Negli ultimi mesi, noi di 2ndQuadrant abbiamo lavorato all'unione di PostgreSQL 9.6 in Postgres-XL, che si è rivelata piuttosto impegnativa per vari motivi e ha richiesto più tempo del previsto a causa di numerose modifiche invasive a monte. Se sei interessato, guarda il repository ufficiale qui (guarda il ramo "master" per ora).
C'è ancora un bel po' di lavoro da fare:unire alcuni bit rimanenti dall'upstream, correggere bug noti e errori di regressione, test, ecc. Se stai pensando di contribuire a Postgres-XL, questa è un'opportunità ideale (inviami un e-mail e ti aiuterò con i primi passi).
Ma nel complesso, Postgres-XL 9.6 è chiaramente un importante passo avanti in una serie di aree importanti.
Nuove funzionalità in Postgres-XL 9.6
Quindi, quali nuove funzionalità ottiene Postgres-XL dall'unione di PostgreSQL 9.6? Potrei semplicemente indicarti le note di rilascio a monte:la maggior parte dei miglioramenti si applicano direttamente a XL 9.6, ad eccezione di quelli relativi alle funzionalità non supportate su XL.
Il principale miglioramento visibile all'utente in PostgreSQL 9.6 era chiaramente la query parallela, e questo vale anche per Postgres-XL 9.6.
Parallelismo tra nodi
Prima di PostgreSQL 9.6, Postgres-XL era uno dei modi per ottenere query parallele (posizionando più nodi Postgres-XL sulla stessa macchina). Da PostgreSQL 9.6 non è più necessario, ma significa anche che Postgres-XL ottiene la capacità di parallelismo intra-nodo.
Per fare un confronto, questo è ciò che Postgres-XL 9.5 ti ha permesso di fare:distribuire una query a più nodi di dati, ma ogni nodo di dati era comunque soggetto al limite "un back-end per query", proprio come PostgreSQL semplice.
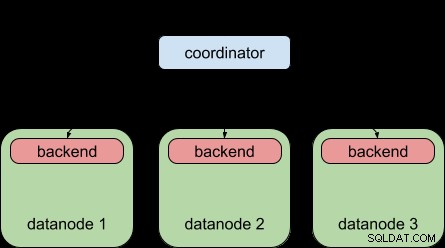
Grazie alla funzione di query parallela di PostgreSQL 9.6, Postgres-XL 9.6 ora può fare questo:
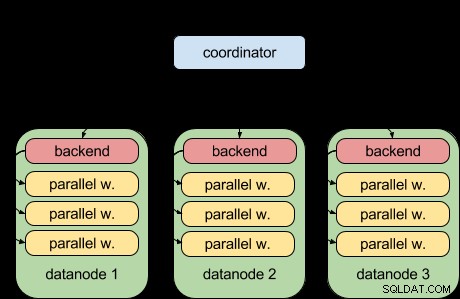
In altre parole, ogni nodo di dati può ora eseguire la sua parte della query in parallelo, utilizzando l'infrastruttura di query parallela a monte. È fantastico e rende Postgres-XL molto più potente quando si tratta di carichi di lavoro analitici.
Manutenzione di un fork
Ho detto che questa fusione si è rivelata più impegnativa di quanto ci aspettassimo inizialmente, per una serie di motivi.
In primo luogo, mantenere i fork in generale è difficile, in particolare quando il progetto a monte si muove alla velocità di PostgreSQL. Devi sviluppare funzionalità specifiche per il tuo fork, motivo per cui i fork esistono in primo luogo. Ma vuoi anche stare al passo con il monte, altrimenti rimani irrimediabilmente indietro. Ecco perché alcuni dei fork esistenti sono ancora bloccati su PostgreSQL 8.x, mancando tutte le chicche commesse da allora.
In secondo luogo, l'unione è avvenuta in un unico grande insieme, proprio come tutte le precedenti (9.5, 9.2, …). Cioè, tutti i commit upstream sono stati uniti in un unico comando git merge. È abbastanza garantito che causi molti conflitti di unione, nella misura in cui il codice non viene nemmeno compilato, per non parlare dell'esecuzione di test di regressione o qualcosa del genere.
Quindi il primo batch di correzioni riguarda il portarlo in uno stato compilabile, il batch successivo riguarda il farlo funzionare effettivamente senza segfault immediati, e quindi infine inizia la correzione "normale" (esegui test di regressione, risolve problemi, risciacqua e ripeti) .
Queste complessità sono inerenti alla manutenzione del fork (e un motivo per cui dovresti probabilmente riconsiderare l'avvio di un altro fork e invece contribuire direttamente a Postgres e/o Postgres-XL).
Ma ci sono modi per ridurre significativamente l'impatto, ad esempio prevediamo di eseguire la prossima fusione (con PostgreSQL 10) in blocchi più piccoli. Ciò dovrebbe ridurre al minimo l'entità dei conflitti di fusione e consentirci di risolvere gli errori molto più velocemente.
Più vicino a PostgreSQL
È interessante notare che l'adozione del parallelismo dall'upstream ci ha anche permesso di eliminare molto codice dalla base di codice XL:un ottimo esempio di ciò è il codice aggregato parallelo, che ha facilmente sostituito il codice specifico di XL.
Un altro esempio di modifica a monte che ha influito in modo significativo sul codice XL è la "pathification" del pianificatore superiore, spinta verso la fine del ciclo di sviluppo 9.6. Questo si è rivelato essere un cambiamento molto invasivo (in effetti è probabile che un certo numero di bug aperti sia correlato ad esso), ma alla fine ci ha permesso di semplificare il codice di pianificazione (essenzialmente costruire percorsi adeguati invece di modificare il piano risultante).
Quando dico che l'unione ci ha permesso di semplificare il codice XL e renderlo più vicino a PostgreSQL, cosa intendo con questo? Il modo più semplice per quantificare la modifica è eseguire "git diff –stat" rispetto al ramo a monte corrispondente e confrontare i numeri. Per i rami 9.5 e 9.6, i risultati hanno il seguente aspetto:
| versione | file modificati | aggiunte | eliminazioni |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Chiaramente, l'unione 9.6 riduce significativamente il delta rispetto a monte (di circa il 14% in totale). Da dove viene questa differenza?
In primo luogo, parte di tale riduzione è dovuta a una vera semplificazione del codice. Un ottimo esempio di ciò è l'aggregato parallelo, che è praticamente una sostituzione 1:1 dell'implementazione originale di Postgres-XL. Quindi l'abbiamo appena strappato e utilizziamo invece l'implementazione a monte. Ci auguriamo di trovare altri posti simili in futuro e di utilizzare l'implementazione a monte invece di mantenere la nostra.
In secondo luogo, gran parte della riduzione deriva dalla rimozione del codice morto. Non solo abbiamo ridotto alcuni bit di codice morti/irraggiungibili, abbiamo anche scoperto un bel po' di file sorgente che non sono stati nemmeno compilati e così via.
Cosa c'è dopo?
A questo punto abbiamo unito le modifiche fino a b5bce6c1, che è il punto in cui PostgreSQL 9.6 si è separato dal master. Quindi, per recuperare il ritardo con PostgreSQL 9.6.2, dobbiamo unire le modifiche rimanenti nel ramo 9.6. Considerando che dovrebbero esserci per lo più solo correzioni di bug, dovrebbe essere un lavoro (si spera) abbastanza semplice rispetto all'unione completa.
Ovviamente ci saranno dei bug. In effetti, a questo punto ci sono ancora alcuni test di regressione falliti. Questo deve essere risolto prima di fare una versione ufficiale di XL 9.6. E abbiamo bisogno di fare più test, quindi se sei interessato ad aiutare Postgres-XL, questo sarebbe estremamente vantaggioso.
Un fastidio di cui continuiamo a sentire parlare sono i pacchetti o la loro mancanza. Potresti aver notato che gli ultimi pacchetti disponibili sono piuttosto vecchi e c'è solo .rpm, nient'altro. Abbiamo in programma di affrontare questo problema e iniziare a offrire pacchetti aggiornati in più versioni (ad es. .rpm e .deb).
Abbiamo anche in programma di apportare alcune modifiche al modo in cui è organizzato il processo di sviluppo, per rendere più facile contribuire e partecipare al processo di sviluppo. Questo è davvero un argomento separato non correlato al ramo 9.6, quindi pubblicherò maggiori dettagli al riguardo tra pochi giorni.