I database relazionali rappresentano i dati di un'organizzazione in tabelle che utilizzano colonne con tipi di dati diversi consentendo loro di memorizzare valori validi. Gli sviluppatori e i DBA devono conoscere e comprendere il tipo di dati appropriato per ciascuna colonna per migliorare le prestazioni delle query.
Questo articolo tratterà i tipi di dati più diffusi VARCHAR() e NVARCHAR(), il loro confronto e le revisioni delle prestazioni in SQL Server.
VARCHAR [ ( n | massimo ) ] in SQL
Il VARCHAR il tipo di dati rappresenta il non Unicode tipo di dati stringa di lunghezza variabile. Puoi memorizzare lettere, numeri e caratteri speciali al suo interno.
- N rappresenta la dimensione della stringa in byte.
- La colonna del tipo di dati VARCHAR memorizza un massimo di 8000 caratteri non Unicode.
- Il tipo di dati VARCHAR richiede 1 byte per carattere. Se non specifichi in modo esplicito il valore per N, richiede 1 byte di archiviazione.
Nota:non confondere N con un valore che rappresenta il numero di caratteri in una stringa.
La query seguente definisce il tipo di dati VARCHAR con 100 byte di dati.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Restituisce la lunghezza come 17 a causa di 1 byte per carattere, incluso uno spazio.
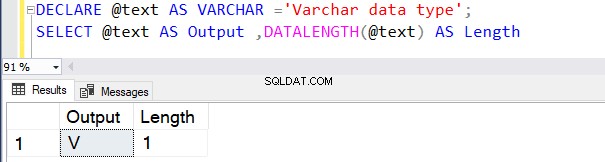
La query seguente definisce il tipo di dati VARCHAR senza alcun valore di N . Pertanto, SQL Server considera il valore predefinito come 1 byte, come mostrato di seguito.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
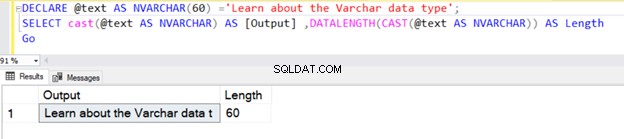
Possiamo anche usare VARCHAR usando la funzione CAST o CONVERT. Ad esempio, nei due esempi seguenti, abbiamo dichiarato una variabile con una lunghezza di 100 byte e in seguito abbiamo utilizzato l'operatore CAST.
La prima query restituisce la lunghezza come 30 perché non è stato specificato N nel tipo di dati VARCHAR dell'operatore CAST. La lunghezza predefinita è 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
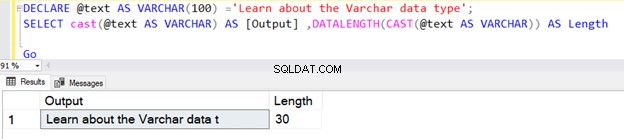
Tuttavia, se la lunghezza della stringa è inferiore a 30, prende la dimensione effettiva della stringa.

NVARCHAR [ ( n | massimo ) ] in SQL
Il NVARCHAR il tipo di dati è per Unicode tipo di dati di carattere a lunghezza variabile. Qui, N fa riferimento al set di caratteri della lingua nazionale e viene utilizzato per definire la stringa Unicode. Puoi memorizzare sia caratteri non Unicode che Unicode (kanji giapponese, Hangul coreano, ecc.).
- N rappresenta la dimensione della stringa in byte.
- Può memorizzare un massimo di 4000 caratteri Unicode e non Unicode.
- Il tipo di dati VARCHAR richiede 2 byte per carattere. Occorrono 2 byte di archiviazione se non specifichi alcun valore per N.
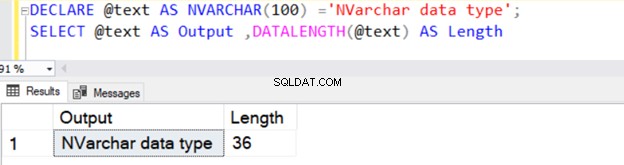
La query seguente definisce il tipo di dati VARCHAR con 100 byte di dati.
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Restituisce la lunghezza della stringa di 36 perché NVARCHAR occupa 2 byte per memoria di caratteri.
Simile al tipo di dati VARCHAR, anche NVARCHAR ha un valore predefinito di 1 carattere (2 byte) senza specificare un valore esplicito per N.
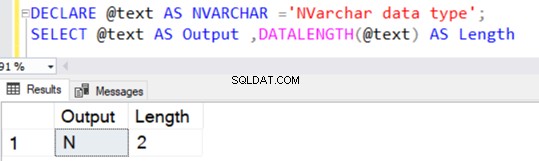
Se applichiamo la conversione NVARCHAR utilizzando la funzione CAST o CONVERT senza alcun valore esplicito di N, il valore predefinito è 30 caratteri, ovvero 60 byte.
Memorizzazione dei valori Unicode e non Unicode nel tipo di dati VARCHAR
Supponiamo di avere una tabella che registra il feedback dei clienti da un portale di e-shopping. A tale scopo, abbiamo una tabella SQL con la seguente query.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
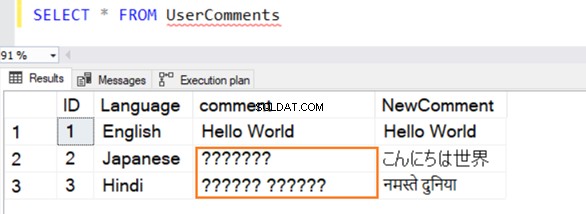
In questa tabella inseriamo diversi record di esempio in inglese, giapponese e hindi. Il tipo di dati per [Commento] è VARCHAR e [NuovoCommento] è NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
La query viene eseguita correttamente e fornisce le righe seguenti durante la selezione di un valore da essa. Per la riga 2 e 3, non riconosce i dati se non sono in inglese.
Tipi di dati VARCHAR e NVARCHAR:confronto delle prestazioni
Non dovremmo combinare l'uso dei tipi di dati VARCHAR e NVARCHAR nei predicati JOIN o WHERE. Invalida gli indici esistenti perché SQL Server richiede gli stessi tipi di dati su entrambi i lati di JOIN. SQL Server tenta di eseguire la conversione implicita utilizzando la funzione CONVERT_IMPLICIT() in caso di mancata corrispondenza.
SQL Server utilizza la precedenza del tipo di dati per determinare quale sia il tipo di dati di destinazione. NVARCHAR ha una precedenza maggiore rispetto al tipo di dati VARCHAR. Pertanto, durante la conversione del tipo di dati, SQL Server converte i valori VARCHAR esistenti in NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Ora eseguiamo due istruzioni SELECT che recuperano i record in base ai loro tipi di dati.
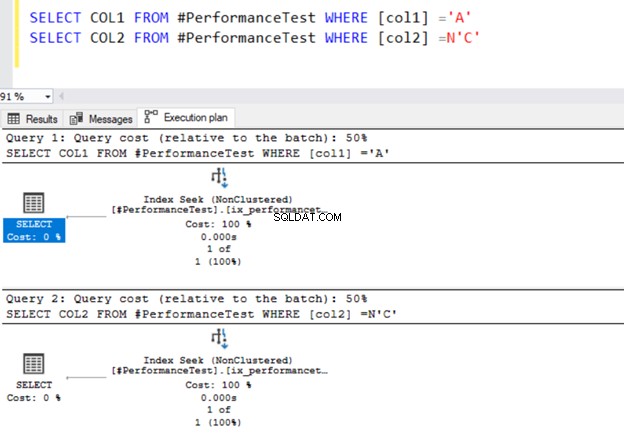
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Entrambe le query utilizzano l'operatore di ricerca dell'indice e gli indici che abbiamo definito in precedenza.
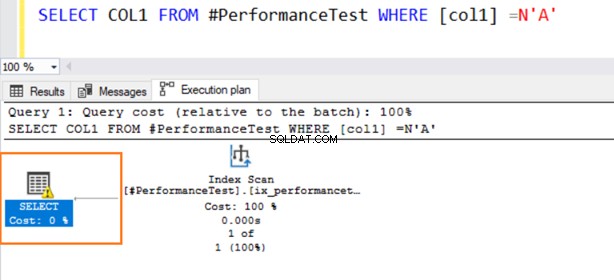
Ora, cambiamo i valori del tipo di dati per il confronto nel predicato WHERE. La colonna 1 ha un tipo di dati VARCHAR, ma specifichiamo N'A' per inserirlo come tipo di dati NVARCHAR.
Allo stesso modo, col2 è il tipo di dati NVARCHAR e specifichiamo il valore "C" che si riferisce al tipo di dati VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'Nel piano di esecuzione effettivo della query, ottieni una scansione dell'indice e l'istruzione SELECT ha un simbolo di avviso.
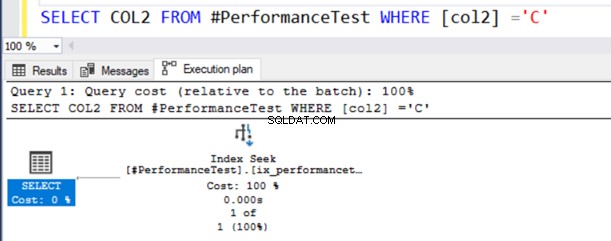
Questa query funziona correttamente perché il tipo di dati NVARCHAR() può avere valori sia Unicode che non Unicode.
Ora, la seconda query utilizza una scansione dell'indice ed emette un simbolo di avviso sull'operatore SELECT.
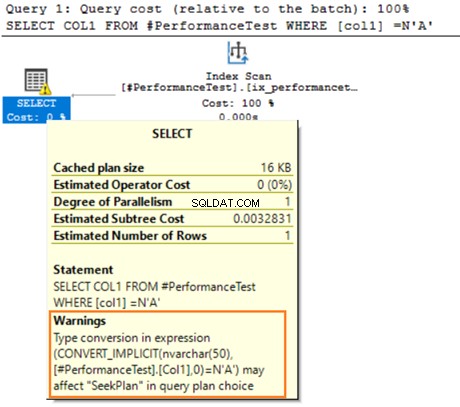
Passa il mouse sopra l'istruzione SELECT che emette un avviso sulla conversione implicita. SQL Server non ha potuto utilizzare correttamente l'indice esistente. È dovuto ai diversi algoritmi di ordinamento dei dati per i tipi di dati VARCHAR e NVARCHAR.
Se la tabella contiene milioni di righe, SQL Server deve eseguire ulteriori operazioni e convertire i dati utilizzando la conversione dei dati in modo implicito. Potrebbe influire negativamente sulle prestazioni della query. Pertanto, dovresti evitare di combinare e abbinare questi tipi di dati nell'ottimizzazione delle query.
Conclusione
È necessario rivedere i requisiti dei dati durante la progettazione delle tabelle del database e del relativo tipo di dati delle colonne in modo appropriato. Di solito, il tipo di dati VARCHAR gestisce la maggior parte dei tuoi requisiti di dati. Tuttavia, se è necessario archiviare in una colonna i tipi di dati Unicode e non Unicode, è possibile considerare l'utilizzo di NVARCHAR. Tuttavia, prima di prendere la decisione finale, dovresti esaminare le sue implicazioni sulle prestazioni e le dimensioni dello spazio di archiviazione.