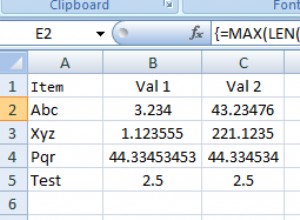
Un "seleziona all'interno di una selezione" è più comunemente chiamato "sottoselezione" o "sottoquery" Nel tuo caso particolare si tratta di una sottoquery correlata . LATERAL joins (nuovo in postgres 9.3) può sostituire ampiamente le sottoquery correlate con soluzioni più flessibili:
Penso che non ti serva neanche qui.
Per il tuo primo caso questa query è probabilmente più veloce e semplice, però:
SELECT date, max(value) OVER (PARTITION BY grp) AS value
FROM (
SELECT *, count(value) OVER (ORDER BY date) AS grp
FROM test_fill_null
) sub;
count() conta solo valori non nulli, quindi grp viene incrementato con ogni value non nullo , formando così gruppi come desiderato. È banale scegliere quello uno value non nullo per grp nel SELECT esterno .
Per il tuo secondo caso , presumo che l'ordine iniziale delle righe sia determinato da (id1, id2, tms) come indicato da una delle tue domande.
SELECT id1, id2, tms
, count(step) OVER (ORDER BY id1, id2, tms) AS group_id
FROM (
SELECT *, CASE WHEN lag(tms, 1, '-infinity') OVER (PARTITION BY id1 ORDER BY id2, tms)
< tms - interval '5 min'
THEN true END AS step
FROM table0
) sub
ORDER BY id1, id2, tms;
Adattati al tuo ordine reale. Uno di questi potrebbe coprirlo:
PARTITION BY id1 ORDER BY id2 -- ignore tms
PARTITION BY id1 ORDER BY tms -- ignore id2
SQL Fiddle con un esempio esteso.
Correlati: