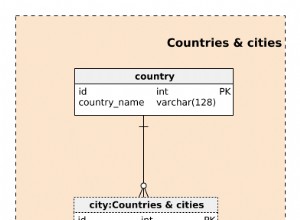
Una delle sfide quando si ha a che fare con una nuova progettazione di database è che non si conoscono cose come quanto saranno grandi le tabelle finché non saranno effettivamente popolate con una discreta quantità di dati. Ma se il progetto deve tenere conto degli eventuali problemi di scalabilità, non è possibile implementarlo per ottenere quei dati fino a quando non viene eseguita la stima. Un modo per aggirare questo è prototipare in modo aggressivo le cose. Usa l'hardware di staging per questo scopo su cui le nuove applicazioni possono vivere temporaneamente mentre riordinano dettagli come questo. Puoi semplicemente considerare che dovrai spostare l'app ed eventualmente riprogettarla dopo alcuni mesi, quando avrai un'idea migliore di quali dati verranno visualizzati al suo interno.
L'altro modo per aggirare questo problema di gallina/uovo è scrivere un generatore di dati. Costruisci a mano un numero sufficiente di dati campione per vedere che aspetto ha, quanto è denso e come sono distribuiti i suoi valori. Quindi scrivi qualcosa che prenda quelle statistiche e produca un set di dati più ampio simile ad esso. Non lo farai mai per essere perfetto, ma non deve esserlo. La generazione di set di dati giganteschi, anche con alcuni difetti, è ancora il modo migliore disponibile per eseguire la stima delle dimensioni del database. Ci sono così tante fonti di sovraccarico che è difficile tenere conto del fatto che qualsiasi tabella misurata e dimensioni dell'indice, basate su qualcosa come i tuoi dati, sarà molto più accurata di qualsiasi altro approccio. C'è un motivo per cui finisco per rispondere a molte domande sui problemi relativi alle prestazioni utilizzando pgbench per creare prima un database delle dimensioni appropriate.
Tuttavia, la generazione dei dati non è facile. Generare timestamp realistici in particolare è sempre fastidioso. E indipendentemente dall'efficienza con cui pensi di averli scritti, di solito richiedono più tempo del previsto per l'esecuzione e anche più tempo per ottenere i dati risultanti in un database e indicizzati correttamente.
E questo continua ad essere il caso, non importa quante volte lo hai fatto, perché anche se fai tutto bene, la legge di Murphy si intrometterà per rendere il lavoro doloroso a prescindere. I miei computer a casa sono tutti costruiti con hardware PC relativamente economico. Non sono le cose più economiche disponibili – ho degli standard – ma certamente non usando la stessa qualità che consiglierei alle persone di cercare in un server. Il problema di generazione dei dati di questa settimana ha ricordato perché un hardware migliore vale quanto costa per un lavoro critico per l'azienda.
Dopo aver generato alcuni miliardi di righe di dati e aver guardato l'importazione per 10 ore, non mi ha fatto piacere che l'intero lavoro si interrompesse in questo modo:
psql:load.sql:10: ERROR: invalid input syntax for type timestamp: "201^Q-04-14 12:17:55"
CONTEXT: COPY testdata, line 181782001, column some_timestamp: "201^Q-04-14 12:17:55"
Risulta, da qualche parte nel mezzo della scrittura dei 250 GB di dati di test che ho generato, una delle righe in uscita era danneggiata. Due bit sono stati capovolti e i dati scritti erano errati. Non so con certezza dove sia successo.
La memoria è il sospetto più probabile. I server reali utilizzano la RAM ECC e per una buona ragione. Se monitori un sistema con molta RAM, il numero di errori corretti in modo invisibile da ECC può essere scioccante. La RAM che uso a casa è buona, ma i tassi di errore su qualsiasi memoria senza capacità di rilevamento/correzione degli errori saranno più alti di quanto potresti desiderare e non verranno mai rilevati a meno che non si verifichino nel codice che porta a un arresto anomalo del sistema. Il lavoro di generazione dei dati è utile per esporre questi problemi, perché in genere mette almeno una CPU sul server sotto carico pesante per potenzialmente giorni di fila. Se c'è qualche instabilità nel tuo sistema, riscaldarlo e lasciarlo andare per molto tempo lo aggraverà.
Un secondo livello di protezione contro questo tipo di danneggiamento consiste nell'inserire dei checksum sui dati scritti su disco, per proteggerli da errori di scrittura e quindi rileggere i dati. Il checksum dei blocchi eseguito dal filesystem ZFS è una delle migliori implementazioni di questo. Nel mio caso, se avessi usato ZFS o meno potrebbe non aver fatto alcuna differenza. Se i bit fossero stati capovolti prima che si verificasse il checksum del blocco, avrei scritto i dati spazzatura, con un checksum spazzatura corrispondente, a prescindere.
Il mio passo successivo è stato usare la split utilità per prendere il mio file gigante e romperlo in più piccoli pezzi, un altro paio d'ore per aspettare che finisca. Quindi potrei iniziare a caricare i file buoni mentre correggo quelli cattivi.
Dato che i file risultanti erano 13 GB ciascuno e il mio server ha 16 GB di RAM, anche se potrei correggere questo errore di battitura di un carattere usando vi. Teoricamente dovrebbe essere così, ma comincio ad avere i miei dubbi visto da quanto tempo ho aspettato che il file si riscrivesse in seguito:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21495 gsmith 20 0 8542m 8.3g 1544 R 98 53.0 419:56.70 vi datafile-ag
Sono 7 ore che ho aspettato solo che questo errore di battitura di un personaggio venisse corretto, così posso finire di caricare i dati del test. Come dicevo, una seria generazione di dati non è mai facile.