Assumendo id non solo UNIQUE - come imposto dal tuo UNIQUE INDEX - ma anche NOT NULL . (Manca nella definizione della tua tabella.)
SELECT meta_split.key, meta_split.value, count(*)
FROM voc_cc348779bdc84f8aab483f662a798a6a v
CROSS JOIN LATERAL jsonb_each(v.meta) AS meta_split
GROUP BY meta_split.key, meta_split.value;
Equivalente più breve:
SELECT meta_split.key, meta_split.value, count(*)
FROM voc_cc348779bdc84f8aab483f662a798a6a v, jsonb_each(v.meta) AS meta_split
GROUP BY 1, 2;
Il LEFT [OUTER] JOIN era rumore perché il seguente test WHERE meta_split.value IS NOT NULL forza un INNER JOIN comunque. Usando CROSS JOIN invece.
Inoltre, poiché jsonb non consente comunque chiavi duplicate sullo stesso livello (che significa lo stesso id può apparire solo una volta per (key, value) ), DISTINCT è solo un rumore costoso. count(v.id) fa lo stesso a buon mercato. E count(*) è equivalente e, tuttavia, più economico, assumendo id è NOT NULL come indicato in alto.
count(*) ha un'implementazione separata
ed è leggermente più veloce di count(<value>) . È leggermente diverso da count(v.*) . Conta tutte le righe, qualunque cosa accada. Mentre l'altro modulo non conta NULL valori.
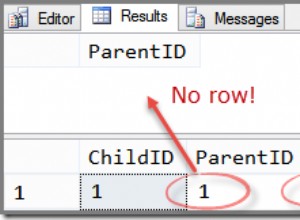
Cioè, purché id non può essere NULL - come indicato in alto. id dovrebbe essere davvero la PRIMARY KEY , che è comunque implementato internamente con un indice B-tree univoco e tutte le colonne - solo id qui - sono NOT NULL implicitamente. O almeno NOT NULL . Un UNIQUE INDEX non si qualifica completamente come sostituzione, consente comunque NULL valori che non sono considerati uguali e sono consentiti più volte. Vedi:
A parte questo, gli indici non servono qui, poiché tutte le righe devono comunque essere lette. Quindi questo non sarà mai molto economico. Ma 62.000 righe non è un numero di righe paralizzante in alcun modo, a meno che tu non abbia un numero enorme di chiavi nel jsonb colonna.
Le restanti opzioni per velocizzarlo:
-
Normalizza il tuo design. L'annullamento dell'annidamento dei documenti JSON non è gratuito.
-
Mantieni una visione materializzata. Fattibilità e costi dipendono fortemente dai tuoi schemi di scrittura.
È qui che gli indici possono giocare di nuovo un ruolo ...