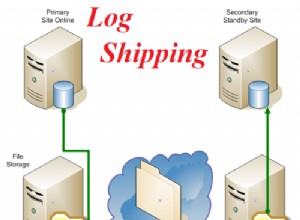
INSERT INTO <table>
SELECT <natural keys>, <other stuff...>
FROM <table>
WHERE NOT EXISTS
-- race condition risk here?
( SELECT 1 FROM <table> WHERE <natural keys> )
UPDATE ...
WHERE <natural keys>
- c'è una race condition nel primo INSERT. La chiave potrebbe non esistere durante la query interna SELECT, ma esiste al momento INSERT con conseguente violazione della chiave.
- c'è una race condition tra INSERT e UPDATE. La chiave può esistere quando viene controllata nella query interna di INSERT ma è sparita quando UPDATE viene eseguito.
Per la seconda race condition si potrebbe sostenere che la chiave sarebbe stata comunque eliminata dal thread simultaneo, quindi non è davvero un aggiornamento perso.
La soluzione ottimale è di solito provare il caso più probabile e gestire l'errore se fallisce (all'interno di una transazione, ovviamente):
- se è probabile che la chiave sia mancante, inserirla sempre per prima. Gestisci la violazione del vincolo univoco, fallback per l'aggiornamento.
- se è probabile che la chiave sia presente, aggiorna sempre prima. Inserisci se non è stata trovata alcuna riga. Gestisci la possibile violazione del vincolo univoco, fallback per l'aggiornamento.
Oltre alla correttezza, questo schema è ottimale anche per la velocità:è più efficiente cercare di inserire e gestire l'eccezione che eseguire lockup spuri. I blocchi significano letture di pagine logiche (che possono significare letture di pagine fisiche) e IO (anche logico) è più costoso di SEH.
Aggiorna @Pietro
Perché una singola affermazione non è "atomica"? Diciamo che abbiamo una tabella banale:
create table Test (id int primary key);
Ora, se eseguissi questa singola istruzione da due thread, in un ciclo, sarebbe "atomico", come dici tu, una condizione di non competizione può esistere:
insert into Test (id)
select top (1) id
from Numbers n
where not exists (select id from Test where id = n.id);
Eppure, in solo un paio di secondi, si verifica una violazione della chiave primaria:
Msg 2627, livello 14, stato 1, riga 4
Violazione del vincolo PRIMARY KEY 'PK__Test__24927208'. Impossibile inserire una chiave duplicata nell'oggetto 'dbo.Test'.
Perché? Hai ragione sul fatto che il piano di query SQL farà la "cosa giusta" su DELETE ... FROM ... JOIN , su WITH cte AS (SELECT...FROM ) DELETE FROM cte e in molti altri casi. Ma in questi casi c'è una differenza fondamentale:la "sottoquery" si riferisce al obiettivo di un aggiornamento o elimina operazione. Per tali casi il piano di query utilizzerà effettivamente un blocco appropriato, infatti questo comportamento è critico in alcuni casi, come quando si implementano le code usando le tabelle come code.
Ma nella domanda originale, così come nel mio esempio, la sottoquery è vista da Query Optimizer proprio come una sottoquery in una query, non come una query di tipo "scansione per aggiornamento" speciale che necessita di una protezione di blocco speciale. Il risultato è che l'esecuzione della ricerca della sottoquery può essere osservata come un'operazione distinta da un osservatore simultaneo , rompendo così il comportamento "atomico" dell'affermazione. A meno che non vengano prese precauzioni speciali, più thread possono tentare di inserire lo stesso valore, entrambi convinti di aver verificato e che il valore non esista già. Solo uno può avere successo, l'altro colpirà la violazione PK. QED.