NON usa indici ad eccezione della chiave numerica singola univoca.
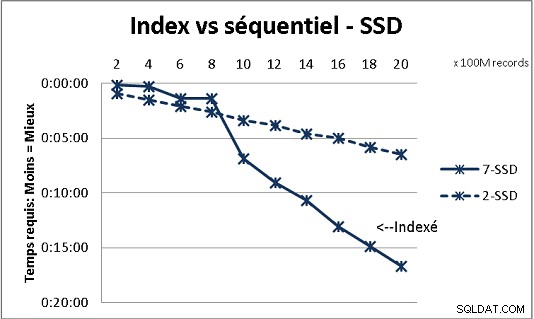
Ciò non si adatta a tutta la teoria DB che abbiamo ricevuto, ma i test con carichi pesanti di dati lo dimostrano. Ecco il risultato di 100 milioni di carichi alla volta per raggiungere 2 miliardi di righe in una tabella e ogni volta una serie di varie query sulla tabella risultante. Prima grafica con NAS 10 gigabit (150MB/s), seconda con 4 SSD in RAID 0 (R/W @ 2GB/s).
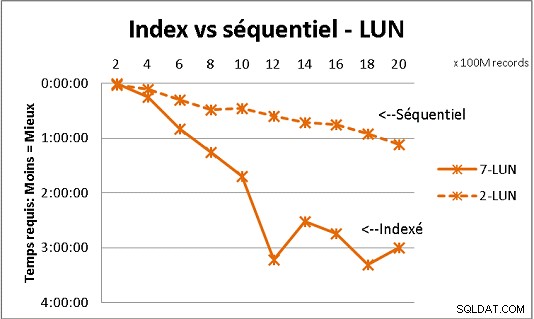
Se hai più di 200 milioni di righe in una tabella su dischi normali, è più veloce se dimentichi gli indici. Sugli SSD, il limite è di 1 miliardo.
L'ho fatto anche con le partizioni per risultati migliori, ma con PG9.2 è difficile trarne vantaggio se si utilizzano stored procedure. Devi anche occuparti di scrivere/leggere solo su 1 partizione alla volta. Tuttavia, le partizioni sono la strada da percorrere per mantenere i tuoi tavoli al di sotto del muro di 1 miliardo di righe. Aiuta anche molto per multiprocessare i tuoi carichi. Con SSD, un singolo processo mi consente di inserire (copiare) 18.000 righe/s (con alcuni lavori di elaborazione inclusi). Con il multiprocessing su 6 CPU, cresce fino a 80.000 righe/s.
Osserva l'utilizzo di CPU e IO durante il test per ottimizzare entrambi.