Di seguito è riportato un piano con sottoquery. Puoi vedere che 0 righe sono state inserite nello Stream Aggregate nella seconda sottoquery, tutte sono state filtrate nel passaggio Table Scan.
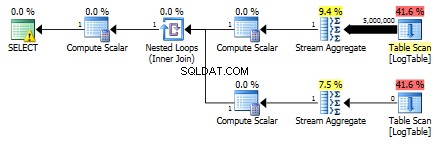
Di conseguenza, le sottoquery sono di nuovo più veloci.
Terza prova
Qui ho modificato i criteri di filtraggio del test precedente:all > sono stati sostituiti con < . Di conseguenza, il condizionale COUNT contato tutte le righe invece di nessuna. Sorpresa sorpresa! La query di aggregazione condizionale ha richiesto gli stessi 750 ms, mentre le sottoquery sono diventate 813 anziché 500.

Ecco il piano per le subquery:
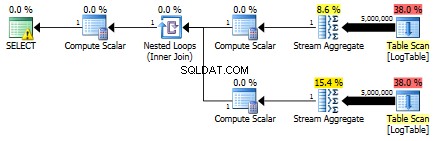
Potresti farmi un esempio, in cui l'aggregazione condizionale supera notevolmente la soluzione di sottoquery?
Ecco qui. Le prestazioni del metodo delle sottoquery dipendono dalla distribuzione dei dati. Le prestazioni dell'aggregazione condizionale non dipendono dalla distribuzione dei dati.
Il metodo delle sottoquery può essere più veloce o più lento dell'aggregazione condizionale, dipende dalla distribuzione dei dati.
Sapendo questo puoi decidere quale metodo scegliere.
Dettagli bonus
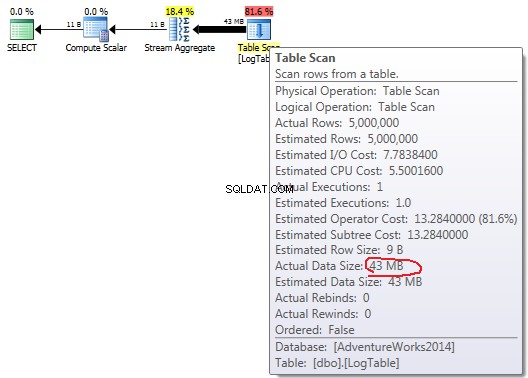
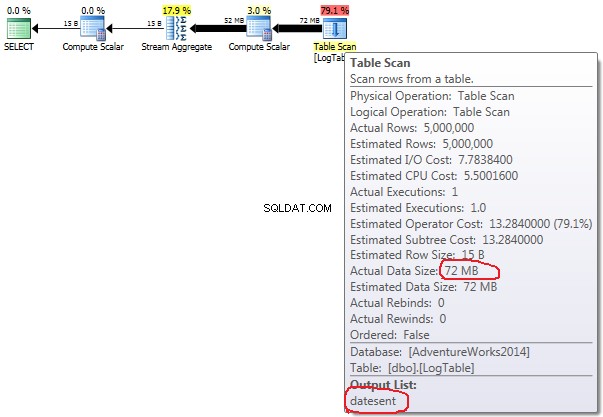
Se passi il mouse sopra Table Scan dall'operatore puoi vedere il Actual Data Size in diverse varianti.
- Semplice
COUNT(*):
- Aggregazione condizionale:
- Subquery nel test 2:
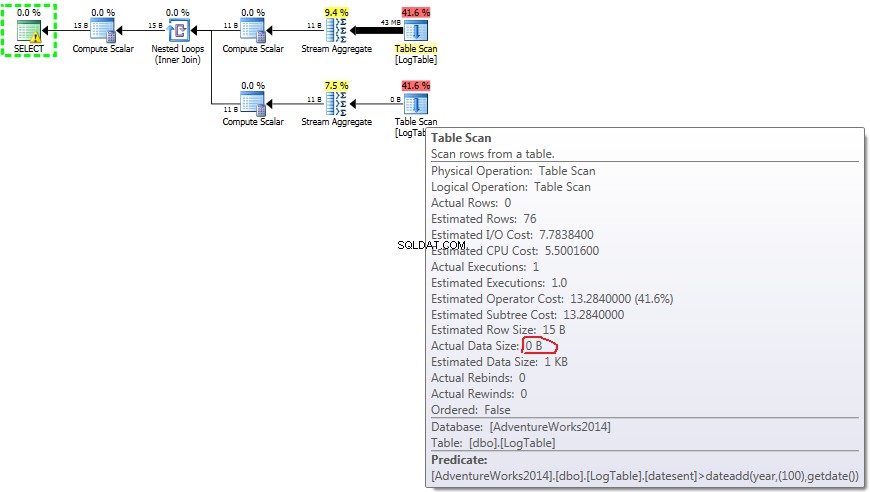
- Subquery nel test 3:
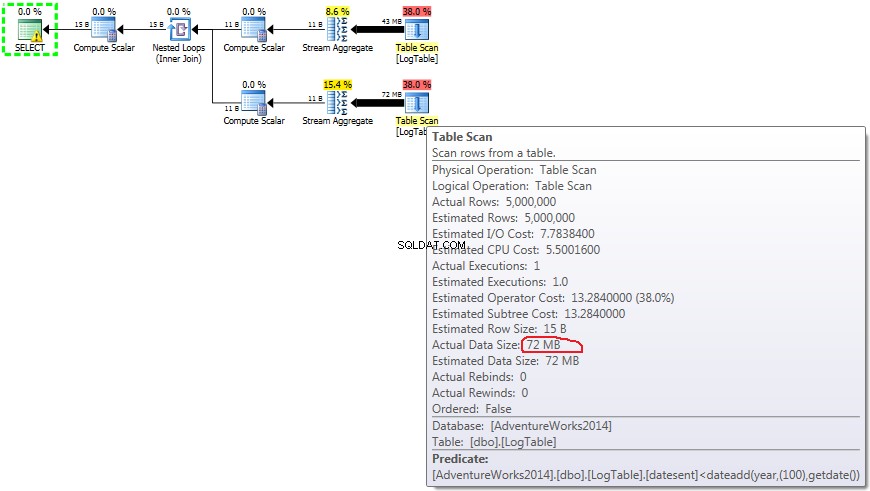
Ora diventa chiaro che la differenza di prestazioni è probabilmente causata dalla differenza nella quantità di dati che scorre attraverso il piano.
In caso di semplice COUNT(*) non esiste un Output list (non sono necessari valori di colonna) e la dimensione dei dati è minima (43 MB).
In caso di aggregazione condizionata tale importo non cambia tra i test 2 e 3, è sempre 72MB. Output list ha una colonna datesent .
In caso di sottoquery, questo importo fa cambia a seconda della distribuzione dei dati.