PostgreSQL è noto come il database opensource più avanzato e ti aiuta a gestire i tuoi dati, non importa quanto grande, piccolo o diverso sia il set di dati, quindi puoi usarlo per gestire o analizzare i tuoi big data e, naturalmente, ci sono diversi modi per renderlo possibile, ad esempio Apache Spark. In questo blog vedremo cos'è Apache Spark e come possiamo usarlo per lavorare con il nostro database PostgreSQL.
Per l'analisi dei big data, abbiamo due diversi tipi di analisi:
- Analisi batch:basata sui dati raccolti in un periodo di tempo.
- Analisi (stream) in tempo reale:basata su dati immediati per un risultato istantaneo.
Cos'è Apache Spark?
Apache Spark è un motore di analisi unificato per l'elaborazione dei dati su larga scala che può funzionare sia su analisi batch che in tempo reale in modo più semplice e veloce.
Fornisce API di alto livello in Java, Scala, Python e R e un motore ottimizzato che supporta grafici di esecuzione generali.
 Apache Spark Components
Apache Spark Components Librerie Apache Spark
Apache Spark include diverse librerie:
- Spark SQL:è un modulo per lavorare con dati strutturati utilizzando SQL o un'API DataFrame. Fornisce un modo comune per accedere a una varietà di origini dati, tra cui Hive, Avro, Parquet, ORC, JSON e JDBC. Puoi anche unire i dati attraverso queste origini.
- Spark Streaming:semplifica la creazione di applicazioni di streaming scalabili e tolleranti agli errori utilizzando un'API integrata nel linguaggio per l'elaborazione in streaming, consentendoti di scrivere lavori in streaming nello stesso modo in cui scrivi lavori in batch. Supporta Java, Scala e Python. Spark Streaming recupera immediatamente sia il lavoro perso che lo stato dell'operatore, senza alcun codice aggiuntivo da parte tua. Ti consente di riutilizzare lo stesso codice per l'elaborazione batch, unire flussi rispetto a dati storici o eseguire query ad hoc sullo stato del flusso.
- MLib (Machine Learning):è una libreria scalabile di machine learning. MLlib contiene algoritmi di alta qualità che sfruttano l'iterazione e possono produrre risultati migliori rispetto alle approssimazioni a un passaggio talvolta utilizzate su MapReduce.
- GraphX:è un'API per grafici e calcolo parallelo. GraphX unifica ETL, analisi esplorativa e calcolo iterativo di grafi all'interno di un unico sistema. Puoi visualizzare gli stessi dati sia dei grafici che delle raccolte, trasformare e unire grafici con RDD in modo efficiente e scrivere algoritmi di grafici iterativi personalizzati utilizzando l'API Pregel.
Vantaggi di Apache Spark
Secondo la documentazione ufficiale, alcuni vantaggi di Apache Spark sono:
- Velocità:esegui carichi di lavoro 100 volte più veloci. Apache Spark raggiunge prestazioni elevate sia per batch che per streaming di dati, utilizzando uno scheduler DAG (Direct Acyclic Graph) all'avanguardia, un ottimizzatore di query e un motore di esecuzione fisico.
- Facilità d'uso:scrivi rapidamente applicazioni in Java, Scala, Python, R e SQL. Spark offre oltre 80 operatori di alto livello che semplificano la creazione di app parallele. Puoi usarlo in modo interattivo dalle shell Scala, Python, R e SQL.
- Generalità:combina SQL, streaming e analisi complesse. Spark alimenta uno stack di librerie tra cui SQL e DataFrames, MLlib per l'apprendimento automatico, GraphX e Spark Streaming. Puoi combinare queste librerie senza problemi nella stessa applicazione.
- Funziona ovunque:Spark funziona su Hadoop, Apache Mesos, Kubernetes, standalone o nel cloud. Può accedere a diverse fonti di dati. Puoi eseguire Spark usando la sua modalità cluster standalone, su EC2, su Hadoop YARN, su Mesos o su Kubernetes. Accedi ai dati in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive e centinaia di altre origini dati.
Ora, vediamo come possiamo integrarlo con il nostro database PostgreSQL.
Come utilizzare Apache Spark con PostgreSQL
Assumiamo che tu abbia il tuo cluster PostgreSQL attivo e funzionante. Per questa attività, utilizzeremo un server PostgreSQL 11 in esecuzione su CentOS7.
Innanzitutto, creiamo il nostro database di test sul nostro server PostgreSQL:
postgres=# CREATE DATABASE testing;
CREATE DATABASE
postgres=# \c testing
You are now connected to database "testing" as user "postgres".Ora creeremo una tabella chiamata t1:
testing=# CREATE TABLE t1 (id int, name text);
CREATE TABLEE inserisci alcuni dati lì:
testing=# INSERT INTO t1 VALUES (1,'name1');
INSERT 0 1
testing=# INSERT INTO t1 VALUES (2,'name2');
INSERT 0 1Controlla i dati creati:
testing=# SELECT * FROM t1;
id | name
----+-------
1 | name1
2 | name2
(2 rows)Per connettere Apache Spark al nostro database PostgreSQL, utilizzeremo un connettore JDBC. Puoi scaricarlo da qui.
$ wget https://jdbc.postgresql.org/download/postgresql-42.2.6.jarOra installiamo Apache Spark. Per questo, dobbiamo scaricare i pacchetti spark da qui.
$ wget https://us.mirrors.quenda.co/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
$ tar zxvf spark-2.4.3-bin-hadoop2.7.tgz
$ cd spark-2.4.3-bin-hadoop2.7/Per eseguire la shell Spark avremo bisogno di JAVA installato sul nostro server:
$ yum install javaQuindi ora possiamo eseguire la nostra Spark Shell:
$ ./bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at https://ApacheSpark1:4040
Spark context available as 'sc' (master = local[*], app id = local-1563907528854).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
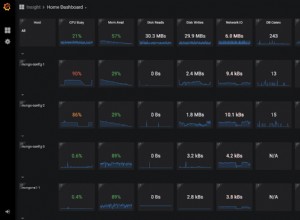
scala>Possiamo accedere alla nostra interfaccia utente Web del contesto Spark disponibile nella porta 4040 sul nostro server:
 interfaccia utente di Apache Spark
interfaccia utente di Apache Spark Nella shell Spark, dobbiamo aggiungere il driver JDBC PostgreSQL:
scala> :require /path/to/postgresql-42.2.6.jar
Added '/path/to/postgresql-42.2.6.jar' to classpath.
scala> import java.util.Properties
import java.util.PropertiesE aggiungi le informazioni JDBC che saranno utilizzate da Spark:
scala> val url = "jdbc:postgresql://localhost:5432/testing"
url: String = jdbc:postgresql://localhost:5432/testing
scala> val connectionProperties = new Properties()
connectionProperties: java.util.Properties = {}
scala> connectionProperties.setProperty("Driver", "org.postgresql.Driver")
res6: Object = nullOra possiamo eseguire query SQL. Innanzitutto, definiamo query1 come SELECT * FROM t1, la nostra tabella di test.
scala> val query1 = "(SELECT * FROM t1) as q1"
query1: String = (SELECT * FROM t1) as q1E crea il DataFrame:
scala> val query1df = spark.read.jdbc(url, query1, connectionProperties)
query1df: org.apache.spark.sql.DataFrame = [id: int, name: string]
Quindi ora possiamo eseguire un'azione su questo DataFrame:
scala> query1df.show()
+---+-----+
| id| name|
+---+-----+
| 1|name1|
| 2|name2|
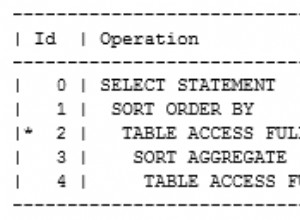
+---+-----+scala> query1df.explain
== Physical Plan ==
*(1) Scan JDBCRelation((SELECT * FROM t1) as q1) [numPartitions=1] [id#19,name#20] PushedFilters: [], ReadSchema: struct<id:int,name:string>Possiamo aggiungere più valori ed eseguirlo di nuovo solo per confermare che sta restituendo i valori correnti.
PostgreSQL
testing=# INSERT INTO t1 VALUES (10,'name10'), (11,'name11'), (12,'name12'), (13,'name13'), (14,'name14'), (15,'name15');
INSERT 0 6
testing=# SELECT * FROM t1;
id | name
----+--------
1 | name1
2 | name2
10 | name10
11 | name11
12 | name12
13 | name13
14 | name14
15 | name15
(8 rows)Scintilla
scala> query1df.show()
+---+------+
| id| name|
+---+------+
| 1| name1|
| 2| name2|
| 10|name10|
| 11|name11|
| 12|name12|
| 13|name13|
| 14|name14|
| 15|name15|
+---+------+Nel nostro esempio, mostriamo solo come funziona Apache Spark con il nostro database PostgreSQL, non come gestisce le nostre informazioni sui Big Data.
Conclusione
Al giorno d'oggi, è abbastanza comune avere la sfida di gestire i big data in un'azienda e, come abbiamo potuto vedere, possiamo utilizzare Apache Spark per affrontarla e sfruttare tutte le funzionalità che abbiamo menzionato in precedenza. I big data sono un mondo enorme, quindi puoi controllare la documentazione ufficiale per ulteriori informazioni sull'utilizzo di Apache Spark e PostgreSQL e adattarla alle tue esigenze.