La strategia di indicizzazione delle tabelle è una delle chiavi di ottimizzazione e ottimizzazione delle prestazioni più importanti. In SQL Server, gli indici (sia cluster che non cluster) vengono creati utilizzando una struttura ad albero B, in cui ogni pagina funge da nodo elenco doppiamente collegato, con informazioni sulle pagine precedenti e successive. Questa struttura ad albero B, chiamata Forward Scan, semplifica la lettura delle righe dall'indice scansionando o cercando le sue pagine dall'inizio alla fine. Sebbene la scansione in avanti sia il metodo di scansione dell'indice predefinito e ampiamente noto, SQL Server ci offre la possibilità di analizzare le righe dell'indice all'interno della struttura B-tree dalla fine all'inizio. Questa capacità è chiamata Scansione all'indietro. In questo articolo vedremo come ciò accade e quali sono i pro ei contro del metodo di scansione all'indietro.
SQL Server ci offre la possibilità di leggere i dati dall'indice della tabella eseguendo la scansione dei nodi della struttura ad albero B dell'indice dall'inizio alla fine utilizzando il metodo Forward Scan o leggendo i nodi della struttura ad albero B dalla fine all'inizio utilizzando il metodo Metodo di scansione all'indietro. Come indica il nome, la scansione all'indietro viene eseguita durante la lettura opposta all'ordine della colonna inclusa nell'indice, che viene eseguita con l'opzione DESC nell'istruzione di ordinamento ORDER BY T-SQL, che specifica la direzione dell'operazione di scansione.
In situazioni specifiche, SQL Server Engine rileva che la lettura dei dati dell'indice dalla fine all'inizio con il metodo di scansione all'indietro è più veloce rispetto alla lettura nell'ordine normale con il metodo di scansione in avanti, che potrebbe richiedere un costoso processo di ordinamento da parte dell'SQL Motore. Tali casi includono l'utilizzo della funzione di aggregazione MAX() e situazioni in cui l'ordinamento del risultato della query è opposto all'ordine dell'indice. Lo svantaggio principale del metodo di scansione all'indietro è che Query Optimizer di SQL Server sceglierà sempre di eseguirlo utilizzando l'esecuzione del piano seriale, senza poter trarre vantaggio dai piani di esecuzione parallela.
Supponiamo di avere la seguente tabella che conterrà informazioni sui dipendenti dell'azienda. La tabella può essere creata utilizzando l'istruzione CREATE TABLE T-SQL di seguito:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Dopo aver creato la tabella, la riempiremo con 10.000 record fittizi, utilizzando l'istruzione INSERT di seguito:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Se eseguiamo l'istruzione SELECT di seguito per recuperare i dati dalla tabella creata in precedenza, le righe verranno ordinate in base ai valori della colonna ID in ordine crescente, che è lo stesso dell'ordine dell'indice cluster:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Quindi controllando il piano di esecuzione per quella query, verrà eseguita una scansione sull'indice cluster per ottenere i dati ordinati dall'indice come mostrato nel piano di esecuzione seguente:
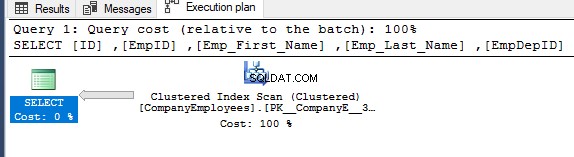
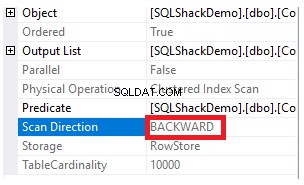
Per ottenere la direzione della scansione eseguita sull'indice cluster, fare clic con il pulsante destro del mouse sul nodo di scansione dell'indice per sfogliare le proprietà del nodo. Dalle proprietà del nodo Scansione indice cluster, la proprietà Direzione scansione visualizzerà la direzione della scansione eseguita sull'indice all'interno di quella query, che è Scansione in avanti come mostrato nell'istantanea seguente:
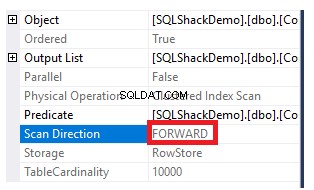
La direzione di scansione dell'indice può anche essere recuperata dal piano di esecuzione XML dalla proprietà ScanDirection nel nodo IndexScan, come mostrato di seguito:

Si supponga di dover recuperare il valore ID massimo dalla tabella CompanyEmployees creata in precedenza, utilizzando la query T-SQL seguente:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Quindi rivedere il piano di esecuzione generato dall'esecuzione di quella query. Vedrai che verrà eseguita una scansione sull'indice cluster come mostrato nel piano di esecuzione seguente:
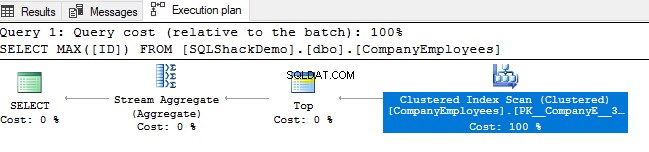
Per verificare la direzione della scansione dell'indice, esamineremo le proprietà del nodo Scansione indice cluster. Il risultato ci mostrerà che, SQL Server Engine preferisce scansionare l'indice cluster dalla fine all'inizio, che in questo caso sarà più veloce, per ottenere il valore massimo della colonna ID, poiché il index è già ordinato in base alla colonna ID, come mostrato di seguito:
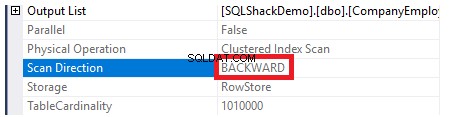
Inoltre, se proviamo a recuperare i dati della tabella precedentemente creati utilizzando la seguente istruzione SELECT, i record verranno ordinati in base ai valori della colonna ID, ma questa volta, in modo opposto all'ordine dell'indice cluster, specificando l'opzione di ordinamento DESC nell'ORDER BY clausola mostrata di seguito:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
Se controlli il piano di esecuzione generato dopo l'esecuzione della precedente query SELECT, vedrai che verrà eseguita una scansione sull'indice cluster per ottenere i record richiesti della tabella, come mostrato di seguito:
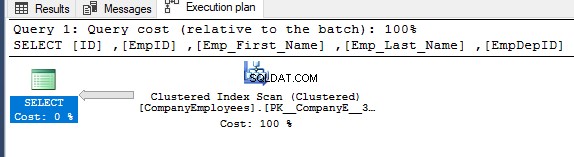
Le proprietà del nodo Scansione indice cluster mostreranno che la direzione della scansione che il motore di SQL Server preferisce è la direzione Scansione all'indietro, che è più veloce in questo caso, a causa dell'ordinamento dei dati opposto all'ordinamento reale dell'indice cluster, tenendo conto che l'indice è già ordinato in ordine crescente in base alla colonna ID, come mostrato di seguito:
Confronto delle prestazioni
Supponiamo di avere le seguenti dichiarazioni SELECT che recuperano informazioni su tutti i dipendenti che sono stati assunti a partire dal 2010, due volte; la prima volta il set di risultati restituito verrà ordinato in ordine crescente in base ai valori della colonna ID e la seconda volta il set di risultati restituito verrà ordinato in ordine decrescente in base ai valori della colonna ID utilizzando le istruzioni T-SQL seguenti:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
Verificando i piani di esecuzione che vengono generati eseguendo le due query SELECT, il risultato mostrerà che verrà eseguita una scansione sull'indice cluster nelle due query per recuperare i dati, ma la direzione della scansione nella prima query sarà Inoltra Scansione a causa dell'ordinamento dei dati ASC e Scansione all'indietro nella seconda query a causa dell'utilizzo dell'ordinamento dei dati DESC, per sostituire la necessità di riordinare nuovamente i dati, come mostrato di seguito:
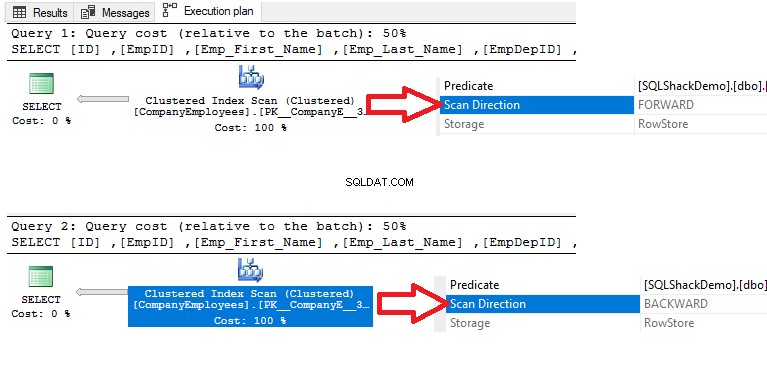
Inoltre, se controlliamo le statistiche di esecuzione IO e TIME delle due query, vedremo che entrambe le query eseguono le stesse operazioni IO e consumano valori prossimi all'esecuzione e al tempo della CPU.
Questi valori ci mostrano quanto sia intelligente il motore di SQL Server quando si sceglie la direzione di scansione dell'indice più adatta e veloce per recuperare i dati per l'utente, ovvero Forward Scan nel primo caso e Backward Scan nel secondo caso, come chiaro dalle statistiche seguenti :

Visitiamo nuovamente l'esempio MAX precedente. Si supponga di dover recuperare l'ID massimo dei dipendenti che sono stati assunti nel 2010 e successivi. Per questo, utilizzeremo le seguenti istruzioni SELECT che ordinano i dati letti in base al valore della colonna ID con l'ordinamento ASC nella prima query e con l'ordinamento DESC nella seconda query:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Vedrai dai piani di esecuzione generati dall'esecuzione delle due istruzioni SELECT, che entrambe le query eseguiranno un'operazione di scansione sull'indice cluster per recuperare il valore ID massimo, ma in direzioni di scansione diverse; Scansione in avanti nella prima query e Scansione all'indietro nella seconda query, a causa delle opzioni di ordinamento ASC e DESC, come mostrato di seguito:
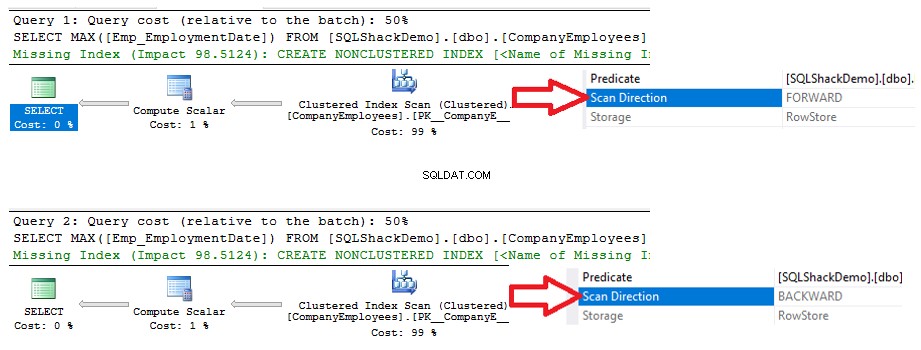
Le statistiche IO generate dalle due query non mostreranno differenze tra le due direzioni di scansione. Ma le statistiche TIME mostrano una grande differenza tra il calcolo dell'ID massimo delle righe quando queste righe vengono scansionate dall'inizio alla fine usando il metodo Forward Scan e la scansione dalla fine all'inizio usando il metodo Backward Scan. Dal risultato di seguito è chiaro che il metodo di scansione all'indietro è il metodo di scansione ottimale per ottenere il valore ID massimo:
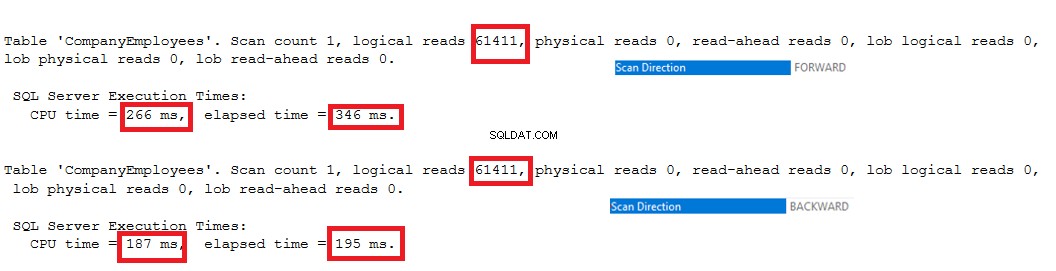
Ottimizzazione delle prestazioni
Come accennato all'inizio di questo articolo, l'indicizzazione delle query è la chiave più importante nel processo di ottimizzazione e ottimizzazione delle prestazioni. Nella query precedente, se si prevede di aggiungere un indice non cluster nella colonna EmploymentDate della tabella CompanyEmployees, utilizzando l'istruzione CREATE INDEX T-SQL di seguito:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Controllando i piani di esecuzione generati dopo l'esecuzione delle due query, vedrai che verrà eseguita una ricerca sull'indice non cluster appena creato ed entrambe le query eseguiranno la scansione dell'indice dall'inizio alla fine utilizzando il metodo Forward Scan, senza la necessità per eseguire una scansione all'indietro per accelerare il recupero dei dati, anche se abbiamo utilizzato l'opzione di ordinamento DESC nella seconda query. Ciò si è verificato a causa della ricerca diretta dell'indice senza la necessità di eseguire una scansione completa dell'indice, come mostrato nel confronto dei piani di esecuzione di seguito:
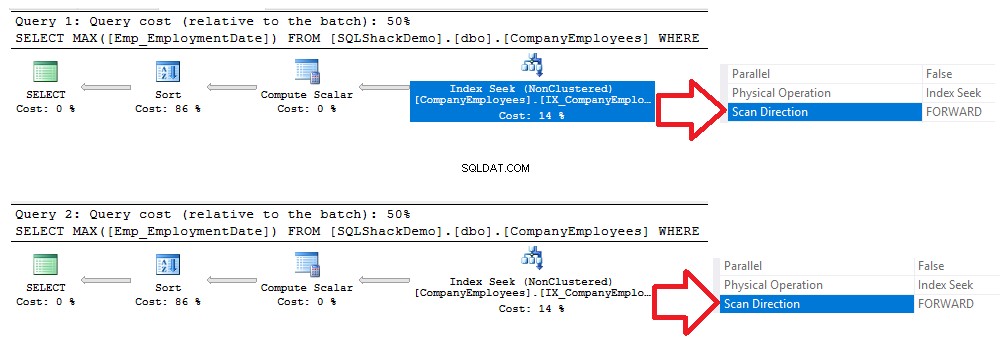
Lo stesso risultato può essere derivato dalle statistiche IO e TIME generate dalle due query precedenti, in cui le due query consumeranno la stessa quantità di tempo di esecuzione, operazioni di CPU e IO, con una differenza molto piccola, come mostrato nell'istantanea delle statistiche di seguito :

Link utili:
- Descritti indici cluster e non cluster
- Crea indici non cluster
- Ottimizzazione delle prestazioni di SQL Server:scansione all'indietro di un indice
Strumento utile:
dbForge Index Manager – pratico componente aggiuntivo SSMS per analizzare lo stato degli indici SQL e risolvere i problemi con la frammentazione degli indici.



