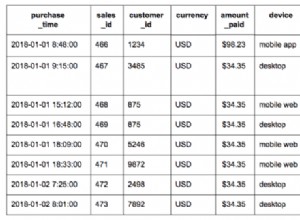
Se desideri modificare (eliminare i record) l'effettiva origine dei dati, ad esempio le tabelle in Postgres, Spark non sarebbe un ottimo modo. Puoi utilizzare il client jdbc direttamente per ottenere lo stesso.
Se vuoi farlo comunque (in modo distribuito sulla base di alcuni indizi che stai calcolando come parte di dataframe); puoi avere lo stesso codice client jdbc scritto in corrispondenza di dataframe che hanno informazioni logiche/trigger per l'eliminazione di record e che possiamo eseguire su più worker parallelamente.