Due settimane fa sono state rivelate due gravi vulnerabilità di sicurezza (denominate in codice Meltdown e Spectre). I test iniziali hanno suggerito che l'impatto sulle prestazioni delle attenuazioni (aggiunte nel kernel) potrebbe arrivare fino al 30% circa per alcuni carichi di lavoro, a seconda della frequenza delle chiamate di sistema.
Quelle prime stime dovevano essere fatte rapidamente e quindi erano basate su quantità limitate di test. Inoltre, le correzioni interne al kernel si sono evolute e migliorate nel tempo e ora abbiamo anche retpoline che dovrebbe affrontare Spectre v2. Questo post presenta i dati di test più approfonditi, sperando di fornire stime più affidabili per i carichi di lavoro PostgreSQL tipici.
Rispetto alla valutazione iniziale delle correzioni di Meltdown che Simon ha pubblicato il 10 gennaio, i dati presentati in questo post sono più dettagliati ma in generale i risultati delle corrispondenze presentati in quel post.
Questo post è incentrato sui carichi di lavoro PostgreSQL e, sebbene possa essere utile per altri sistemi con velocità di commutazione syscall/contesto elevate, certamente non è in qualche modo universalmente applicabile. Se sei interessato a una spiegazione più generale delle vulnerabilità e della valutazione dell'impatto, Brendan Gregg ha pubblicato un eccellente articolo KPTI/KAISER Meltdown Initial Performance Regressions un paio di giorni fa. In realtà, potrebbe essere utile leggerlo prima e poi continuare con questo post.
Nota: Questo post non ha lo scopo di scoraggiarti dall'installare le correzioni, ma di darti un'idea di quale potrebbe essere l'impatto sulle prestazioni. Dovresti installare tutte le correzioni in modo che il tuo ambiente sia sicuro e utilizzare questo post per decidere se potrebbe essere necessario aggiornare l'hardware, ecc.
Quali test faremo?
Esamineremo due soliti tipi di carico di lavoro di base:OLTP (piccole transazioni semplici) e OLAP (query complesse che elaborano grandi quantità di dati). La maggior parte dei sistemi PostgreSQL può essere modellata come un mix di questi due tipi di carico di lavoro.
Per OLTP abbiamo utilizzato pgbench, un noto strumento di benchmarking fornito con PostgreSQL. Abbiamo testato entrambi in sola lettura (-S ) e lettura-scrittura (-N ) modalità, con tre diverse scale:inserimento in shared_buffers, in RAM e più grandi di RAM.
Per il caso OLAP, abbiamo utilizzato il benchmark dbt-3, che è abbastanza vicino a TPC-H, con due diverse dimensioni dei dati:10 GB che si adattano alla RAM e 50 GB che sono più grandi della RAM (considerando gli indici, ecc.).
Tutti i numeri presentati provengono da un server con 2x Xeon E5-2620v4, 64GB di RAM e Intel SSD 750 (400GB). Il sistema eseguiva Gentoo con kernel 4.15.3, compilato con GCC 7.3 (necessario per abilitare la retpoline completa aggiustare). Gli stessi test sono stati eseguiti anche su un sistema più vecchio/più piccolo con CPU i5-2500k, 8GB di RAM e 6x SSD Intel S3700 (in RAID-0). Ma il comportamento e le conclusioni sono praticamente gli stessi, quindi non presenteremo i dati qui.
Come al solito, su github sono disponibili script/risultati completi per entrambi i sistemi.
Questo post riguarda l'impatto sulle prestazioni della mitigazione, quindi non concentriamoci sui numeri assoluti e guardiamo invece alle prestazioni relative al sistema senza patch (senza le mitigazioni del kernel). Tutti i grafici nella sezione OLTP mostrano
(throughput with patches) / (throughput without patches)
Ci aspettiamo numeri compresi tra 0% e 100%, con valori più alti migliori (impatto minore delle mitigazioni), 100% significa "nessun impatto".
Nota: L'asse y parte dal 75%, per rendere più visibili le differenze.
OLTP/sola lettura
Per prima cosa, vediamo i risultati per pgbench di sola lettura, eseguito da questo comando
pgbench -n -c 16 -j 16 -S -T 1800 test
ed illustrato dal seguente grafico:
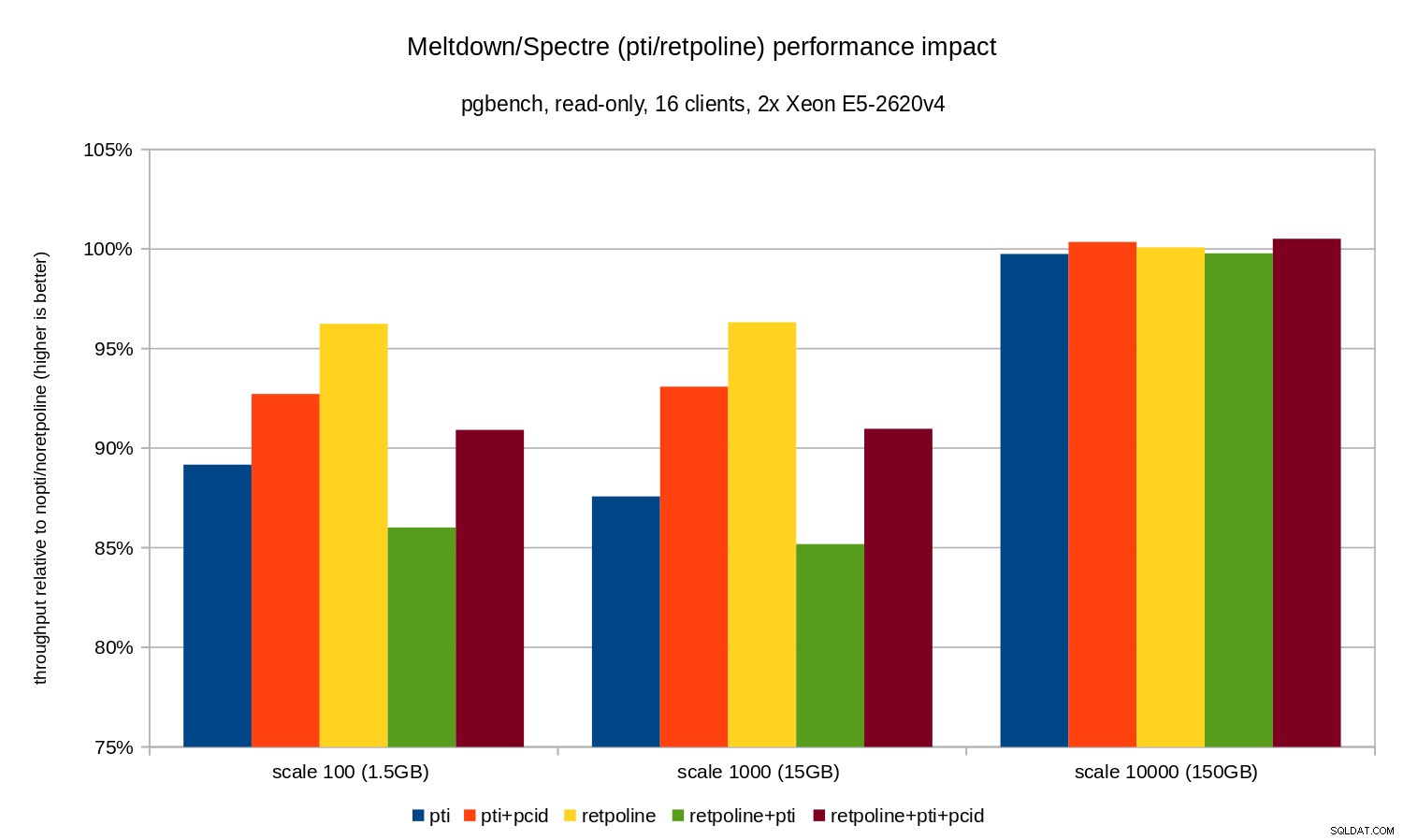
Come puoi vedere, l'impatto sulle prestazioni di pti per le bilance che si adattano alla memoria è di circa il 10-12% e quasi non misurabile quando il carico di lavoro diventa legato all'I/O. Inoltre, la regressione è significativamente ridotta (o scompare del tutto) quando pcid è abilitato. Ciò è coerente con l'affermazione secondo cui PCID è ora una funzionalità critica in termini di prestazioni/sicurezza su x86. L'impatto di retpoline è molto più piccolo – meno del 4% nel peggiore dei casi, che potrebbe essere facilmente dovuto al rumore.
OLTP/lettura-scrittura
I test di lettura-scrittura sono stati eseguiti da un pgbench comando simile a questo:
pgbench -n -c 16 -j 16 -N -T 3600 test
La durata era abbastanza lunga da coprire più checkpoint e -N è stato utilizzato per eliminare la contesa di blocco sulle righe nella tabella di diramazione (minuscola). La performance relativa è illustrata da questo grafico:
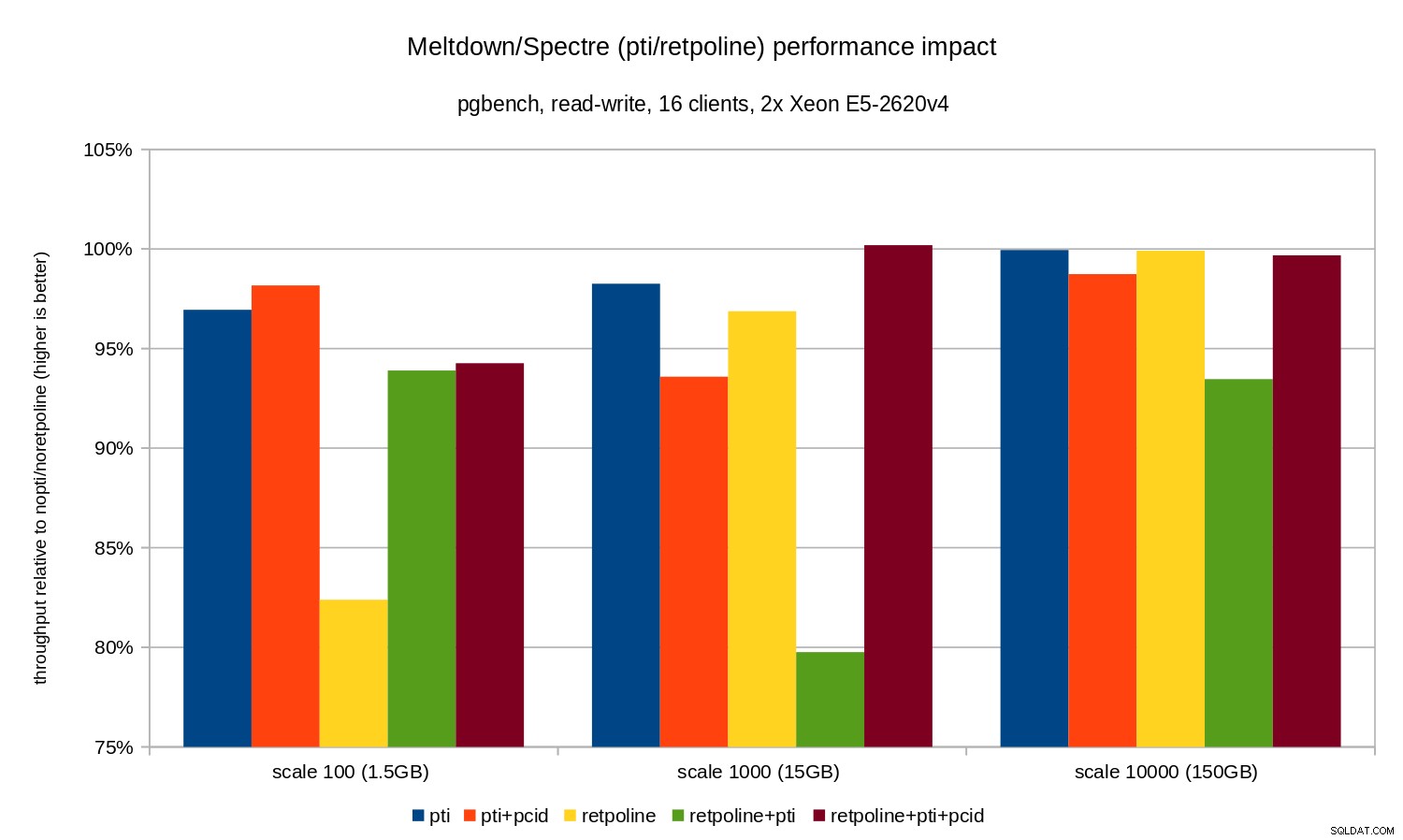
Le regressioni sono leggermente inferiori rispetto al caso di sola lettura:meno dell'8% senza pcid e meno del 3% con pcid abilitato. Questa è una conseguenza naturale del passare più tempo a eseguire l'I/O durante la scrittura di dati su WAL, lo svuotamento dei buffer modificati durante il checkpoint, ecc.
Ci sono due pezzi strani, però. In primo luogo, l'impatto di retpoline è inaspettatamente grande (vicino al 20%) per la scala 100 e lo stesso è accaduto per retpoline+pti su scala 1000. Le ragioni non sono del tutto chiare e richiederanno ulteriori indagini.
OLAP
Il carico di lavoro di analisi è stato modellato dal benchmark dbt-3. Innanzitutto, diamo un'occhiata ai risultati in scala di 10 GB, che si adattano interamente alla RAM (inclusi tutti gli indici, ecc.). Analogamente a OLTP, non siamo molto interessati ai numeri assoluti, che in questo caso sarebbero la durata delle singole query. Osserveremo invece un rallentamento rispetto a nopti/noretpoline , ovvero:
(duration without patches) / (duration with patches)
Supponendo che le attenuazioni comportino un rallentamento, otterremo valori compresi tra 0% e 100% dove 100% significa "nessun impatto". I risultati si presentano così:
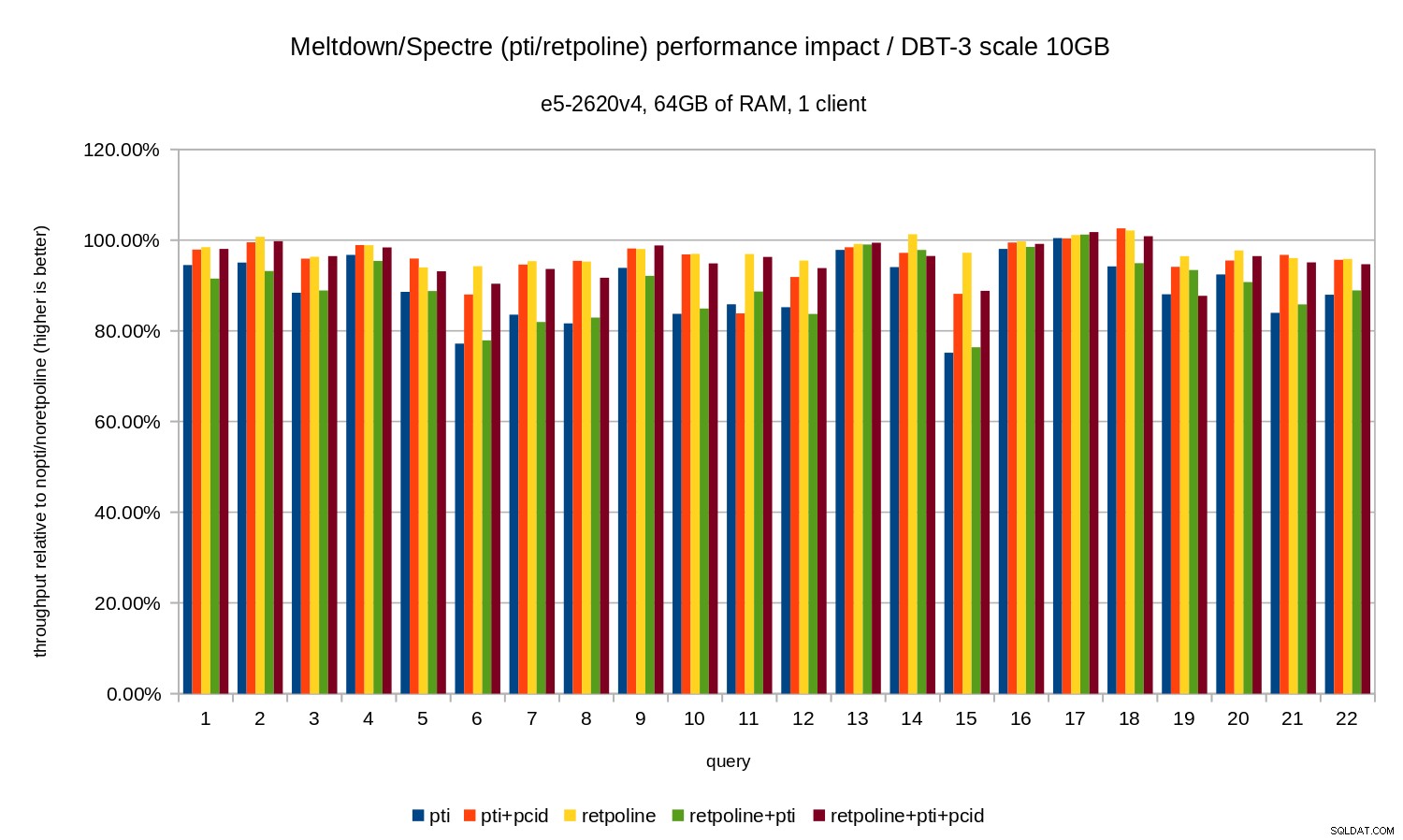
Cioè, senza il pcid la regressione è generalmente nell'intervallo 10-20%, a seconda della query. E con pcid la regressione scende a meno del 5% (e generalmente vicino allo 0%). Ancora una volta, questo conferma l'importanza di pcid caratteristica.
Per il set di dati da 50 GB (che corrisponde a circa 120 GB con tutti gli indici ecc.) l'impatto è simile al seguente:
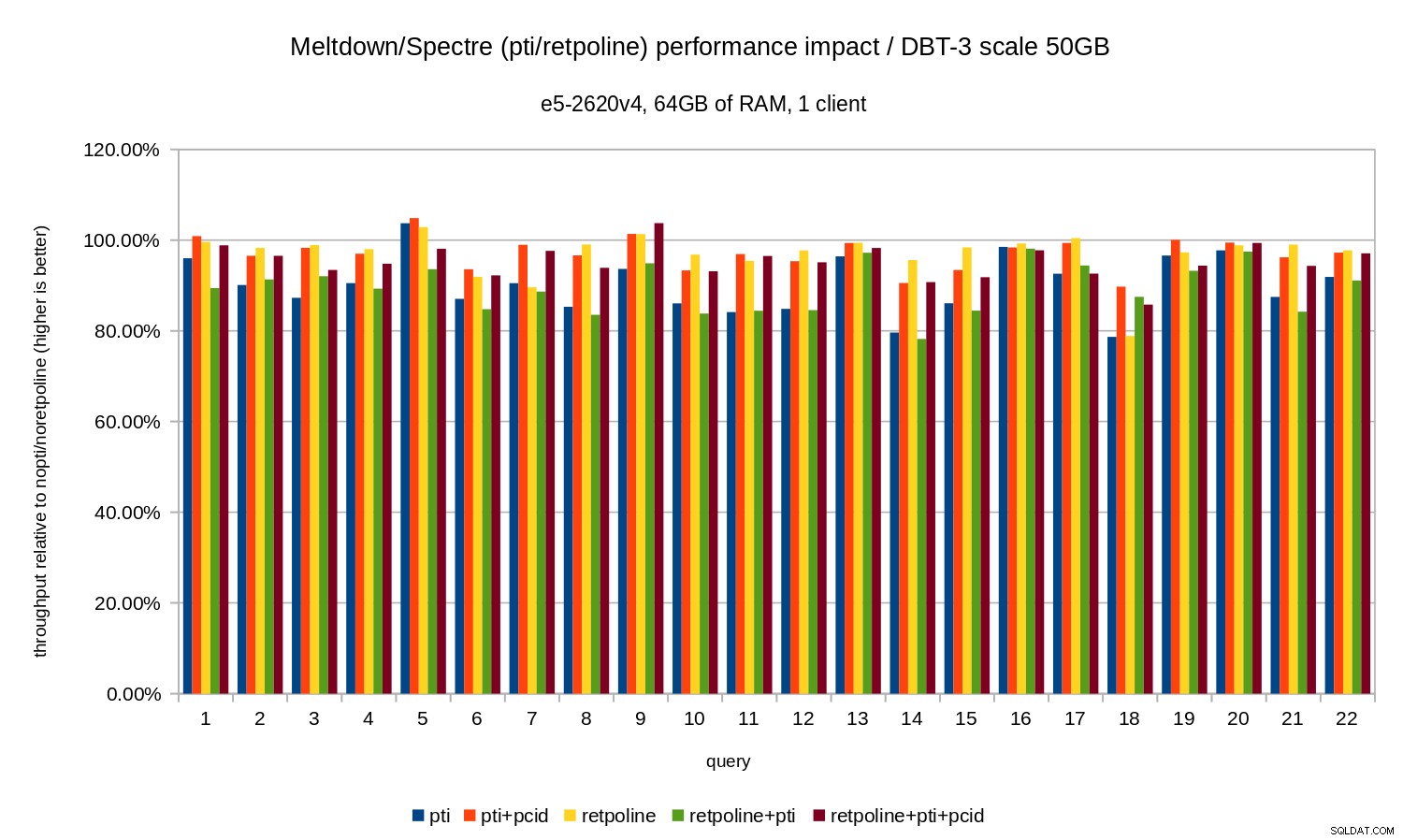
Quindi, proprio come nel caso di 10 GB, le regressioni sono inferiori al 20% e pcid li riduce significativamente, vicino allo 0% nella maggior parte dei casi.
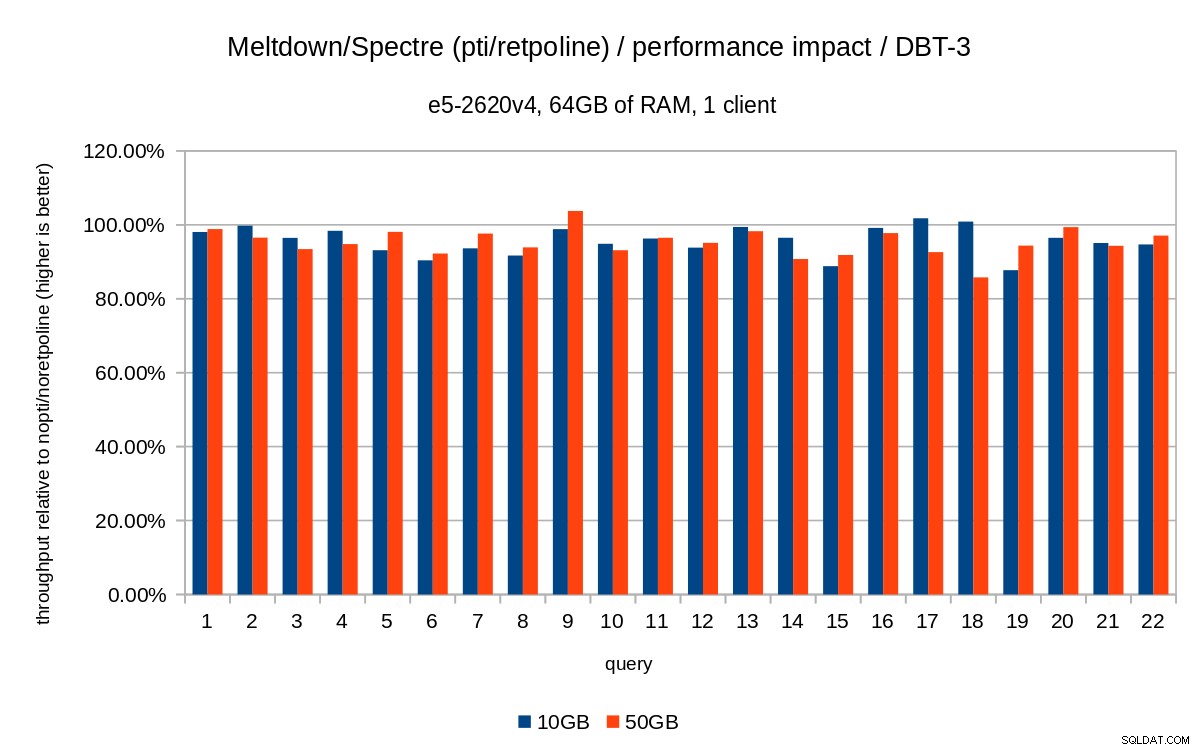
I grafici precedenti sono un po' disordinati:ci sono 22 query e 5 serie di dati, il che è un po' troppo per un singolo grafico. Quindi ecco un grafico che mostra l'impatto solo per tutte e tre le funzionalità (pti , pcid e retpoline ), per entrambe le dimensioni del set di dati.
Conclusione
Per riassumere brevemente i risultati:
retpolineha un impatto minimo sulle prestazioni- OLTP:la regressione è di circa il 10-15% senza il
pcide circa l'1-5% conpcid. - OLAP:la regressione è fino al 20% senza il
pcide circa l'1-5% conpcid. - Per i carichi di lavoro legati all'I/O (ad es. OLTP con il set di dati più ampio), Meltdown ha un impatto trascurabile.
L'impatto sembra essere molto inferiore rispetto alle stime iniziali (30%), almeno per i carichi di lavoro testati. Molti sistemi funzionano al 70-80% della CPU nei periodi di punta e il 30% saturerebbe completamente la capacità della CPU. Ma in pratica l'impatto sembra essere inferiore al 5%, almeno quando il pcid viene utilizzata l'opzione.
Non fraintendetemi, il calo del 5% è ancora una grave regressione. Certamente è qualcosa di cui ci preoccuperemmo durante lo sviluppo di PostgreSQL, ad es. durante la valutazione dell'impatto delle patch proposte. Ma è qualcosa che i sistemi esistenti dovrebbero gestire bene:se l'aumento del 5% nell'utilizzo della CPU porta il tuo sistema sopra l'egde, hai problemi anche senza Meltdown/Spectre.
Chiaramente, questa non è la fine delle correzioni di Meltdown/Spectre. Gli sviluppatori del kernel stanno ancora lavorando per migliorare le protezioni e aggiungerne di nuove, mentre Intel e altri produttori di CPU stanno lavorando sugli aggiornamenti del microcodice. E non è che conosciamo tutte le possibili varianti delle vulnerabilità, poiché i ricercatori sono riusciti a trovare nuove varianti degli attacchi.
Quindi c'è altro in arrivo e sarà interessante vedere quale sarà l'impatto sulle prestazioni.