In questo articolo parleremo dei checkpoint di SQL Server.
Per migliorare le prestazioni, SQL Server applica le modifiche alle pagine del database in memoria. Spesso, questa memoria è chiamata cache del buffer o pool di buffer. SQL Server non scarica queste pagine su disco dopo ogni modifica. Al contrario, il motore di database esegue di volta in volta operazioni di checkpoint su ciascun database. Il PUNTO DI CONTROLLO l'operazione scrive le pagine sporche (pagine modificate in memoria correnti) e scrive anche i dettagli sul registro delle transazioni.
SQL Server supporta quattro tipi di checkpoint:
EXEC sp_configure 'recovery interval', 'seconds'
Con il modello di ripristino SIMPLE, viene attivato anche un checkpoint automatico quando il registro delle transazioni è pieno al 70%.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Quando lo si imposta, considerare le capacità del sottosistema di I/O sottostante. Potrebbe avere senso impostare un valore più basso per sottosistemi I/O più veloci (ad es. SSD). Fai attenzione, questa impostazione persiste durante il backup e il ripristino, quindi il ripristino su hardware più lento potrebbe causare problemi di prestazioni dovuti al carico eccessivo di I/O.
CHECKPOINT [ checkpoint_duration ]
durata_checkpoint è un numero intero utilizzato per definire la quantità di tempo in cui un checkpoint deve essere completato. Questo parametro determina anche quante risorse sono assegnate all'operazione di checkpoint. Se il parametro non è specificato, il checkpoint verrà completato nel tempo che riduce al minimo l'impatto sulle prestazioni.
- Un file di dati viene aggiunto o rimosso
- Si verifica un arresto del database (per qualsiasi motivo)
- Viene creato un backup o uno snapshot del database
- Viene eseguito un comando DBCC che crea uno snapshot del database nascosto (o ad es. DBCC_CHECKDB, DBCC_CHECKTABLE).
Perché i checkpoint sono utili?
I checkpoint riducono i tempi di ripristino in caso di arresto anomalo. Ciò accade perché le pagine dei file di dati non vengono scritte su disco contemporaneamente ai record di registro. In memoria sono presenti pagine di file di dati più aggiornate rispetto alle pagine di file di dati su disco.
I checkpoint riducono l'I/O su disco e migliorano le prestazioni. Il motivo per cui le pagine dei file di dati non vengono scritte su disco al momento del commit della transazione è ridurre il numero di operazioni di I/O. Immagina le diverse migliaia di transazioni UPDATE in una singola pagina di dati. È più efficiente scrivere una pagina di dati su disco solo una volta, durante un checkpoint, piuttosto che dopo ogni modifica.
Pagine pulite e sporche
Il pool di buffer mantiene in memoria un certo numero di pagine di dati. Esistono due tipi di pagine di dati:pulite e sporco . Una pagina pulita è una pagina che non è stata modificata poiché è stata l'ultima letta dal disco o scritta su disco. Una pagina sporca è una pagina che è stata modificata e le modifiche non sono state scritte su disco. I checkpoint si riferiscono a "pagine sporche".
Le informazioni sulla pagina possono essere visualizzate utilizzando sys.dm_os_buffer_descriptors . Vediamo cosa restituisce questa funzione:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
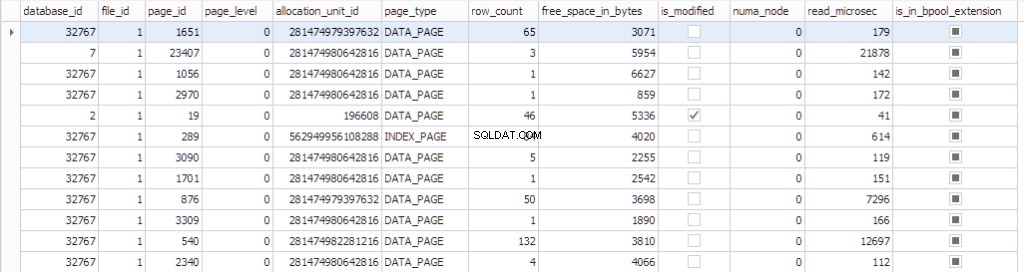
Ad ogni pagina è associata una struttura di controllo che tiene traccia dello stato della pagina:
- Un database con datdabase_id 32767 è un database delle risorse di sola lettura che contiene tutti gli oggetti di sistema.
- id_file , id_pagina , allocation_unit_id quella pagina appartiene.
- Che tipo di pagina è:pagina dati o pagina indice.
- Il numero di righe nella pagina.
- Lo spazio libero sulla pagina
- Se la pagina è sporca o meno
- Il numa_node a cui appartiene la pagina particolare
- Alcune informazioni sull'algoritmo utilizzato di recente
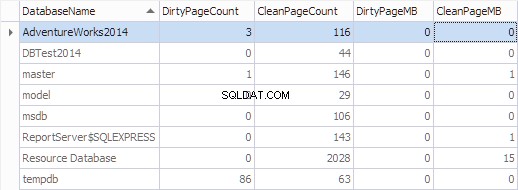
Aggreghiamo queste informazioni per database utilizzando il seguente codice:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Meccanismo checkpoint
Quando si verifica il checkpoint, scrive tutte le pagine sporche su disco. Le pagine contrassegnate come sporche non appena presentano alcune modifiche. Non importa se la transazione che ha effettuato la modifica è stata confermata o annullata al momento del checkpoint. Dopo che le pagine sono state scritte su disco, il bit "sporco" viene cancellato. Quando si verifica il checkpoint, vengono eseguite le seguenti azioni:
- Un nuovo record di registro indica l'inizio di un checkpoint
- I record di registro aggiuntivi vengono visualizzati con informazioni sul checkpoint (come lo stato del registro delle transazioni al momento dell'avvio del checkpoint)
- Tutte le pagine sporche vengono scritte su disco
- Segna l'LSN del checkpoint nella pagina di avvio del database (in dbi_checkptLSN), questo è fondamentale per il ripristino da crash
- Se viene utilizzato il modello di ripristino SIMPLE, prova a cancellare il registro
- Un record di registro finale indica che il checkpoint è terminato
È possibile che i checkpoint di più database si verifichino in parallelo. SQL Server 2000 è stato limitato a un checkpoint alla volta. Quando il gestore del buffer scrive una pagina, cerca le pagine sporche adiacenti che possono essere incluse in un'unica operazione di raccolta-scrittura. Inoltre, il pool di buffer cercherà di assicurarsi di non sovraccaricare il sottosistema di I/O. Tiene traccia del tempo impiegato dal completamento dell'I/O. Se la latenza di scrittura supera i 20 ms durante il checkpoint, si rallenta. Durante lo spegnimento, la soglia di limitazione aumenta a 100 ms. Puoi trovare una spiegazione più dettagliata qui. È possibile utilizzare l'opzione di avvio "-kXX" non documentata per impostare la velocità di I/O del checkpoint a XX MB/s.
Quando la pagina del file di dati viene scritta su disco da un checkpoint, la registrazione write-ahead garantisce che tutti i record di registro che interessano quella pagina debbano essere scritti prima nel registro delle transazioni su disco. Tutti i record di registro fino all'ultimo incluso che ha interessato la pagina vengono scritti, indipendentemente dalla transazione di cui fanno parte. I record di registro vengono scritti in tre modi:
- Quando una transazione viene confermata o interrotta
- Quando la pagina del file di dati viene scritta su disco
- Quando un blocco di log raggiunge la dimensione massima di 60 KB e viene terminato forzatamente
Registro del checkpoint
I checkpoint scrivono più record di registro nel registro delle transazioni:
- LOP_BEGIN_CKPT — significa che il checkpoint è iniziato
- LOP_XACT_CKPT con contesto NULL (solo se sono presenti transazioni non vincolate al momento dell'inizio del checkpoint) — contiene un conteggio del numero di transazioni non vincolate. Elenca anche gli LSN dei record di registro LOP_BEGIN_XACT delle transazioni non vincolate.
- LOP_BEGIN_CKPT con un contesto di LOP_BOOT_PAGE_CKPT (solo SQL Server 2012):significa che la pagina di avvio è stata aggiornata.
- LOP_END_CKPT — indica la fine del checkpoint.
Monitoraggio checkpoint
Può essere utile correlare i checkpoint che si verificano con picchi di I/O in modo che possano essere apportate modifiche al database specifico (per il sottosistema di I/O) per alleviare il picco di I/O se sovraccarica il sottosistema di I/O. Ad esempio, eseguire checkpoint manuali più frequenti o configurare un intervallo di ripristino inferiore in SQL Server 2012 con checkpoint indiretti. Ciò produrrà un carico di I/O più costante senza picchi elevati che sovraccaricano il sottosistema di I/O. Tuttavia, la causa principale potrebbe essere l'esecuzione di più I/O a causa di una modifica da qualche parte, quindi non limitarti ad accettare un improvviso aumento dell'attività del checkpoint senza indagare sul motivo per cui si è verificato.
Il contatore Buffer Manager/Pagine Checkpoint/sec non è specifico del database, quindi l'identificazione del database coinvolto richiede flag di traccia o eventi estesi.
Traccia bandiera 3502 scrive i messaggi nel registro degli errori per il quale si sta verificando il checkpoint del database.
Traccia bandiera 3504 scrive informazioni più dettagliate su quante pagine sono state scritte e sulla latenza di scrittura media.
Questi flag di traccia sono sicuri da usare nella produzione per un numero limitato di lime. Tutto ciò che fanno è stampare i messaggi nel registro degli errori.
Se desideri utilizzare gli eventi estesi, puoi utilizzare due eventi:checkpoint_begin e checkpoint_end.
Riepilogo
In questo articolo abbiamo parlato dei checkpoint in SQL Server, il meccanismo principale per scrivere le pagine dei file di dati su disco dopo che sono state modificate.