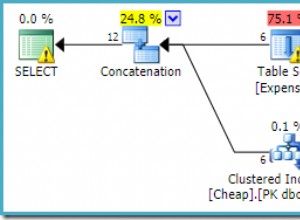
È difficile affermarlo in modo più conciso dell'MVP di SQL Server Brad McGehee:
Come regola pratica, ogni tabella dovrebbe avere un indice cluster. In genere, ma non sempre, l'indice cluster deve trovarsi su una colonna che aumenta in modo monotono, ad esempio una colonna di identità o un'altra colonna in cui il valore è in aumento, ed è univoca. In molti casi, la chiave primaria è la colonna ideale per un indice cluster.
BOL fa eco a questo sentimento:
Con poche eccezioni, ogni tabella dovrebbe avere un indice cluster.
Le ragioni per farlo sono molte e si basano principalmente sul fatto che un indice cluster ordina fisicamente i tuoi dati in memoria .
-
Se il tuo indice cluster si trova su una singola colonna aumenta in modo monotono, gli inserimenti si verificano in ordine sul dispositivo di archiviazione e le divisioni di pagina non si verificano.
-
Gli indici raggruppati sono efficienti per trovare una riga specifica quando il valore indicizzato è univoco, ad esempio il modello comune di selezione di una riga in base alla chiave primaria.
-
Un indice cluster spesso consente query efficienti su colonne che vengono spesso cercate per intervalli di valori (
between,>, ecc.). -
Il clustering può velocizzare le query in cui i dati sono comunemente ordinati in base a una o più colonne specifiche.
-
Un indice cluster può essere ricostruito o riorganizzato su richiesta per controllare la frammentazione delle tabelle.
-
Questi vantaggi possono essere applicati anche alle visualizzazioni.
Potresti non voler avere un indice cluster su:
-
Colonne con modifiche frequenti ai dati, poiché SQL Server deve quindi riordinare fisicamente i dati nell'archiviazione.
-
Colonne già coperte da altri indici.
-
Chiavi larghe, poiché l'indice cluster viene utilizzato anche nelle ricerche di indici non cluster.
-
Colonne GUID, che sono più grandi delle identità e anche effettivamente valori casuali (è improbabile che vengano ordinate), sebbene
newsequentialid()potrebbe essere utilizzato per ridurre il riordino fisico durante gli inserimenti. -
Un raro motivo per utilizzare un heap (tabella senza un indice cluster) è se si accede sempre ai dati tramite indici non cluster e il RID (identificatore di riga interno di SQL Server) è noto per essere più piccolo di una chiave di indice cluster.
A causa di queste e di altre considerazioni, come i carichi di lavoro delle tue applicazioni particolari, dovresti selezionare attentamente i tuoi indici cluster per ottenere il massimo vantaggio dalle tue query.
Tieni inoltre presente che quando crei una chiave primaria su una tabella in SQL Server, per impostazione predefinita verrà creato un indice cluster univoco (se non ne ha già uno). Ciò significa che se trovi una tabella che non ha un indice cluster, ma ha una chiave primaria (come tutte le tabelle dovrebbero), uno sviluppatore aveva precedentemente preso la decisione di crearla in quel modo. Potresti voler avere una ragione convincente per cambiarlo (di cui ce ne sono molti, come abbiamo visto). L'aggiunta, la modifica o l'eliminazione dell'indice cluster richiede la riscrittura dell'intera tabella e tutti gli indici non cluster, quindi l'operazione può richiedere del tempo su un tavolo di grandi dimensioni.