L'obiettivo di questo articolo sarà l'utilizzo delle JOIN. Inizieremo parlando un po' di come avverranno i JOIN e perché è necessario unire i dati. Quindi daremo un'occhiata ai tipi di JOIN che abbiamo a nostra disposizione e come usarli.
UNISCI DI BASE
I JOIN in TSQL vengono in genere eseguiti sulla riga FROM.
Prima di arrivare a qualsiasi altra cosa, la vera grande domanda diventa:"Perché dobbiamo fare JOIN e come eseguiremo effettivamente i nostri JOIN?"
A quanto pare, ogni database con cui lavoriamo avrà i suoi dati suddivisi in più tabelle. Ci sono molte ragioni diverse per questo:
- Mantenimento dell'integrità dei dati
- Risparmio di spazio memorizzato
- Modifica più rapida dei dati
- Rendere le query più flessibili
Pertanto, ogni database con cui lavorerai avrà bisogno che i dati siano uniti insieme affinché abbiano effettivamente un senso.
Ad esempio, hai tabelle separate per gli ordini e per i clienti. La domanda che diventa:"Come connettiamo effettivamente tutti i dati insieme?" Questo è esattamente ciò che faranno i JOIN.
COME FUNZIONANO I JOIN
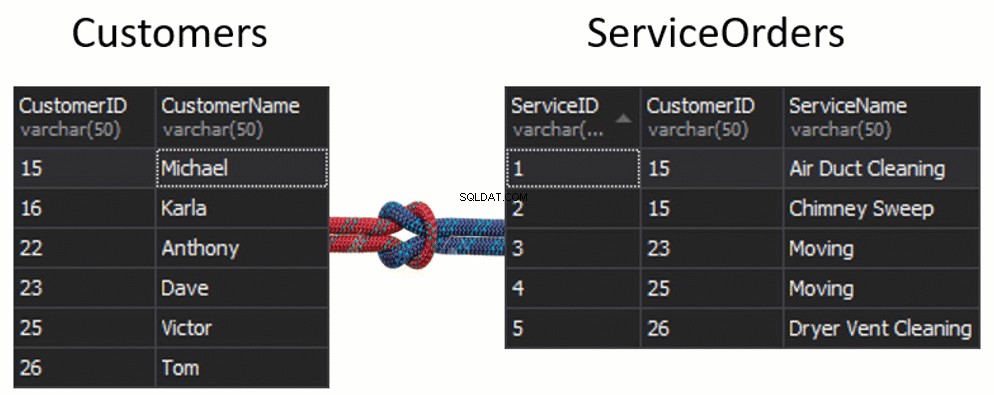
Immagina il caso in cui abbiamo due tavoli separati e quei tavoli verranno uniti creando una cucitura.
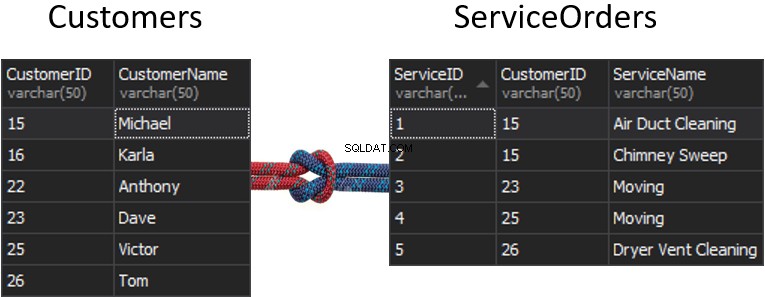
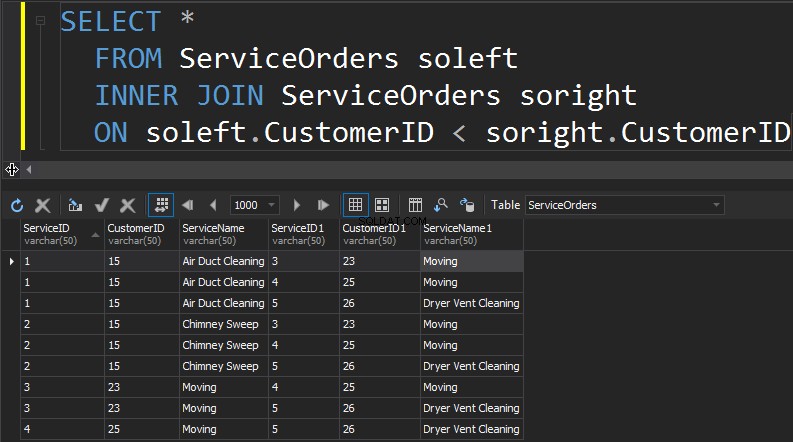
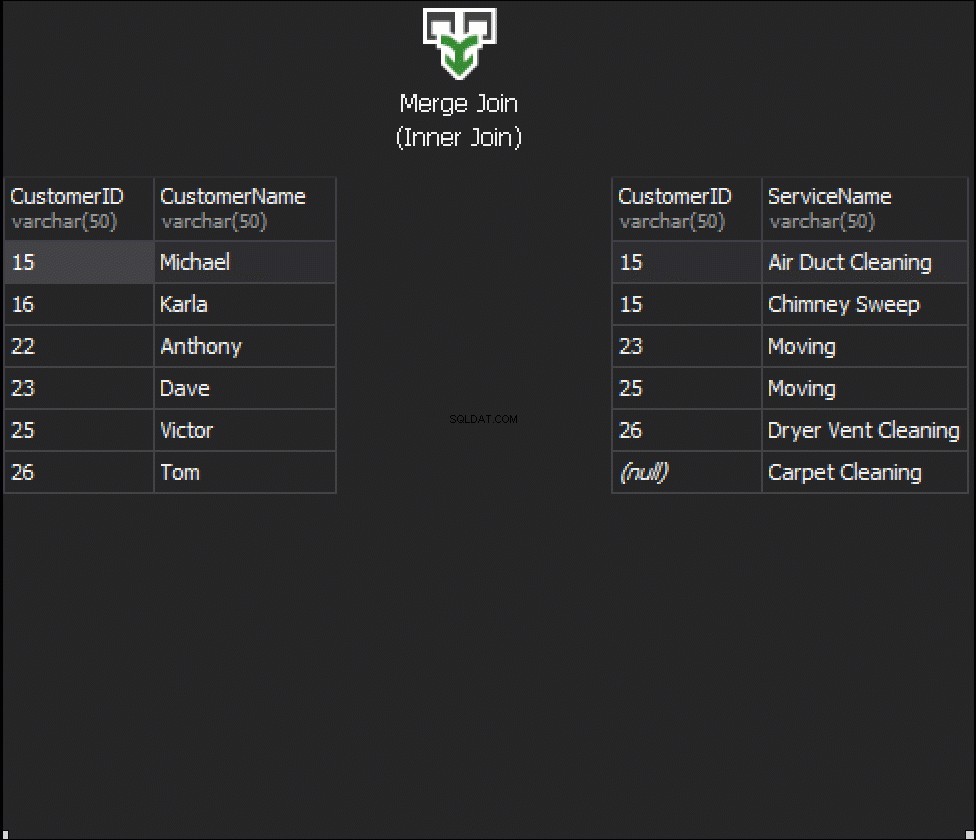
Cosa accadrà con la cucitura, se otteniamo una colonna da ogni tabella che verrà utilizzata per la corrispondenza e che determinerà quali righe verranno restituite o meno? Ad esempio, abbiamo Clienti a sinistra e ServiceOrders a destra. Se vogliamo ottenere tutti i clienti e i loro ordini, dobbiamo UNIRE questi due tavoli insieme. Per questo, dobbiamo scegliere una colonna che fungerà da cucitura e, ovviamente, la colonna che utilizzeremo è CustomerID.
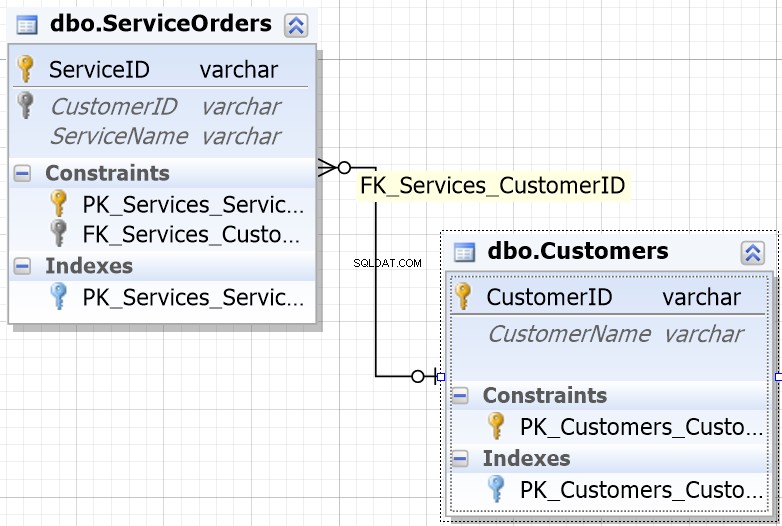
A proposito, il CustomerID è noto come Chiave primaria per la tabella di sinistra, che identifica univocamente ogni singola riga all'interno della tabella Clienti.
Nella tabella ServiceOrders abbiamo anche la colonna CustomerID, nota come Chiave esterna . Una chiave esterna è semplicemente una colonna progettata per puntare a un'altra tabella. Nel nostro caso, punta alla tabella Clienti. Pertanto, è così che riuniremo tutti quei dati fornendo quella cucitura.
In queste tabelle abbiamo i seguenti abbinamenti:2 ordini per 15 e 1 ordine per 23, 25 e 26. 16 e 22 sono esclusi.
Una cosa importante da notare qui è che possiamo UNIRE più tavoli . In effetti, è abbastanza comune UNIRE più tabelle insieme, in modo da ottenere qualsiasi forma di informazione. Se dai un'occhiata al database più comune, potresti dover UNIRE insieme quattro, cinque, sei e più tabelle solo per ottenere le informazioni che stai cercando. Avere un diagramma di database sarà utile.
Per aiutarti nella maggior parte degli ambienti di database, noterai che le colonne progettate per essere unite hanno lo stesso nome.
UNISCI SINTASSI
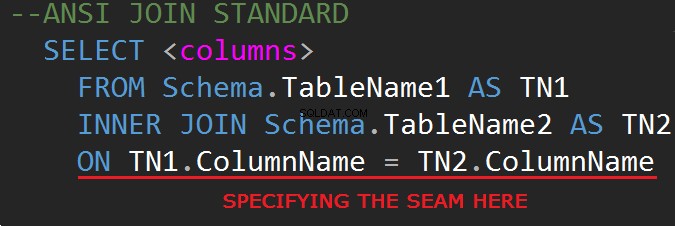
La terza revisione del linguaggio di query del database SQL (SQL-92) regola la sintassi JOIN:
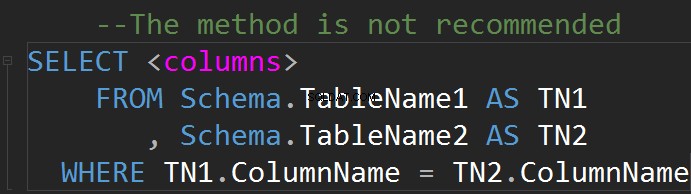
È possibile fare JOIN sulla linea WHERE:
Una relazione di solito ha una semplice interpretazione grafica sotto forma di tabella.
Migliori pratiche e convenzioni
- Nomi delle tabelle alias.
- Utilizza la denominazione in due parti per le colonne
- Inserisci ogni JOIN su una riga separata
- Posiziona le tabelle in un ordine logico
TIPI DI UNISCITI
SQL Server fornisce i seguenti tipi di JOIN:
- UNIONE INTERNA
- UNIONE ESTERNA
- ADERIRE AUTOMATICAMENTE
- CROSS UNISCITI
Per ulteriori informazioni sull'argomento, consulta questo articolo sui tipi di join in SQL Server e scopri com'è facile scrivere tali query con l'aiuto di SQL Complete.
UNIONE INTERNA
Il primo tipo di JOIN che potremmo voler eseguire è l'INNER JOIN. Di solito, gli autori fanno riferimento a questo tipo di JOIN di SQL Server come JOIN normale o semplice. Omettono semplicemente il prefisso INNER. Questo tipo di JOIN combina due tabelle insieme e restituisce solo le righe di entrambi i lati che corrispondono .
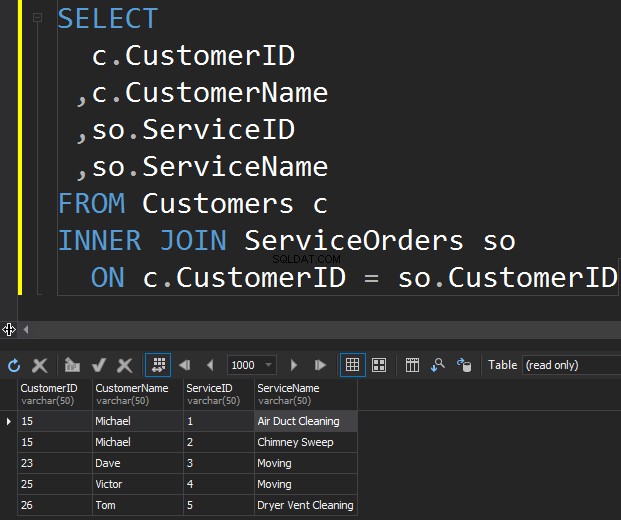
Non vediamo Klara e Anthony qui perché il loro CustomerID non corrisponde in entrambe le tabelle. Voglio anche evidenziare il fatto che l'operazione JOIN restituisce un cliente ogni volta che corrisponde all'ordine . Ci sono due ordini per Michael e un ordine per Dave, Victor e Tom ciascuno.
Riepilogo:
- INNER JOIN restituisce righe solo quando è presente almeno una riga in entrambe le tabelle che soddisfa la condizione JOIN.
- INNER JOIN elimina le righe che non corrispondono a una riga dell'altra tabella
UNIONE ESTERNA
I JOIN esterni sono diversi perché restituiscono righe da tabelle o viste anche se non corrispondono. Questo tipo di JOIN è utile se devi recuperare tutti i clienti che non hanno mai effettuato un ordine. O, ad esempio, se stai cercando un prodotto che non è mai stato ordinato.
Il modo in cui eseguiamo i nostri OUTER JOIN è indicando SINISTRA o DESTRA o COMPLETA.
Non ci sono differenze tra le seguenti clausole:
- UNISCI ESTERNO SINISTRO =UNISCITI SINISTRO
- UNIONE ESTERNA DESTRA =UNISCIZIONE DESTRA
- FULL OUTER JOIN =FULL JOIN
Tuttavia, consiglierei di scrivere la clausola completa perché rende il codice più leggibile.
Utilizzo di INIZIO ESTERNO SINISTRO
Non c'è differenza tra LEFT o RIGHT tranne il fatto che puntiamo semplicemente la tabella da cui vogliamo ottenere le righe extra. Nell'esempio seguente, abbiamo elencato i clienti e i loro ordini. Utilizziamo la SINISTRA per ottenere tutti i clienti che non hanno mai effettuato ordini. Chiediamo a SQL Server di procurarci righe extra dalla tabella di sinistra.
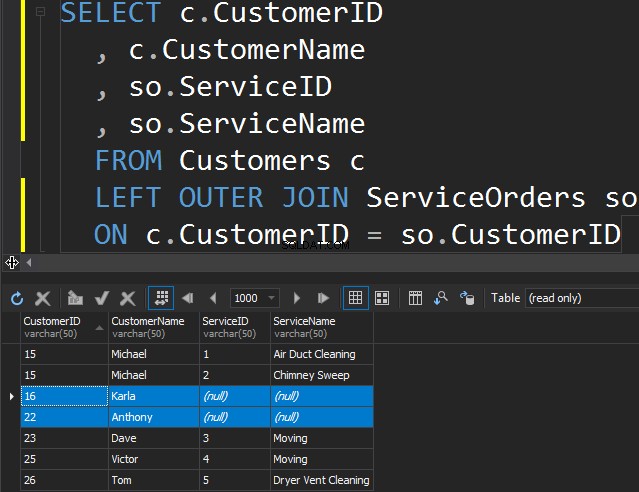
Nota che Karla e Anthony non hanno effettuato alcun ordine e, di conseguenza, otteniamo valori NULL per ServiceName e ServiceID. SQL Server non sa cosa inserire e inserisce NULL.
Utilizzo di RIGHT OUTER JOIN
Per ottenere il servizio meno popolare dalla tabella ServiceOrders, dobbiamo utilizzare la direzione GIUSTA.
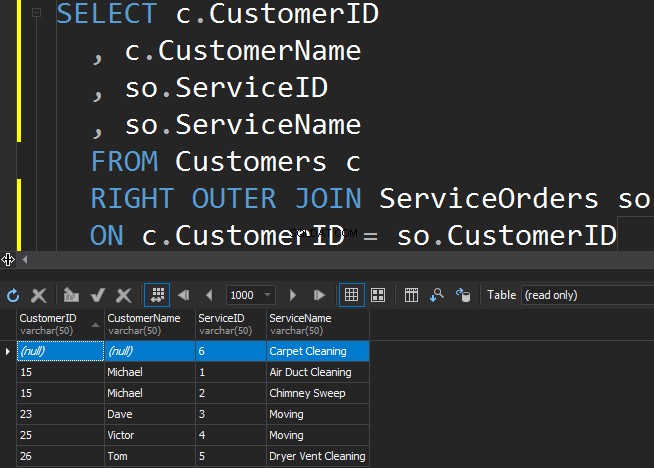
Vediamo che in questo caso SQL Server ha restituito righe extra dalla tabella di destra e il servizio di pulizia della moquette non è mai stato ordinato.
Utilizzo di FULL OUTER JOIN
Questo tipo di JOIN ti consente di ottenere le informazioni non corrispondenti includendo righe non corrispondenti da entrambe le tabelle.
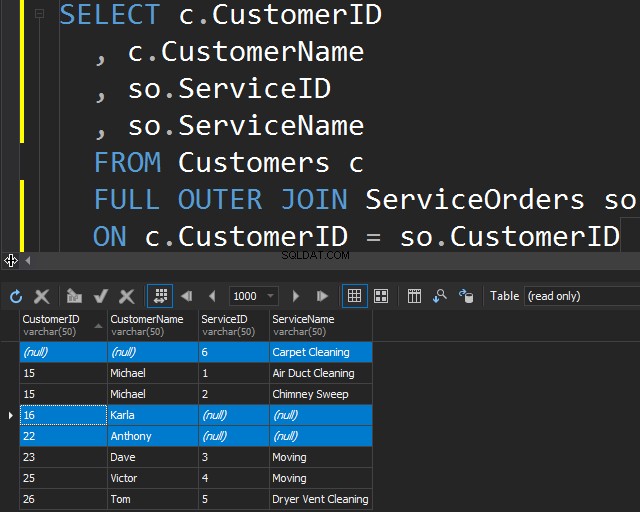
Questo può essere utile anche se devi eseguire una pulizia dei dati.
Riepilogo:
ISCRIZIONE ESTERNA COMPLETA
- Restituisce le righe di entrambe le tabelle anche se non corrispondono all'istruzione JOIN
SINISTRA o DESTRA
- Nessuna differenza se non nell'ordine delle tabelle nella clausola FROM
- Punti di direzione verso una tabella da cui recuperare le righe non corrispondenti
AUTO UNISCITI
Il prossimo tipo di JOIN che abbiamo è SELF JOIN. Questo è probabilmente il secondo tipo meno comune di JOIN che eseguirai mai. UN SELF JOIN è quando ti unisci a un tavolo su se stesso. In generale, questo è un segno di cattiva progettazione. Per utilizzare la stessa tabella due volte in una singola query, la tabella deve essere alias. L'alias aiuta il Query Processor a identificare se le colonne devono presentare i dati dal lato destro o sinistro. Inoltre, è necessario eliminare le file che marciano da sole. Questo viene in genere fatto con un join non equi.
Riepilogo:
- Unisce un tavolo a se stesso
- In genere un segno di scarsa progettazione e normalizzazione
- Le tabelle devono essere alias
- Necessità di filtrare le righe corrispondenti
UNIONE CROSS
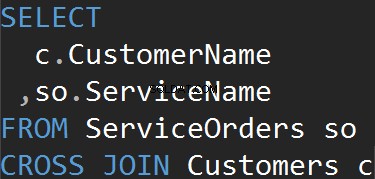
Questo tipo di JOIN non ha il ON dichiarazione. Ogni singola riga di ogni tabella corrisponderà. Questo è anche noto come prodotto cartesiano (nel caso in cui un CROSS JOIN non abbia una clausola WHERE). Difficilmente utilizzerai questo tipo di JOIN in scenari reali, tuttavia è un buon modo per generare dati di test.
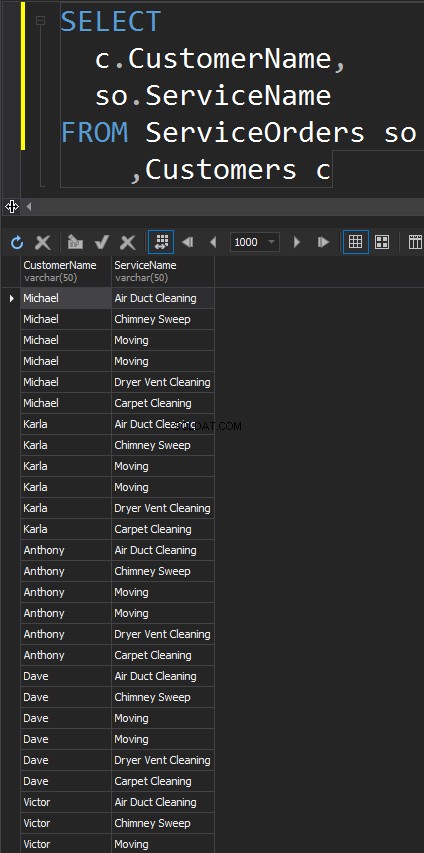
Il risultato è un set di dati, in cui il numero di righe nella tabella di sinistra viene moltiplicato per il numero di righe nella tabella di destra. Alla fine, vediamo che ogni singolo cliente corrisponde a ogni singolo servizio.
Otteniamo lo stesso risultato quando utilizziamo esplicitamente la clausola CROSS JOIN.
Riepilogo:
- Tutte le righe corrispondono a ciascuna tabella
- Nessuna dichiarazione ON
- Può essere utilizzato per generare dati di test
UNISCI ALGORITMI
Nella prima parte dell'articolo abbiamo discusso di logico JOIN operatori utilizzati da SQL Server durante l'analisi e l'associazione delle query. Sono:
- UNIONE INTERNA
- UNIONE ESTERNA
- CROSS UNISCITI
Gli operatori logici sono concettuali e differiscono da quelli fisici SI UNISCE. In caso contrario, i JOIN logici in realtà non si uniscono particolari colonne della tabella. Un singolo JOIN logico può corrispondere a molti JOIN fisici. SQL Server sostituisce i JOIN logici con i JOIN fisici durante l'ottimizzazione. SQL Server dispone dei seguenti operatori JOIN fisici:
- CICLO ANNIDATO
- UNISCI
- HASH
Un utente non scrive o utilizza questi tipi di JOINS. Fanno parte del motore di SQL Server e SQL Server li usa internamente per implementare JOIN logici. Quando esplori il piano di esecuzione, potresti notare che SQL Server sostituisce gli operatori JOIN logici con uno dei tre operatori fisici.
Unisciti al loop nidificato
Partiamo dall'operatore più semplice, che è Nested Loop. L'algoritmo confronta ogni singola riga di una tabella (tabella esterna) con ogni riga dell'altra tabella (tabella interna) alla ricerca di righe che soddisfano il predicato JOIN.
Il seguente pseudo-codice descrive l'algoritmo del ciclo di join nidificato interno:

Il seguente pseudocodice descrive l'algoritmo del ciclo di join nidificato esterno:
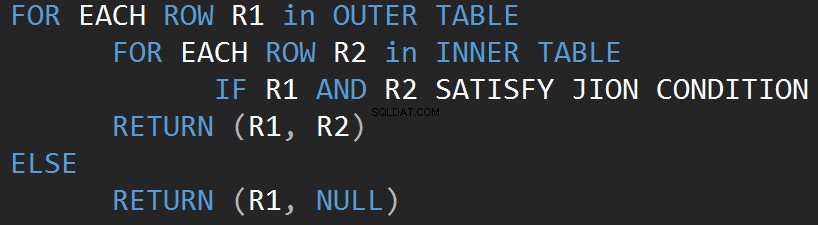
La dimensione dell'input influisce direttamente sul costo dell'algoritmo. L'input cresce, cresce anche il costo. Questo tipo di algoritmo JOIN è efficiente in caso di input ridotti. SQL Server stima un predicato JOIN per ogni riga in entrambi gli input.
Considera la seguente query come esempio, che ottiene i clienti e i loro ordini.
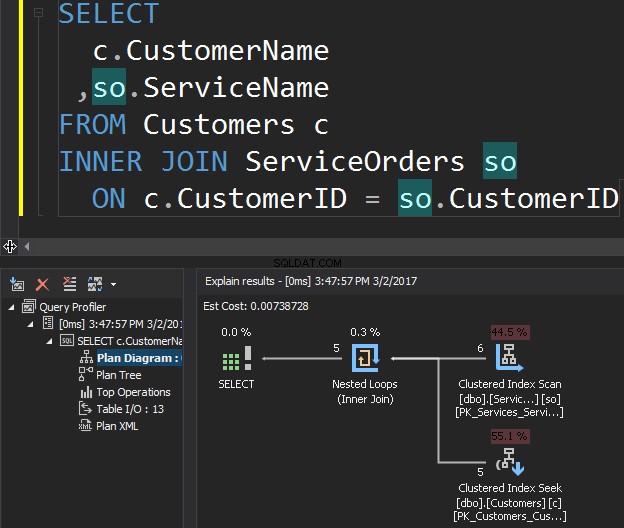
L'operatore Clustered Index Scan è l'input esterno e il Clustered Index Seek è l'input interno . L'operatore Nested Loop trova effettivamente la corrispondenza. L'operatore cerca ogni record nell'input esterno e trova le righe corrispondenti nell'input interno. SQL Server esegue l'operazione di analisi dell'indice cluster (input esterno) una sola volta per ottenere tutti i record pertinenti. La ricerca dell'indice cluster viene eseguita per ogni record dall'input esterno. Per confermare ciò, sposta il cursore sull'icona dell'operatore ed esamina il suggerimento.
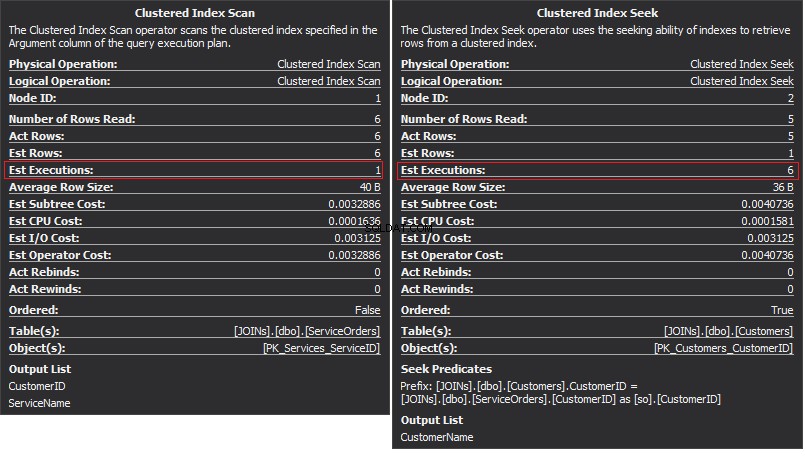
Parliamo della complessità. Supponiamo N è il numero di riga per l'output esterno. M è il numero totale di riga in SalesOrders tavolo. Pertanto, la complessità della query è O(NLogM) dove LogM è la complessità di ogni ricerca nell'input interiore. L'ottimizzatore selezionerà questo operatore ogni volta che l'input esterno è piccolo e l'input interno contiene un indice nella colonna che funge da cucitura. Pertanto, gli indici e le statistiche sono essenziali per questo tipo JOIN, altrimenti SQL Server potrebbe pensare accidentalmente che non ci siano così tante righe in uno degli input. È meglio eseguire una scansione della tabella piuttosto che eseguire la ricerca dell'indice 100.000 volte. Soprattutto quando la dimensione interna dell'input è superiore a 100.000.
Riepilogo:
Loop nidificati
- Complessità:O(NlogM)
- Applicato solitamente quando una tabella è piccola
- La tabella più grande contiene un indice che permette di cercarlo utilizzando la chiave di unione
Unisci Unisciti
Alcuni sviluppatori non comprendono completamente gli Hash e Merge JOIN e spesso li associano a query con prestazioni scadenti.
A differenza di Nested Loop che accetta qualsiasi predicato JOIN, il Merge Join richiede almeno un equi join. Inoltre, entrambi gli input devono essere ordinati sulle chiavi JOIN.
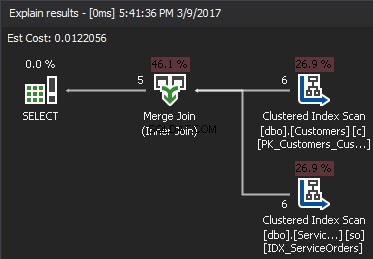
Lo pseudocodice per l'algoritmo MERGE JOIN:
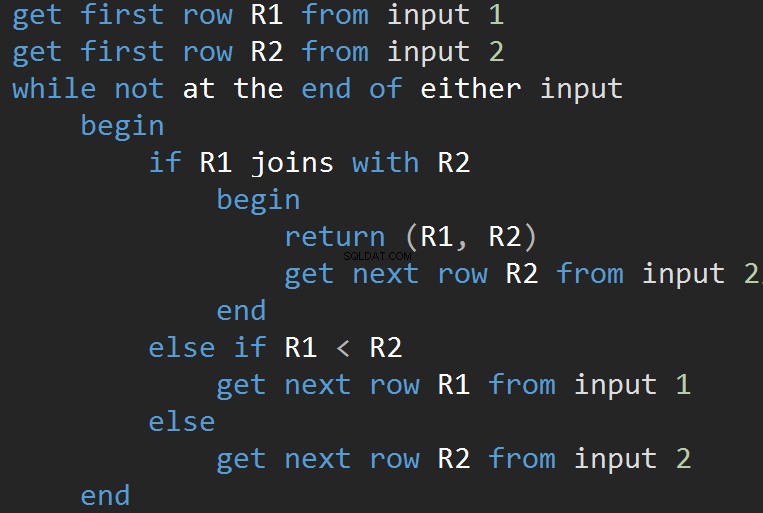
L'algoritmo confronta due input ordinati. Una riga alla volta. Nel caso in cui vi sia un'uguaglianza tra due righe, l'algoritmo restituisce unire le righe e continuare. In caso contrario, l'algoritmo scarta il minore dei due input e continua. A differenza del Nested Loop, il costo qui è proporzionale alla somma del numero di righe di input. In termini di complessità – O(N+M). Pertanto, questo tipo di JOIN è spesso migliore per input di grandi dimensioni.
L'animazione seguente mostra come l'algoritmo MERGE JOIN unisce effettivamente le righe della tabella.
Riepilogo
- Complessità:O(N+M)
- Entrambi gli input devono essere ordinati sulla chiave di unione
- Viene utilizzato un operatore di uguaglianza
- Ottimo per tavoli grandi
Unisciti all'hash
Hash Join è adatto per tabelle di grandi dimensioni senza indice utilizzabile. Nel primo passaggio:fase di creazione l'algoritmo crea un indice hash in memoria sull'input di sinistra. Il secondo passaggio è chiamato fase della sonda . L'algoritmo passa attraverso l'input sul lato destro e trova le corrispondenze utilizzando l'indice creato durante la fase di compilazione. A dire il vero, non è un buon segno quando l'ottimizzatore sceglie questo tipo di algoritmo JOIN.
Ci sono due concetti importanti alla base di questo tipo di JOIN:la funzione hash e la tabella hash.
Una funzione hash è qualsiasi funzione che può essere utilizzata per mappare dati di dimensione variabile a dati di dimensione fissa.
Una tabella hash è una struttura dati utilizzata per implementare un array associativo, una struttura che può mappare le chiavi sui valori. Una tabella hash utilizza una funzione hash per calcolare un indice in una matrice di bucket o slot, da cui è possibile trovare il valore desiderato.
In base alle statistiche disponibili, SQL Server sceglie l'input più piccolo come input di compilazione e lo usa per creare una tabella hash in memoria. Se la memoria non è sufficiente, SQL Server utilizza lo spazio su disco fisico in TempDB. Una volta creata la tabella hash, SQL Server ottiene i dati dall'input del probe (tabella più grande) e li confronta con la tabella hash utilizzando una funzione di corrispondenza hash. Di conseguenza, restituisce le righe corrispondenti.
Se osserviamo il piano di esecuzione, l'elemento in alto a destra è l'input di compilazione e l'elemento in basso a destra è l'input sonda . Nel caso in cui entrambi gli input siano estremamente grandi, il costo è troppo alto.
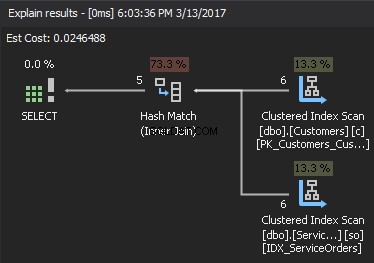
Per stimare la complessità, assumere quanto segue:
hc – complessità della creazione della tabella hash
hm – complessità della funzione di corrispondenza hash
N – tavolo più piccolo
M – tavolo più grande
J – aggiunta di complessità per il calcolo dinamico e la creazione della funzione hash
La complessità sarà:O(N*hc + M*hm + J)
L'ottimizzatore utilizza le statistiche per determinare la cardinalità del valore. Quindi crea dinamicamente una funzione hash che divide i dati in molti bucket con dimensioni uguali. Spesso è difficile stimare la complessità del processo di creazione della tabella hash, così come la complessità di ogni corrispondenza hash a causa della natura dinamica. Il piano di esecuzione può anche mostrare stime errate perché l'ottimizzatore esegue tutte queste operazioni dinamiche durante il tempo di esecuzione. In alcuni casi, il piano di esecuzione potrebbe mostrare che Nested Loop è più costoso di Hash Join, ma in realtà l'Hash Join viene eseguito più lentamente a causa della stima dei costi errata.
Riepilogo
- Complessità:O(N*hc +M*hm +J)
- Tipo di iscrizione all'ultima località
- Utilizza una tabella hash e una funzione di corrispondenza hash dinamica per abbinare le righe
Prodotti utili:
SQL Complete:scrivi, abbellisci, refactoring facilmente il tuo codice e aumenta la tua produttività.