I tuoi dati sono probabilmente le risorse più preziose dell'azienda, quindi dovresti avere un piano di ripristino di emergenza (DRP) per prevenire la perdita di dati in caso di incidente o guasto dell'hardware. Un backup è la forma più semplice di DR. Potrebbe non essere sempre sufficiente per garantire un Recovery Point Objective (RPO) accettabile, ma è un buon primo approccio. Inoltre, dovresti definire un Recovery Time Objective (RTO) in base ai requisiti della tua azienda. Ci sono molti modi per raggiungere il valore RTO, dipende dagli obiettivi aziendali.
In questo blog vedremo come utilizzare pgBackRest per il backup di PostgreSQL e TimescaleDB e come utilizzare una delle funzionalità più importanti di questo strumento di backup, la combinazione di backup completo, incrementale e differenziale, per ridurre al minimo i tempi di inattività.
Cos'è pgBackRest?
Esistono diversi tipi di backup per i database:
- Logico:il backup è archiviato in un formato leggibile come SQL.
- Fisico:il backup contiene dati binari.
- Completo/Incrementale/Differenziale:la definizione di questi tre tipi di backup è implicita nel nome. Il backup completo è una copia completa di tutti i tuoi dati. Il backup incrementale esegue il backup solo dei dati che sono stati modificati rispetto al backup precedente e il backup differenziale contiene solo i dati che sono stati modificati dall'ultimo backup completo eseguito. I backup incrementali e differenziali sono stati introdotti per ridurre la quantità di tempo e l'utilizzo dello spazio su disco necessari per eseguire un backup completo.
pgBackRest è uno strumento di backup open source che crea backup fisici con alcuni miglioramenti rispetto al classico strumento pg_basebackup. Possiamo utilizzare pgBackRest per eseguire una copia iniziale del database per la replica in streaming utilizzando un backup esistente, oppure possiamo utilizzare l'opzione delta per ricostruire un vecchio server di standby.
Alcune delle funzionalità più importanti di pgBackRest sono:
- Backup e ripristino in parallelo
- Funzionamento locale o remoto
- Backup completi, incrementali e differenziali
- Rotazione backup e scadenza archivio
- Verifica dell'integrità del backup
- Riprendi backup
- Ripristino Delta
- Crittografia
Ora, vediamo come possiamo utilizzare pgBackRest per eseguire il backup dei nostri database PostgreSQL e TimescaleDB.
Come usare pgBackRest
Per questo test, utilizzeremo CentOS 7 come sistema operativo e PostgreSQL 11 come server di database. Supponiamo che tu abbia installato il database, in caso contrario puoi seguire questi collegamenti per distribuire sia PostgreSQL che TimescaleDB in modo semplice utilizzando ClusterControl.
Per prima cosa, dobbiamo installare il pacchetto pgbackrest.
$ yum install pgbackrestpgBackRest può essere utilizzato dalla riga di comando o da un file di configurazione che si trova per impostazione predefinita in /etc/pgbackrest.conf su CentOS7. Questo file contiene le seguenti righe:
[global]
repo1-path=/var/lib/pgbackrest
#[main]
#pg1-path=/var/lib/pgsql/10/dataPuoi controllare questo link per vedere quale parametro possiamo aggiungere in questo file di configurazione.
Aggiungeremo le seguenti righe:
[testing]
pg1-path=/var/lib/pgsql/11/dataAssicurati di aver aggiunto la seguente configurazione nel file postgresql.conf (queste modifiche richiedono il riavvio del servizio).
archive_mode = on
archive_command = 'pgbackrest --stanza=testing archive-push %p'
max_wal_senders = 3
wal_level = logicalOra, facciamo un backup di base. Innanzitutto, dobbiamo creare una "stanza", che definisce la configurazione di backup per uno specifico cluster di database PostgreSQL o TimescaleDB. La sezione della stanza deve definire il percorso del cluster di database e l'host/utente se il cluster di database è remoto.
$ pgbackrest --stanza=testing --log-level-console=info stanza-create
2019-04-29 21:46:36.922 P00 INFO: stanza-create command begin 2.13: --log-level-console=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
2019-04-29 21:46:37.475 P00 INFO: stanza-create command end: completed successfully (554ms)E poi, possiamo eseguire il comando check per convalidare la configurazione.
$ pgbackrest --stanza=testing --log-level-console=info check
2019-04-29 21:51:09.893 P00 INFO: check command begin 2.13: --log-level-console=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
2019-04-29 21:51:12.090 P00 INFO: WAL segment 000000010000000000000001 successfully stored in the archive at '/var/lib/pgbackrest/archive/testing/11-1/0000000100000000/000000010000000000000001-f29875cffe780f9e9d9debeb0b44d945a5165409.gz'
2019-04-29 21:51:12.090 P00 INFO: check command end: completed successfully (2197ms)Per eseguire il backup, esegui il seguente comando:
$ pgbackrest --stanza=testing --type=full --log-level-stderr=info backup
INFO: backup command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing --type=full
WARN: option repo1-retention-full is not set, the repository may run out of space
HINT: to retain full backups indefinitely (without warning), set option 'repo1-retention-full' to the maximum.
INFO: execute non-exclusive pg_start_backup() with label "pgBackRest backup started at 2019-04-30 15:43:21": backup begins after the next regular checkpoint completes
INFO: backup start archive = 000000010000000000000006, lsn = 0/6000028
WARN: aborted backup 20190429-215508F of same type exists, will be cleaned to remove invalid files and resumed
INFO: backup file /var/lib/pgsql/11/data/base/16384/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/13878/1255 (608KB, 3%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/13877/1255 (608KB, 5%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
. . .
INFO: full backup size = 31.8MB
INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive
INFO: backup stop archive = 000000010000000000000006, lsn = 0/6000130
INFO: new backup label = 20190429-215508F
INFO: backup command end: completed successfully (12810ms)
INFO: expire command begin
INFO: option 'repo1-retention-archive' is not set - archive logs will not be expired
INFO: expire command end: completed successfully (10ms)Ora abbiamo terminato il backup con l'output "completato con successo", quindi andiamo a ripristinarlo. Interromperemo il servizio postgresql-11.
$ service postgresql-11 stop
Redirecting to /bin/systemctl stop postgresql-11.serviceE lascia vuota la datadir.
$ rm -rf /var/lib/pgsql/11/data/*Ora, esegui il seguente comando:
$ pgbackrest --stanza=testing --log-level-stderr=info restore
INFO: restore command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
INFO: restore backup set 20190429-215508F
INFO: restore file /var/lib/pgsql/11/data/base/16384/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: restore file /var/lib/pgsql/11/data/base/13878/1255 (608KB, 3%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: restore file /var/lib/pgsql/11/data/base/13877/1255 (608KB, 5%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
. . .
INFO: write /var/lib/pgsql/11/data/recovery.conf
INFO: restore global/pg_control (performed last to ensure aborted restores cannot be started)
INFO: restore command end: completed successfully (10819ms)Quindi, avvia il servizio postgresql-11.
$ service postgresql-11 stopE ora abbiamo il nostro database attivo e funzionante.
$ psql -U app_user world
world=> select * from city limit 5;
id | name | countrycode | district | population
----+----------------+-------------+---------------+------------
1 | Kabul | AFG | Kabol | 1780000
2 | Qandahar | AFG | Qandahar | 237500
3 | Herat | AFG | Herat | 186800
4 | Mazar-e-Sharif | AFG | Balkh | 127800
5 | Amsterdam | NLD | Noord-Holland | 731200
(5 rows)Ora, vediamo come possiamo fare un backup differenziale.
$ pgbackrest --stanza=testing --type=diff --log-level-stderr=info backup
INFO: backup command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing --type=diff
WARN: option repo1-retention-full is not set, the repository may run out of space
HINT: to retain full backups indefinitely (without warning), set option 'repo1-retention-full' to the maximum.
INFO: last backup label = 20190429-215508F, version = 2.13
INFO: execute non-exclusive pg_start_backup() with label "pgBackRest backup started at 2019-04-30 21:22:58": backup begins after the next regular checkpoint completes
INFO: backup start archive = 00000002000000000000000B, lsn = 0/B000028
WARN: a timeline switch has occurred since the last backup, enabling delta checksum
INFO: backup file /var/lib/pgsql/11/data/base/16429/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/16429/2608 (448KB, 8%) checksum 53bd7995dc4d29226b1ad645995405e0a96a4a7b
. . .
INFO: diff backup size = 40.1MB
INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive
INFO: backup stop archive = 00000002000000000000000B, lsn = 0/B000130
INFO: new backup label = 20190429-215508F_20190430-212258D
INFO: backup command end: completed successfully (23982ms)
INFO: expire command begin
INFO: option 'repo1-retention-archive' is not set - archive logs will not be expired
INFO: expire command end: completed successfully (14ms)Per backup più complessi puoi seguire la guida utente di pgBackRest.
Come accennato in precedenza, puoi utilizzare la riga di comando o i file di configurazione per gestire i tuoi backup.
Come utilizzare pgBackRest in ClusterControl
Dalla versione 1.7.2, ClusterControl ha aggiunto il supporto per pgBackRest per il backup dei database PostgreSQL e TimescaleDB, quindi vediamo come possiamo usarlo da ClusterControl.
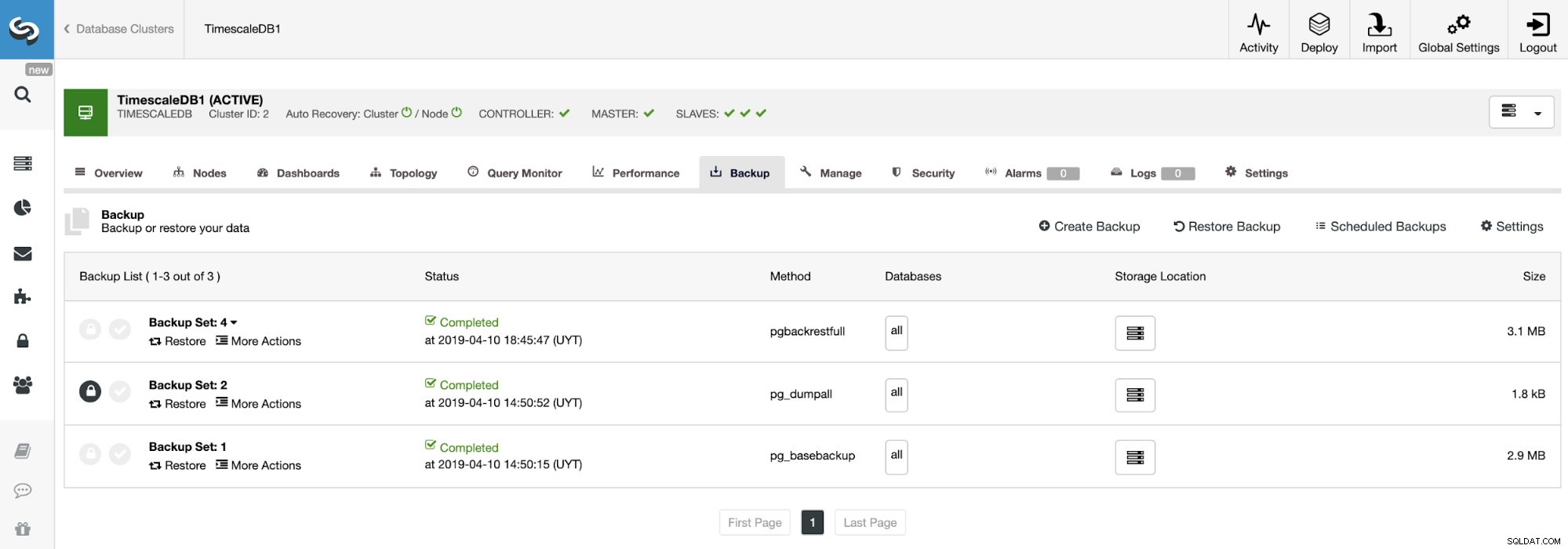
Creazione di un backup
Per questa attività, vai su ClusterControl -> Seleziona Cluster -> Backup -> Crea backup.
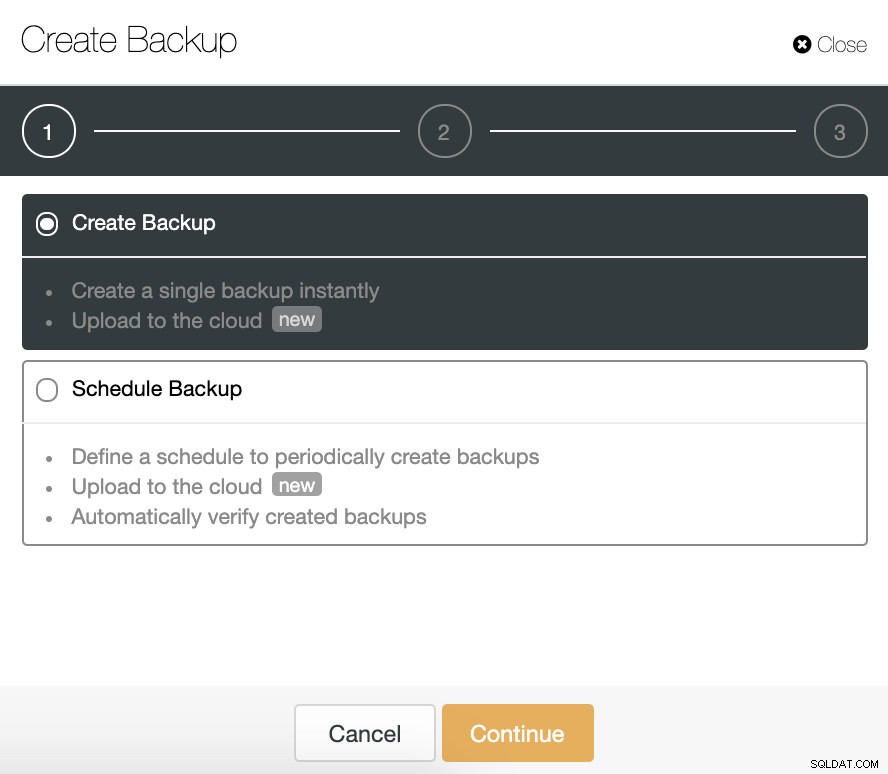
Possiamo creare un nuovo backup o configurarne uno pianificato. Per il nostro esempio, creeremo istantaneamente un singolo backup.
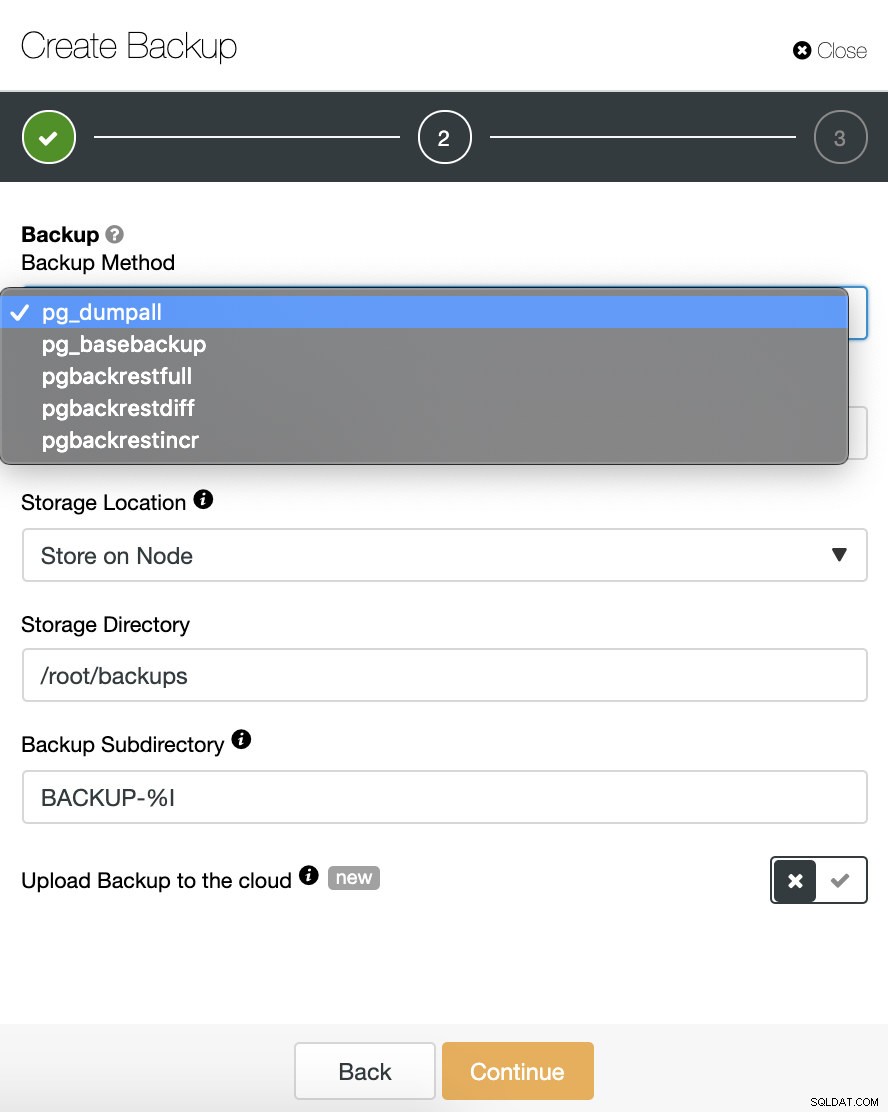
Dobbiamo scegliere un metodo, il server da cui verrà eseguito il backup e dove vogliamo archiviare il backup. Possiamo anche caricare il nostro backup sul cloud (AWS, Google o Azure) abilitando il pulsante corrispondente.
In questo caso, sceglieremo il metodo pgbackrestfull per eseguire un backup completo iniziale. Quando selezioniamo questa opzione, vedremo la seguente nota rossa:
"Durante il primo tentativo di eseguire il backup di pgBackRest, ClusterControl riconfigura il nodo (distribuisce e configura pgBackRest) e successivamente il nodo db deve essere riavviato prima."
Quindi, per favore, tienilo in considerazione per il primo tentativo di backup.
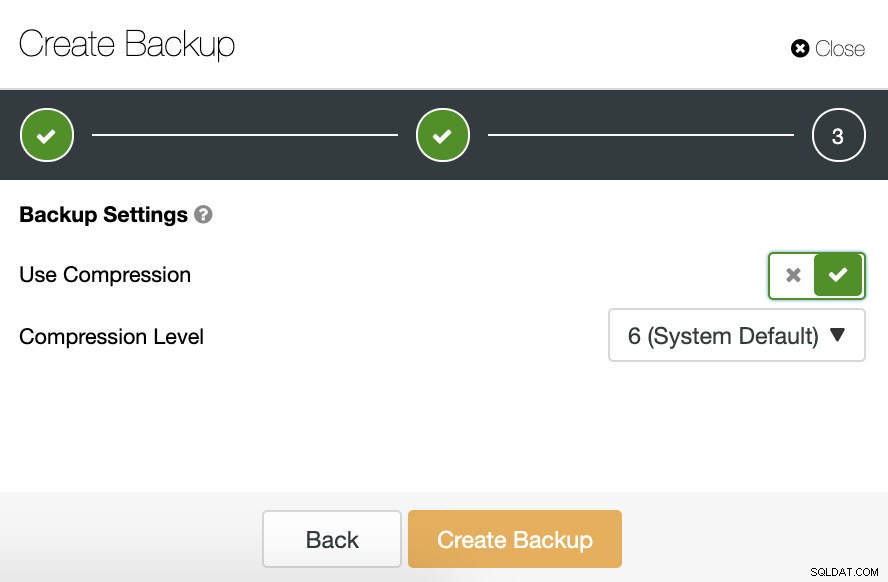
Quindi specifichiamo l'uso della compressione e il livello di compressione per il nostro backup.
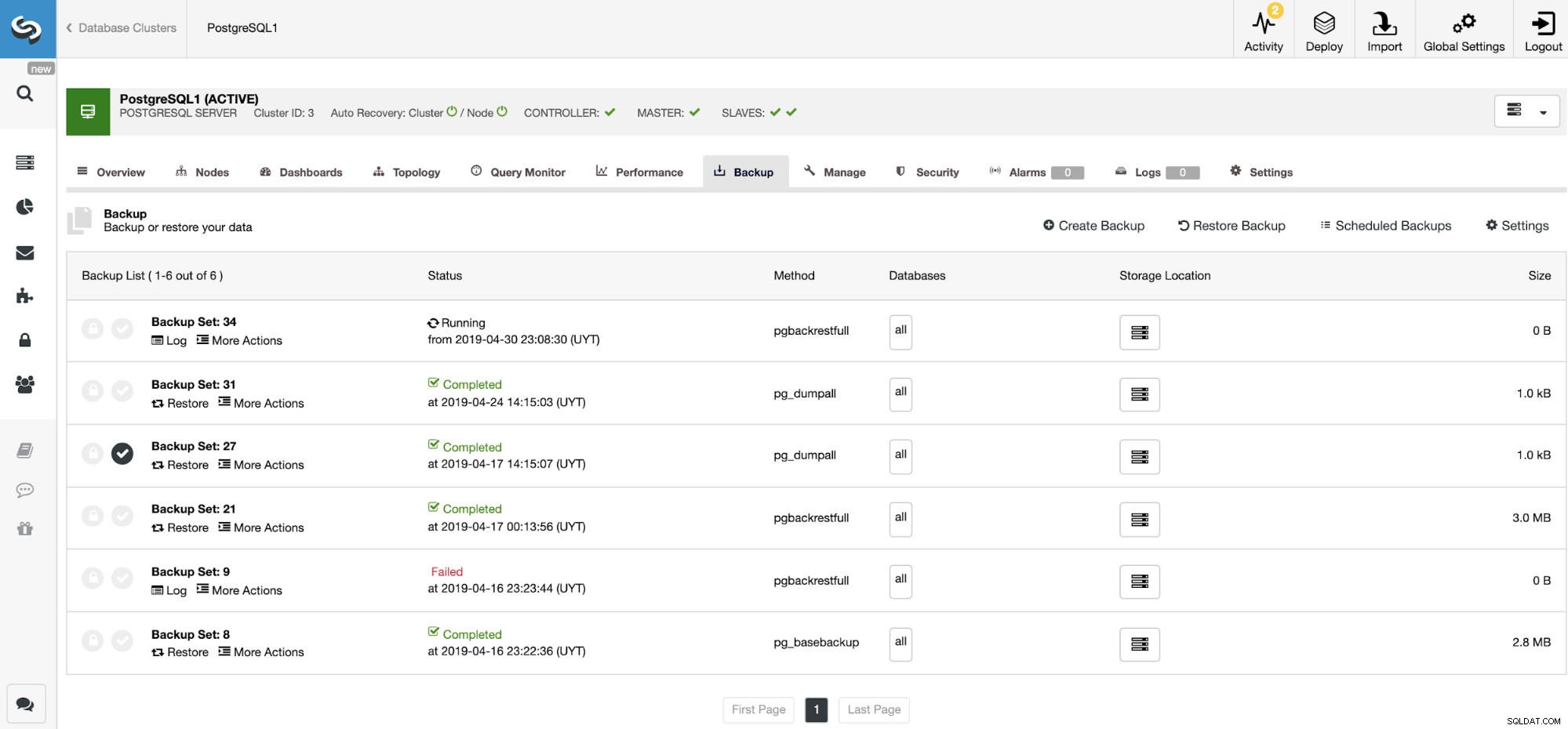
Nella sezione di backup, possiamo vedere lo stato di avanzamento del backup e informazioni come il metodo, le dimensioni, la posizione e altro.
I passaggi sono gli stessi per creare un backup differenziale incrementale. Dobbiamo solo scegliere il metodo desiderato durante la creazione del backup.
Ripristino di un backup
Una volta terminato il backup, possiamo ripristinarlo utilizzando ClusterControl. Per questo, nella nostra sezione di backup (ClusterControl -> Seleziona cluster -> Backup), possiamo selezionare "Ripristina backup" o direttamente "Ripristina" sul backup che vogliamo ripristinare.
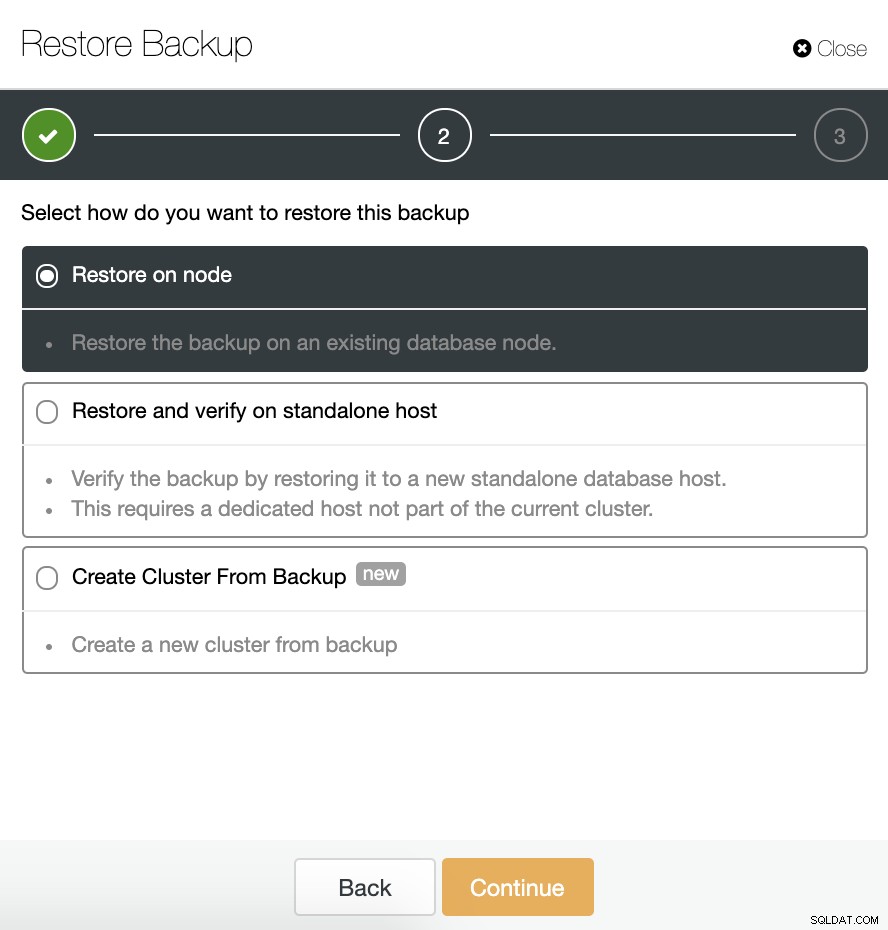
Abbiamo tre opzioni per ripristinare il backup. Possiamo ripristinare il backup in un nodo di database esistente, ripristinare e verificare il backup su un host autonomo o creare un nuovo cluster dal backup.
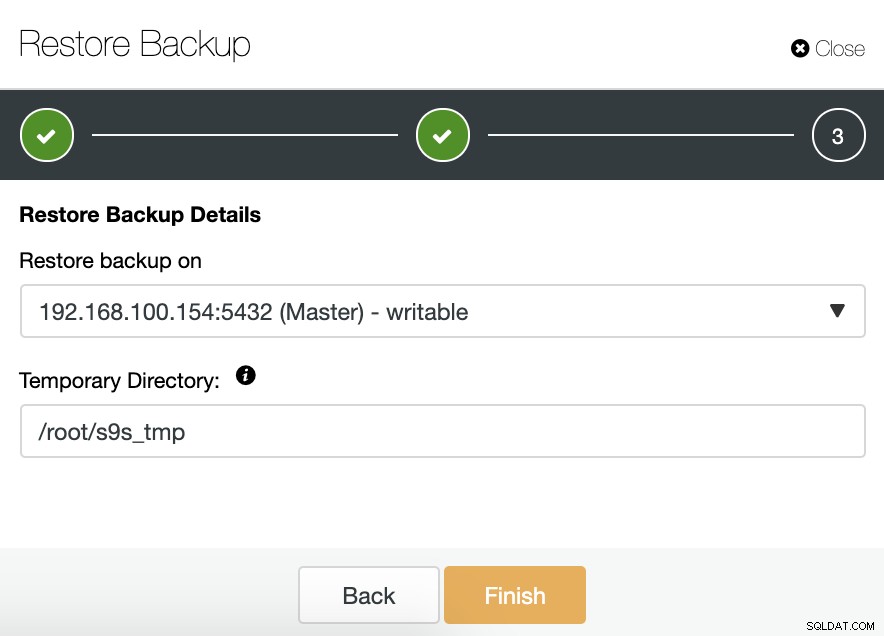
Se scegliamo l'opzione Ripristina su nodo, dobbiamo specificare il nodo Master, perché è l'unico scrivibile nel cluster.
Possiamo monitorare l'avanzamento del nostro ripristino dalla sezione Attività nel nostro ClusterControl.
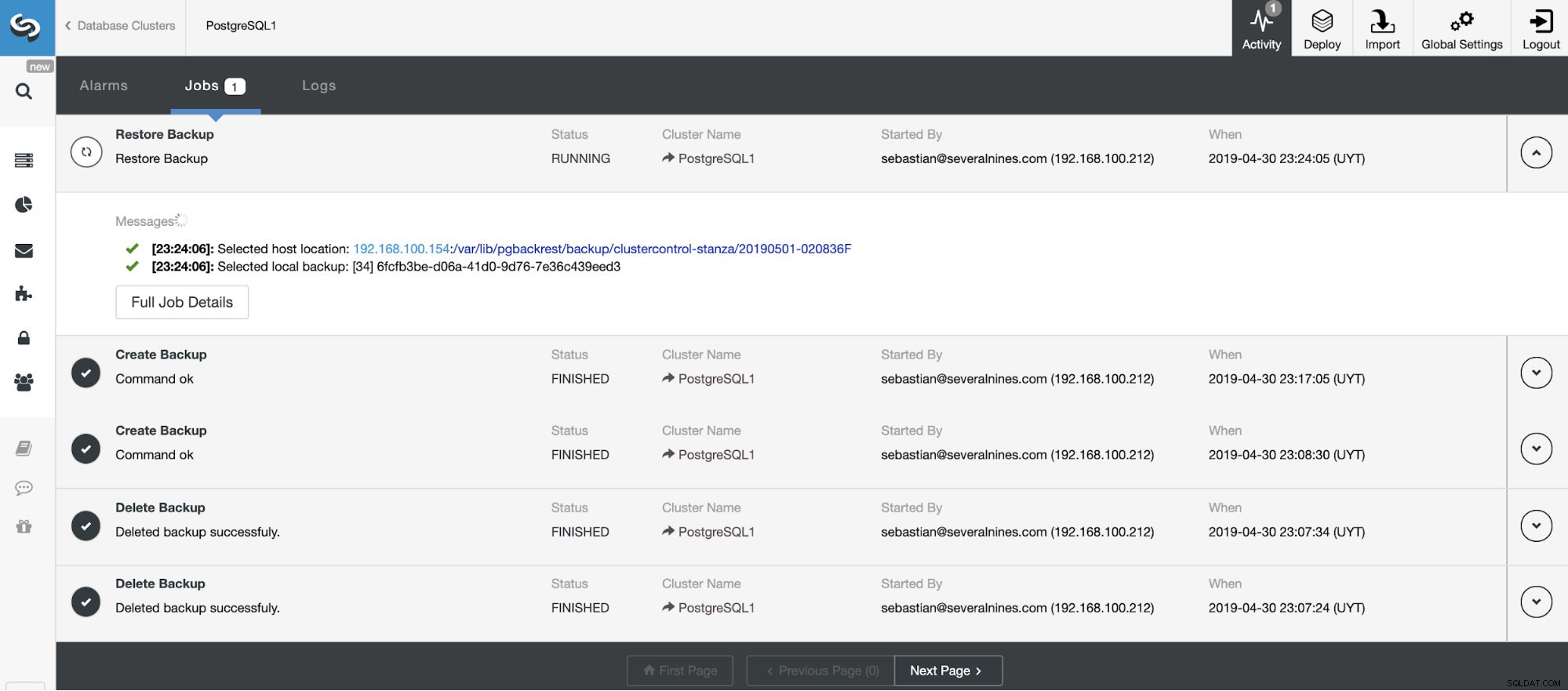
Verifica automatica del backup
Un backup non è un backup se non è ripristinabile. La verifica dei backup è qualcosa che di solito viene trascurato da molti. Vediamo come ClusterControl può automatizzare la verifica dei backup di PostgreSQL e TimescaleDB ed evitare sorprese.
In ClusterControl, seleziona il tuo cluster e vai alla sezione "Backup", quindi seleziona "Crea backup".
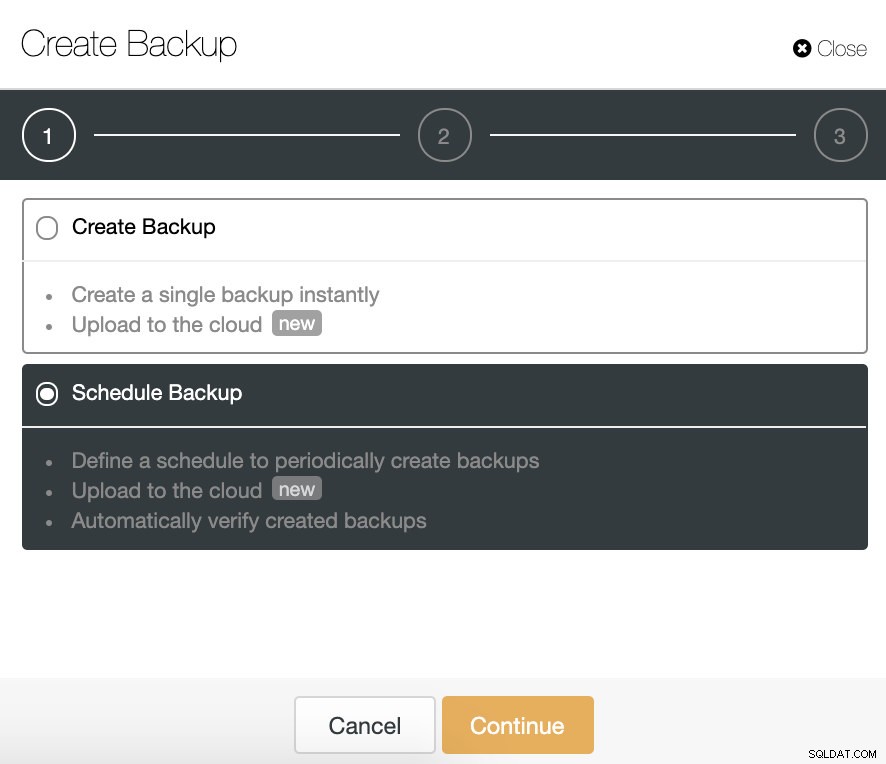
La funzione di verifica automatica del backup è disponibile per i backup pianificati. Quindi, scegliamo l'opzione "Programma backup".
Quando si pianifica un backup, oltre a selezionare le opzioni comuni come il metodo o l'archiviazione, è necessario specificare anche la pianificazione/frequenza.
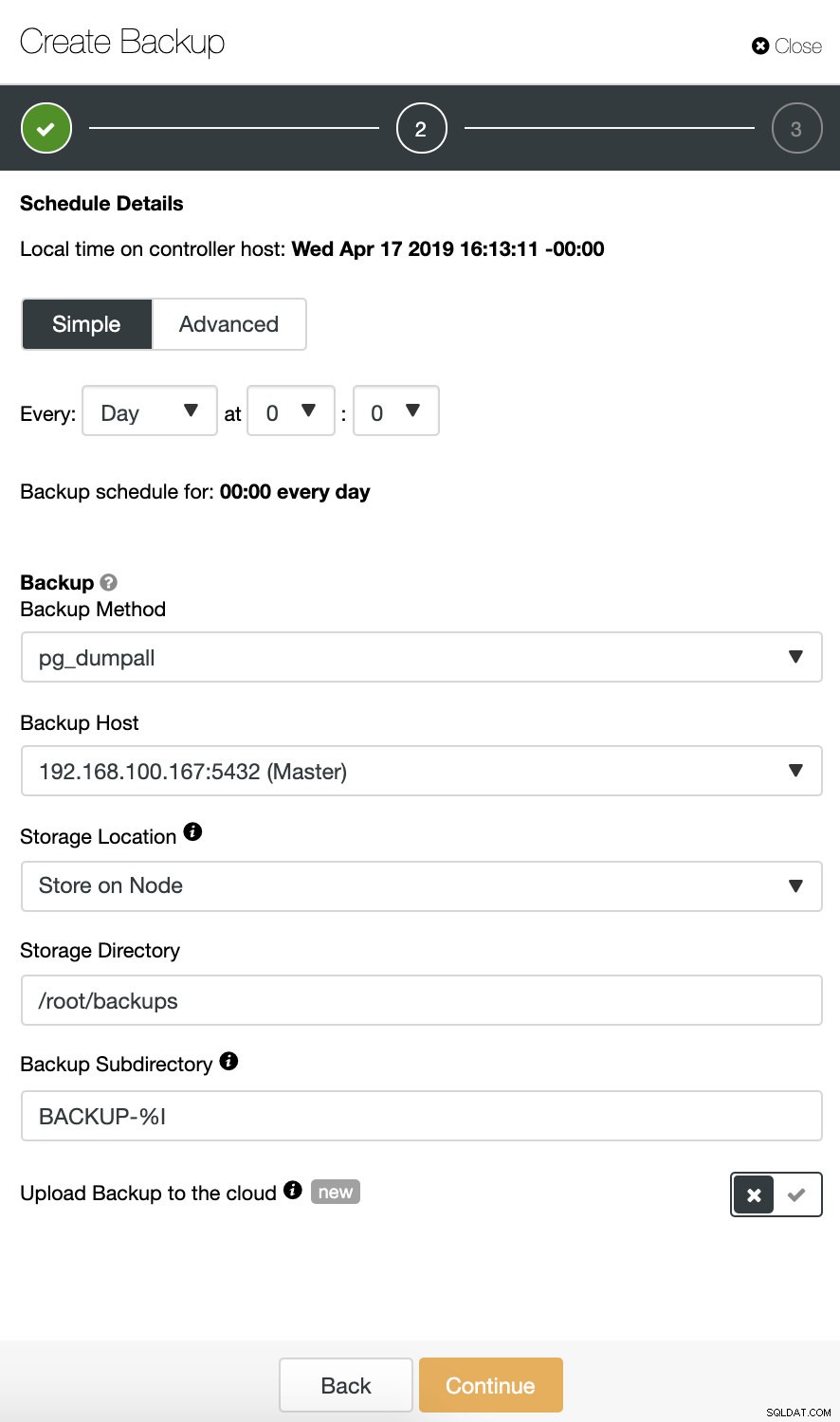
Nel passaggio successivo, possiamo comprimere il nostro backup e abilitare la funzione "Verifica backup".
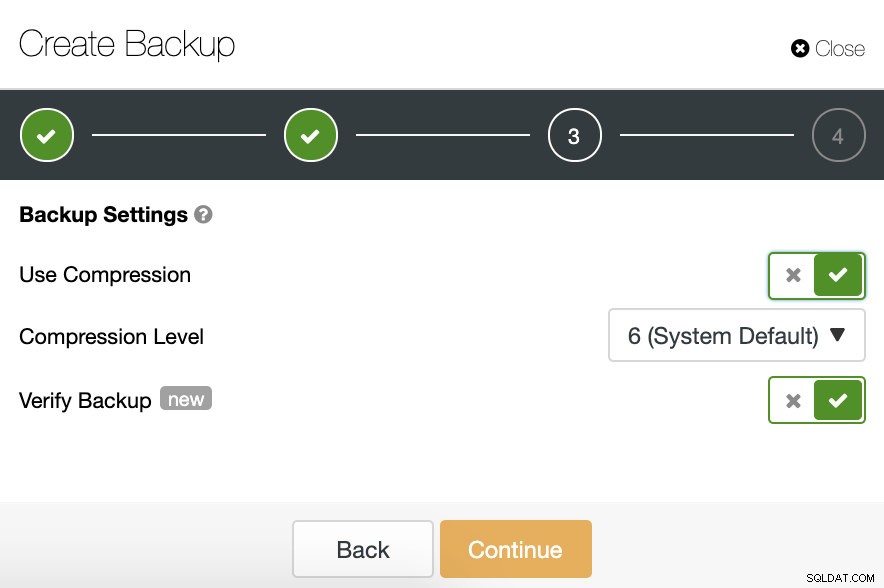
Per utilizzare questa funzionalità, abbiamo bisogno di un host (o VM) dedicato che non faccia parte del cluster.
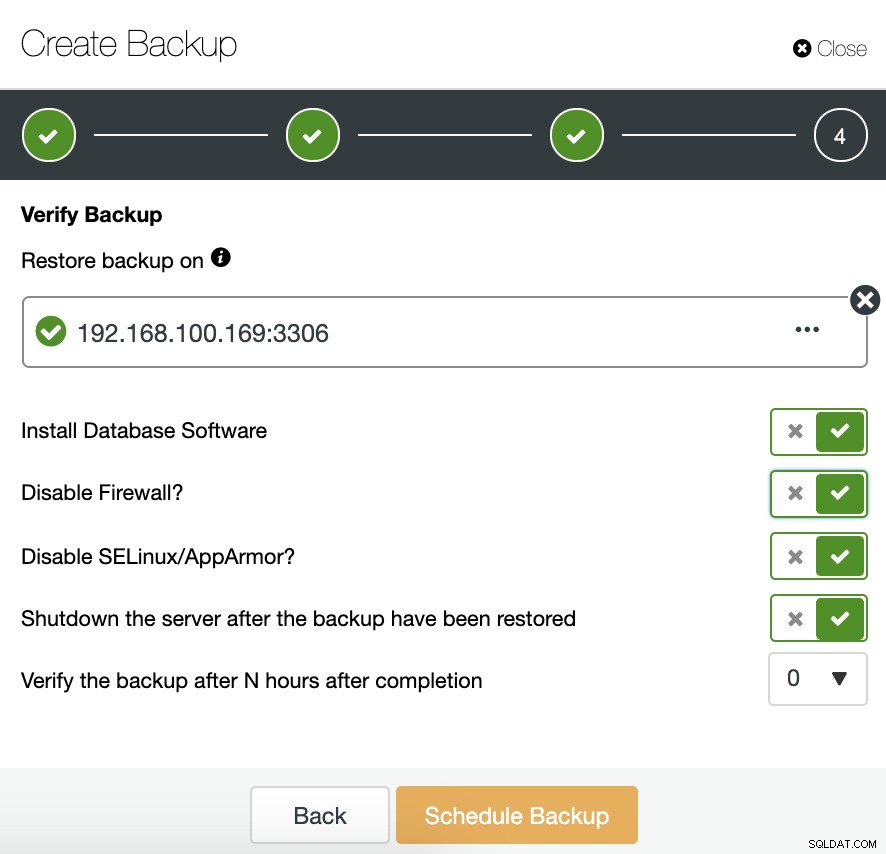
ClusterControl installerà il software e ripristinerà il backup in questo host. Dopo il ripristino, possiamo vedere l'icona di verifica nella sezione Backup ClusterControl.
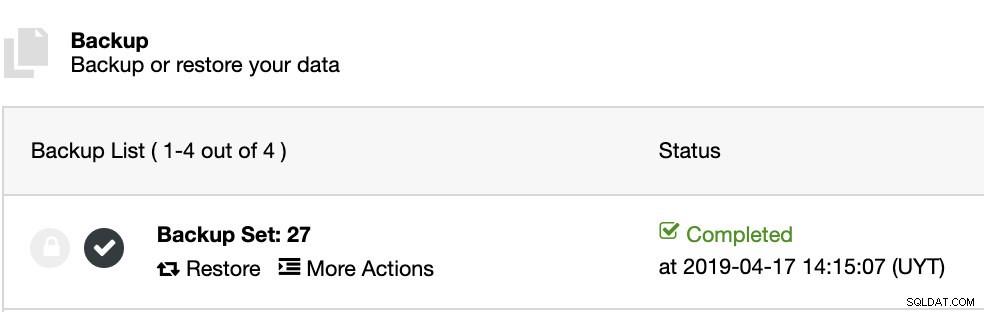
Raccomandazioni
Ci sono anche alcuni suggerimenti che possiamo tenere in considerazione durante la creazione dei nostri backup:
- Memorizza il backup in una posizione remota:non dovremmo archiviare il backup sul server del database. In caso di guasto del server, potremmo perdere il database e il backup contemporaneamente.
- Conserva una copia dell'ultimo backup sul server del database:potrebbe essere utile per un ripristino più rapido.
- Utilizza backup incrementali/differenziali:per ridurre il tempo di ripristino del backup e l'utilizzo dello spazio su disco.
- Esegui il backup dei WAL:se dobbiamo ripristinare un database dall'ultimo backup, se lo ripristinerai solo, perderai le modifiche poiché il backup è stato eseguito fino al momento del ripristino, ma se abbiamo i WAL possiamo applicare le modifiche e possiamo usare PITR.
- Utilizza backup sia logici che fisici:entrambi sono necessari per motivi diversi, ad esempio, se vogliamo ripristinare un solo database/tabella, non abbiamo bisogno del backup fisico, abbiamo solo bisogno del backup logico e sarà essere ancora più veloce del ripristino dell'intero server.
- Esegui backup dai nodi di standby (se possibile):per evitare un carico aggiuntivo sul nodo primario, è buona norma eseguire il backup dal server di standby.
- Verifica i tuoi backup:la conferma che il backup è stato eseguito non è sufficiente per garantire che il backup funzioni. Dovremmo ripristinarlo su un server autonomo e testarlo per evitare sorprese in caso di errore.
Conclusione
Come abbiamo potuto vedere, pgBackRest è una buona opzione per migliorare la nostra strategia di backup. Ti aiuta a proteggere i tuoi dati e potrebbe essere utile raggiungere l'RTO riducendo i tempi di fermo in caso di guasto. I backup incrementali possono aiutare a ridurre la quantità di tempo e spazio di archiviazione utilizzati per il processo di backup. ClusterControl può aiutarti ad automatizzare il processo di backup per i tuoi database PostgreSQL e TimescaleDB e, in caso di errore, ripristinarlo con pochi clic.