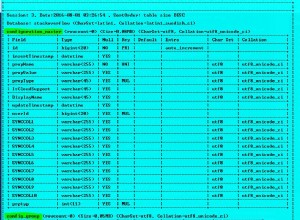
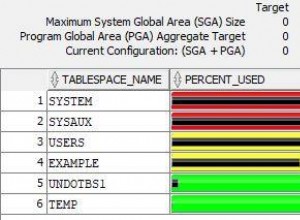
non sono sicuro che esista una soluzione con la gestione automatica delle transazioni concatenate/multilivello che funzioni in modo affidabile (o non richieda molte risorse lato database)
bene potresti combinare entrambi i passaggi in uno:
- letto dalla prima tabella A
- usa il processore per aggiornare la tabella A
- usa il processore per leggere dalla tabella B
- usa writer per aggiornare la tabella B
le prestazioni ne risentiranno molto, perché la lettura sulla tabella B sarà una singola lettura rispetto al cursore basato sulla tabella a
andrei con una strategia di compensazione come questa
- Le tabelle (opzionali) in uso sono tabelle temporanee e non vere e proprie tabelle di "produzione", facilita il lavoro di compensazione con il disaccoppiamento dei datastore dalla produzione
- un il passaggio 1 non riuscito attiva un altro passaggio o un altro lavoro/script
- questo passaggio/lavoro/script viene eliminato se necessario (righe o tabella completa)