Introduzione
In questo articolo parleremo dell'utilizzo di nvarchar tipo di dati. Esploreremo come SQL Server archivia questo tipo di dati sul disco e come viene elaborato nella RAM. Esamineremo anche come le dimensioni di nvarchar possono influire sulle prestazioni.
Dimensioni effettive dei dati:nchar vs nvarchar
Usiamo nvarchar quando le dimensioni delle voci di dati delle colonne probabilmente varieranno considerevolmente. La dimensione di archiviazione (in byte) è il doppio della lunghezza effettiva dei dati inseriti + 2 byte. Questo ci consente di risparmiare spazio su disco rispetto all'utilizzo di nchar tipo di dati. Consideriamo il seguente esempio. Stiamo creando due tabelle. Una tabella contiene la colonna nvarchar, un'altra tabella contiene le colonne nchar. La dimensione della colonna è di 2000 caratteri (4000 byte).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
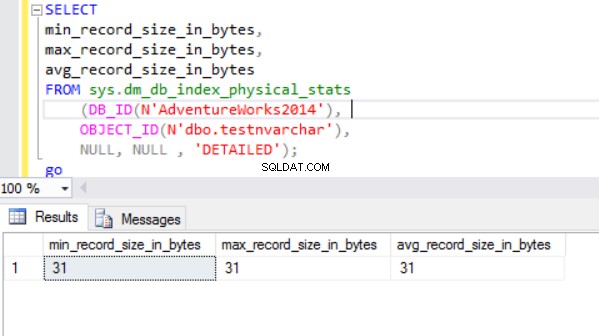
La dimensione effettiva della riga è:
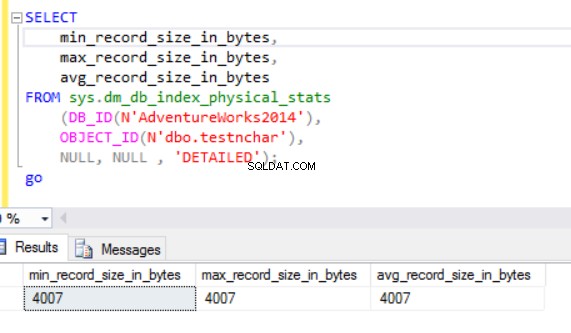
Come possiamo vedere, la dimensione effettiva della riga del tipo di dati nvarchar è molto più piccola del tipo di dati nchar. Nel caso del tipo di dati nchar, utilizziamo ~4000 byte per memorizzare una stringa di caratteri di 10 simboli. Usiamo ~20 byte per memorizzare la stessa stringa di caratteri nel caso del tipo di dati nvarchar.
Il motore di SQL Server elabora i dati nella RAM (pool di buffer). Che dire della dimensione della riga nella memoria?
Dimensioni effettive dei dati:HDD vs RAM
Eseguiamo la seguente query:
SELECT col1 FROM dbo.testnchar;

Non c'è differenza tra l'utilizzo del disco e della RAM nel caso della stringa di caratteri di lunghezza fissa.
SELECT col1 FROM dbo.testnvarchar;

Possiamo vedere che il motore di SQL Server ha richiesto la memoria solo per la metà della dimensione della riga dichiarata (2000 byte invece dei 20 byte effettivi) e diversi byte per ulteriori informazioni. Da un lato riduciamo l'utilizzo dello spazio su disco, ma dall'altro possiamo gonfiare la RAM richiesta. Questo è un effetto collaterale dell'uso dei tipi di dati di carattere variabili. Questo effetto collaterale può avere un forte impatto sulle risorse in alcuni casi.
FORMAT():RAM richiesta vs RAM utilizzata
Usiamo la funzione FORMAT, che restituisce un valore formattato con il formato specificato e le impostazioni cultura facoltative. Il valore restituito è nvarchar o nullo. La lunghezza del valore restituito è determinata dal formato . FORMAT(getdate(), 'yyyyMMdd','en-US') risulterà in '20170412'. Abbiamo bisogno di 16 byte per memorizzare questo risultato nella colonna del disco (il risultato sarà nvarchar(8)). Qual è la dimensione dei dati nella RAM per i dati particolari?
Eseguiamo la seguente query. Utilizziamo il seguente ambiente:
- AdventureWorks2014
- Edizione di sviluppo MS SQL 2016
- dbo.Customer (19'820'000 record) contiene i dati di Sales.Customer (19'820 record sono stati caricati 1000 volte)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Il piano di esecuzione della query è abbastanza semplice:

La prima operazione è "Scansione indice cluster" sulla tabella dbo.Customer. ~19.000.000 di record sono stati letti. La dimensione stimata dei dati è 435 Mb.
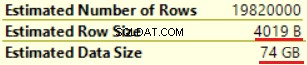
L'operazione successiva è "Compute Scalar" (calcolo della funzione FORMAT()). Il risultato è abbastanza inaspettato poiché formattiamo una stringa di caratteri di 16 byte. La dimensione della riga è aumentata notevolmente da 23 byte a 4019 byte. Lo stesso con la dimensione dei dati stimata:da 435 MB a 74 GB. Possiamo vedere che FORMAT() restituisce NVARCHAR(4000).
MS SQL Server 2016 ha la grande capacità di mostrare un'eccessiva concessione di memoria. Possiamo vedere l'avviso nell'ultima operazione (T-SQL SELECT INTO):
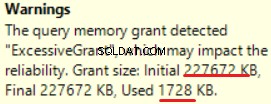
Questo è "sovraconcesso" della memoria:più del 90% della memoria concessa non viene utilizzato.
Le statistiche sul tempo di query sono:
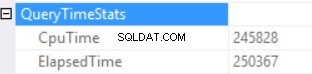
Il lungo tempo di esecuzione dipende da un'esecuzione di una funzione scalare non efficace e dall'effetto collaterale di una concessione di memoria eccessiva - Corrispondenza hash (join esterno destro). Abbiamo un effetto cumulativo di due diverse cause:esecuzione di più funzioni scalari e concessione di memoria eccessiva.
Il motore di SQL Server non può concedere più del 25% della memoria consentita per query. È possibile modificare questo importo nell'edizione aziendale di MS SQL Server utilizzando il regolatore delle risorse. La memoria concessa è composta da due parti:richiesta e aggiuntiva. La memoria richiesta viene utilizzata per le esigenze interne, per le operazioni di ordinamento e hash join. La memoria aggiuntiva si basa sulla dimensione dei dati stimata. Se sia la memoria richiesta che quella aggiuntiva superano il limite del 25%, il motore di SQL Server concede un altro 25% della memoria disponibile. Leggi il post sulla concessione della memoria di SQL Server per i dettagli.
Eseguiamo la stessa query senza la funzione FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
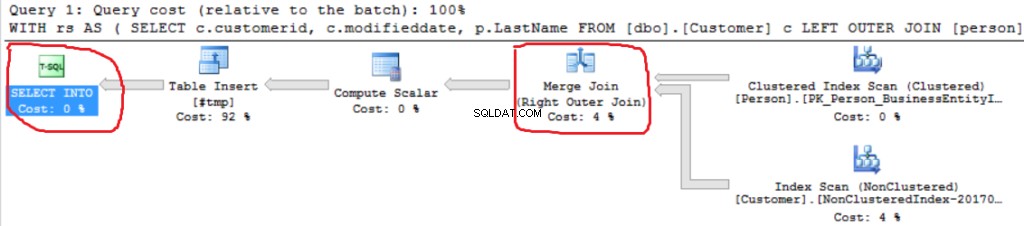
Possiamo vedere un'altra implementazione di Right Outer Join (Merge Join invece di Hash Join).
Le informazioni sulla concessione della memoria sono (se nessun ordinamento e l'hash join SQL Server non può concedere memoria):
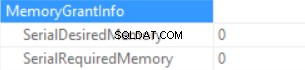
Le statistiche del tempo di query sono (il tempo è diminuito in modo prevedibile:nessuna esecuzione di funzioni scalari, la dimensione dei dati stimata è inferiore rispetto al campione precedente):

Quindi stiamo gonfiando la "memoria concessa" fino a 222 MB (e ne stiamo utilizzando meno di 2 MB) utilizzando la funzione FORMAT(). Il volume di dati nell'esempio è piccolo.
Query di esecuzione di lunga durata
Considera la vera query SQL da un ambiente di produzione. Questa query è stata eseguita durante un processo di caricamento batch (non uno scenario transazionale classico). Utilizziamo MS SQL Server avviato su Amazon Web Services (AWS, Amazon Relational Database Service). Le caratteristiche dell'istanza database sono 160 GB di RAM (non è possibile concedere più di ~30 GB di RAM per query) e 40 vCPU. La query SQL era quasi la stessa dell'esempio sopra (la differenza è nella quantità di tabelle e nella dimensione dei dati):CTE includeva il join tra 6 tabelle. La "tabella master" (una tabella nella clausola FROM) contiene ~175.000.000 di record e la dimensione dei dati è di 20 GB. Le tabelle di ricerca (tabella di destra nella clausola JOIN) sono piccole (rispetto alla tabella principale). La query SQL contiene due chiamate della funzione FORMAT() (due colonne della tabella "tabella master" sono il parametro di questa funzione).
La query di produzione ha il seguente aspetto:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
Di seguito la “foto” del piano di esecuzione (il piano di esecuzione è semplice:join sequenziali e ordinamento (parole chiave DISTINCT) in alto):

Esploriamo le informazioni in dettaglio.
La prima operazione è “Scansione tabella” (tutto corretto, nessuna sorpresa):

L'operazione di "calcolo scalare" aumenta notevolmente la dimensione della riga stimata e la dimensione della riga stimata (da 19 GB fino a 1,3 TB). Due chiamate della funzione FORMAT() hanno aggiunto circa 8000 byte alla dimensione stimata della riga (ma la dimensione effettiva dei dati è inferiore).

Una delle operazioni JOIN (Hash Match, Right Outer Join) utilizza colonne non univoche della tabella di destra. Non importa nel caso di pochi record. Questo non è il nostro caso. Di conseguenza, le dimensioni stimate dei dati stanno aumentando fino a ~2,4 TB.

C'è anche un avviso (RAM non sufficiente per elaborare questa operazione):
La query SQL contiene un'operazione "Distinct Sort" in alto, che assomiglia alla ciliegina sulla torta. Possiamo vedere lo stesso avviso lì.
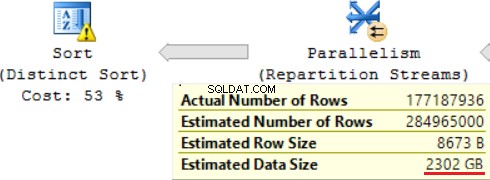
Il risultato dell'utilizzo di una funzione scalare è un tempo lungo per l'esecuzione della query:24 ore. Una delle cause di questo problema è una stima errata della dimensione dei dati richiesta in base alla "Dimensione stimata dei dati". Senza utilizzare la funzione FORMAT(), MS SQL Server esegue questa query in 2 ore.
Conclusione
Gli sviluppatori dovrebbero prestare attenzione quando utilizzano i tipi di dati nvarchar e varchar. La selezione di tipi di dati ridondanti per le colonne può comportare un aumento della memoria richiesta. Di conseguenza, la RAM verrà sprecata, le prestazioni del database saranno ridotte.