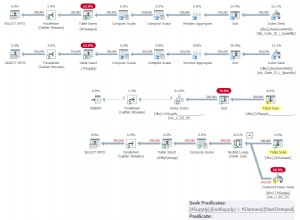
La difficoltà speciale consiste nel non perdere gli intervalli di tempo nell'intervallo di tempo esterno.
Supponendo che la riga successiva per un dato id ha sempre lo stato opposto.
Utilizzando il nome della colonna ts invece di recordTime :
WITH span AS (
SELECT '2014-03-01 13:00'::timestamp AS s_from -- start of time range
, '2014-03-01 14:00'::timestamp AS s_to -- end of time range
)
, cte AS (
SELECT id, ts, status, s_to
, lead(ts, 1, s_from) OVER w AS span_start
, first_value(ts) OVER w AS last_ts
FROM span s
JOIN tbl t ON t.ts BETWEEN s.s_from AND s.s_to
WINDOW w AS (PARTITION BY id ORDER BY ts DESC)
)
SELECT id, sum(time_disconnected)::text AS total_disconnected
FROM (
SELECT id, ts - span_start AS time_disconnected
FROM cte
WHERE status = 'Connected'
UNION ALL
SELECT id, s_to - ts
FROM cte
WHERE status = 'Disconnected'
AND ts = last_ts
) sub
GROUP BY 1
ORDER BY 1;
Restituisce gli intervalli come richiesto.
Gli ID senza voci nell'intervallo di tempo selezionato non vengono visualizzati. Dovresti interrogarli in aggiunta.
SQL Fiddle.
Nota:ho lanciato il risultato total_disconnected a text nel violino, perché il tipo interval viene visualizzato in un formato terribile.
Aggiungi ID senza inserimento nell'intervallo di tempo selezionato
Aggiungi alla query di cui sopra (prima del ORDER BY 1 finale ):
...
UNION ALL
SELECT id, total_disconnected
FROM (
SELECT DISTINCT ON (id)
t.id, t.status, (s.s_to - s.s_from)::text AS total_disconnected
FROM span s
JOIN tbl t ON t.ts < s.s_from -- only from before time range
LEFT JOIN cte c USING (id)
WHERE c.id IS NULL -- not represented in selected time frame
ORDER BY t.id, t.ts DESC -- only the latest entry
) sub
WHERE status = 'Disconnected' -- only if disconnected
ORDER BY 1;
Ora, solo ID senza voci in o prima l'intervallo di tempo selezionato non viene visualizzato.