Nei nostri precedenti blog sul cloud ibrido, menzioniamo spesso che una delle opzioni principali per avvalersi della configurazione della topologia del cloud ibrido è utilizzarla come destinazione del ripristino di emergenza. È comune per una struttura organizzativa che un piano di ripristino di emergenza (DRP) venga sempre affrontato prima dell'implementazione dell'architettura della configurazione del database, nel cloud o in locale. Potresti pensare che tutto fallirà in modo imprevedibile e possa influenzare tragicamente la tua attività se non viene affrontato e compreso correttamente. Il superamento di queste sfide richiede un efficace DRP (Disaster Recovery Plan), per il quale il sistema è ben configurato in base alla propria applicazione, infrastruttura e requisiti aziendali. La chiave del successo in questo tipo di situazioni è la velocità con cui possiamo risolvere o risolvere il problema.
Mentre DRP affronta le circostanze del disastro, Business Continuity si assicurerà che DRP sia testato e operativo in ogni momento, quando necessario. Le opzioni di Disaster Recovery per i database devono garantire operazioni continue e limiti ai limiti delle aspettative. Deve essere in linea con l'RTO e l'RPO desiderati. È fondamentale garantire che i database di produzione siano disponibili per le applicazioni anche durante i disastri; altrimenti, potrebbe finire per essere un affare costoso. I DBA, gli architetti, devono garantire che gli ambienti di database possano sostenere disastri e siano conformi agli SLA per il ripristino di emergenza. Le distribuzioni del database devono essere configurate correttamente per garantire che i disastri non influiscano sulla disponibilità del database e sulla continuità aziendale.
Opzioni di ripristino di emergenza
Il tuo cluster PostgreSQL deve essere configurato con un approccio sistematico che rispetta le migliori pratiche ed è accettabile per gli standard del settore. Insieme agli approcci sistematici, i seguenti processi o meccanismi ti aiutano a garantire che il tuo PostgreSQL distribuito su un cloud ibrido abbia queste presenze:
-
Failover/Switchover
-
Backup automatico
-
Altamente disponibile
-
Bilanciamento del carico
-
Ambiente ad alta distribuzione
Failover/commutazione
Il failover è un processo automatizzato nel caso in cui il tuo master fallisca; il server hot standby o warm standby viene promosso al ruolo di primario/master. È una procedura consigliata che consente a un ambiente a disponibilità elevata di avere almeno un nodo secondario che agisca come candidato per un nodo di failover. Una volta che il server primario si guasta, il server standby dovrebbe iniziare le procedure di failover, quindi il server secondario o standby assumerà il ruolo di master. Un sistema di failover utilizza normalmente un minimo di due server, che fungono da primario e standby. Il suo controllo della connettività è assistito da un meccanismo heartbeat che esegue controlli continui e verifica se entrambi sono in buono stato e la comunicazione è attiva. Tuttavia, in alcuni casi, la connettività può dare un falso allarme. Pertanto, in alcune configurazioni e ambienti, la presenza di un terzo sistema, ad esempio un nodo di monitoraggio, si trova su una rete o un data center separato. Questa è un'opzione infallibile per prevenire il failover inappropriato o indesiderato. Un nodo di verifica infallibile può possedere funzionalità e controlli aggiuntivi, il che aggiunge complessità. Questa configurazione richiede test completi e rigorosi per garantire che il failover venga eseguito correttamente quando si verifica una modifica nell'implementazione. Inoltre, questo è importante per prevenire qualsiasi deterioramento di PostgreSQL
Supponiamo che tu abbia il tuo cluster secondario o standby su un datacenter diverso con una diversa configurazione hardware; potresti non voler eseguire il failover bruscamente, soprattutto se non è un caso ideale a causa solo di un falso positivo. Tuttavia, in questo scenario, il nodo o il cluster di destinazione del ripristino dei dati deve disporre delle stesse risorse e specifiche del nodo o del cluster principale. Se il tuo obiettivo di recupero dati si trova in un cloud pubblico e quello primario è in locale, assicurati che sia già stato coperto nella pianificazione della capacità e che le risorse abbiano quasi le stesse specifiche per evitare risultati indesiderati.
Quando utilizzi e ti prepari per il tuo meccanismo di failover nel tuo cluster PostgreSQL all'interno di un cloud ibrido, devi assicurarti che il tuo strumento sia perfetto per svolgere il lavoro che dovrebbe raggiungere. Esistono strumenti di terze parti che non sono inclusi in PostgreSQL per quanto riguarda il failover avanzato. Ad esempio, c'è ClusterControl, pg_auto_failover di CitusData (c/o Microsoft), Pgpool-II, Bucardo e altri. Questi strumenti di utilità avanzati forniscono scherma dei nodi o notoriamente conosciuti come STONITH (spara all'altro nodo nella testa). Ciò garantisce che il tuo nodo primario o master guasto eviti di accettare scritture o di tornare online come suo stato precedente per servire le normali transazioni. Questo problema è comunemente noto come scenario del cervello diviso. Perde la sincronizzazione dei dati a causa di un errore (hardware o livello di risorsa), ma i tuoi server primari, che presumibilmente è solo un server primario, si comportano come se ricevessero normali richieste di scrittura dei dati causando il danneggiamento dei dati a livello di cluster.
Backup automatizzato
I backup forniscono sempre un'elevata sicurezza e protezione contro la perdita di dati. Il backup massimizza il tuo RPO in quanto aiuta a ridurre al minimo la perdita di dati in caso di disastro. Le cose che devi considerare e preparare per il tuo backup automatico riguardano l'appliance/hardware di backup, la ridondanza dei dati di backup, la sicurezza, le prestazioni, la velocità e l'archiviazione dei dati.
Appliance di backup
Devi avere la scelta migliore per il tuo dispositivo di backup qui. Velocità, volume di archiviazione significativo e disponibilità elevata possono essere la scelta desiderata. Alcuni si affidano all'archiviazione SAN o NAS o distribuiscono i propri dati ad altri provider di archiviazione di backup di terze parti. È essenziale che l'appliance di backup offra velocità per la scrittura e la lettura dei dati, soprattutto se si applica la compressione e la crittografia ai dati inattivi. La decompressione e la decrittazione richiedono risorse, quindi devi considerare quando devi utilizzare il recupero dei dati. Durante questo stato, devi determinare che devi raggiungere il tuo RPO massimo e impegnare lo SLA (Service-Level Agreement) ottenibile ai tuoi clienti. È anche ideale che potresti dover isolare il backup dalla rete locale o archiviarlo in una posizione remota. Un approccio alternativo è quello di impegnarsi con fornitori di terze parti. Ad esempio, l'archiviazione del backup nel cloud può essere un'opzione e la loro struttura è altamente sofisticata e soddisfa le tue esigenze.
Ridondanza dei dati di backup
La diffusione dei dati in più posizioni è una soluzione ideale. Ciò rafforza le tue possibilità di recupero dei dati, ad esempio, un errore umano o un errore logico del software che causa l'eliminazione di vecchie copie del backup ma elimina erroneamente l'intera copia di backup cruciale. In alcuni ambienti sofisticati, come l'archiviazione in un ambiente cloud come Amazon S3, Cloud Storage di Google o Azure Blob Storage offre la replica dei file archiviati. Ciò fornisce una maggiore ridondanza e può essere configurato in modo flessibile in base alle tue esigenze.
Altamente disponibile
Un cluster PostgreSQL ad alta disponibilità in un cloud ibrido assicura sempre che la comunicazione del database garantisca tempi di attività. Il caso ideale di alta disponibilità dipende dalla misurazione della tua disponibilità. In questo caso, una configurazione comune per un PostgreSQL distribuito in un cloud ibrido può essere il tuo database ospitato in un cloud pubblico può essere il tuo cluster secondario che funge da cluster di recupero dati nel caso in cui il cluster primario si guasta o subisce un disastro di rete e può richiedere molto tempo morto. In alcune configurazioni, è possibile che il cluster secondario che si trova nel cloud pubblico potrebbe non essere esattamente sofisticato come il primario, diciamo che questo è il tuo cloud locale o privato. La tua applicazione può giocare per limitare i visitatori o il traffico che può connettersi al tuo database. Questo tipo di scenario può ridurre i costi di installazione, ma ovviamente dipende solo dalle tue esigenze. Se il tuo tipo di applicazione è enorme e deve ricevere ininterrottamente situazioni di traffico da normale a intenso, assicurati che le risorse del cluster secondario debbano essere potenti quanto quelle primarie per garantire un'elevata disponibilità, ovvero 99,9999999%.
Per ottenere un cluster PostgreSQL a disponibilità elevata in un ambiente cloud ibrido, è necessario disporre di un meccanismo di failover. In caso di guasto e di guasto di un cluster primario o di un server primario, un server secondario o di standby può quindi assumere il ruolo di master, qualunque sia la sua posizione. La cosa più importante è la funzionalità e le prestazioni, soprattutto dal punto di vista dell'applicazione o del client, non vengono influenzate affatto o almeno in minima parte.
Bilanciamento del carico
Il meccanismo di bilanciamento del carico per il tuo cluster PostgreSQL aiuta la configurazione del cloud ibrido, che è più gestibile e meno rischioso, soprattutto quando si verifica un carico di traffico elevato. In molte situazioni, un server riceve un carico elevato e grave causa il panico del server. Ciò porta a uno stato inutilizzabile del server a causa delle risorse occupate consumate da molti thread in esecuzione in background. Questa situazione può essere migliorata correggendo le query errate e l'architettura di progettazione del database. Ciò dovrebbe includere il modo in cui si distribuisce la lettura rispetto al carico di scrittura e una comprensione approfondita dei requisiti dell'applicazione come l'impostazione master-master o solo un master, ma ridimensionandolo verticalmente per fornire maggiori risorse di elaborazione e memoria. C'è anche un'ampia selezione di strumenti di terze parti come pgbouncer e Pgpool II per aiutare la tua distribuzione di PostgreSQL in un ambiente cloud ibrido.
Ambiente ad alta distribuzione
Per quanto riguarda la scalabilità, l'elevata distribuzione in più posizioni o diversi provider di cloud (on-premise o cloud privato e pubblico) offre maggiore flessibilità e tollerabilità in un ambiente cloud ibrido e questo è ottimo per il ripristino di emergenza. È flessibile quando è necessario eseguire il failover su una particolare posizione cloud favorevole a disastri naturali o catastrofi, soprattutto se la regione designata in cui risiede il cluster principale è attualmente devastata o interessata da una causa naturale. Questa è una causa inevitabile che devi capire ed essere affidabile della situazione attuale. La tua applicazione e i tuoi clienti devono essere serviti continuamente senza interruzioni. Questo serve allo scopo di essere disponibile pubblicamente nel cloud mentre serve anche in un ambiente privato o locale. Questa configurazione aggiunge maggiore complessità e richiede conoscenze avanzate sul lato database, sicurezza e rete. L'ottimizzazione e l'ottimizzazione sono fondamentali per il successo in questo caso poiché è molto importante che, pur servendo una maggiore sicurezza per incapsulare i dati durante i viaggi su Internet, le prestazioni devono dimostrare di stabilizzarsi e non sono influenzate dalla configurazione implementata.
A causa della complessità della configurazione, disporre di uno strumento è l'ideale per gestire l'implementazione e facilitare lo stato generale dei database, supervisionando un aspetto del cluster ma a livello generale dal cloud privato on-premise, e sull'aspetto del cloud pubblico. Tutte le impostazioni devono essere mantenute a un livello gestibile e semplice in modo che, in caso di allarmi e avvisi, sia facile risolvere e affrontare il problema in modo corretto e tempestivo.
ClusterControl per il ripristino di emergenza in un ambiente cloud ibrido
ClusterControl consente all'organizzazione o alle aziende di gestire il database con flessibilità e ridurre la complessità complessiva della configurazione. ClusterControl offre failover, backup automatico, fornisce una configurazione ad alta disponibilità, bilanciamento del carico e supporta un'implementazione in ambiente distribuito, semplificando l'aggiunta di nodi in un cloud pubblico o privatamente o in locale.
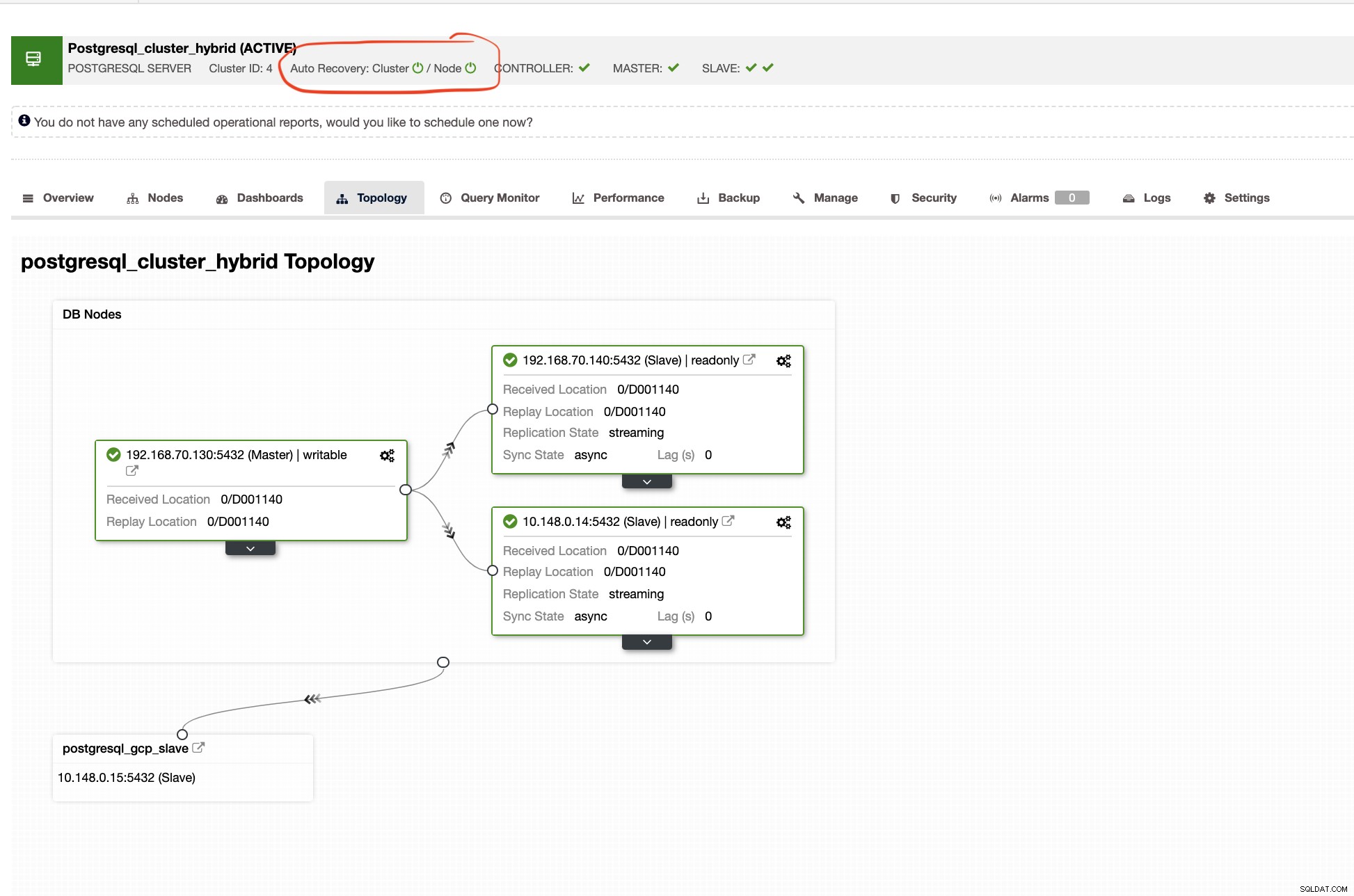
Recupero automatico di ClusterControl
Il ripristino automatico di ClusterControl rappresenta un sacco di meccanismi di failover e caratteristiche di ripristino, specialmente quando un nodo si interrompe o un cluster entra in uno stato degradato. Questo può essere fatto facilmente come mostrato nello screenshot qui sotto:
Backup e ripristino
ClusterControl ha anche una funzione di backup e ripristino che ti consente di gestire il backup, creare un backup, pianificare un backup e ripristinare un backup. La gestione del backup è molto semplice e la creazione o la pianificazione di un backup è semplice ma offre anche opzioni avanzate. Offre anche opzioni di backup su cloud che ti consentono di avere la ridondanza dei dati di backup, rafforzando le tue opzioni di ripristino di emergenza. Vedi sotto:
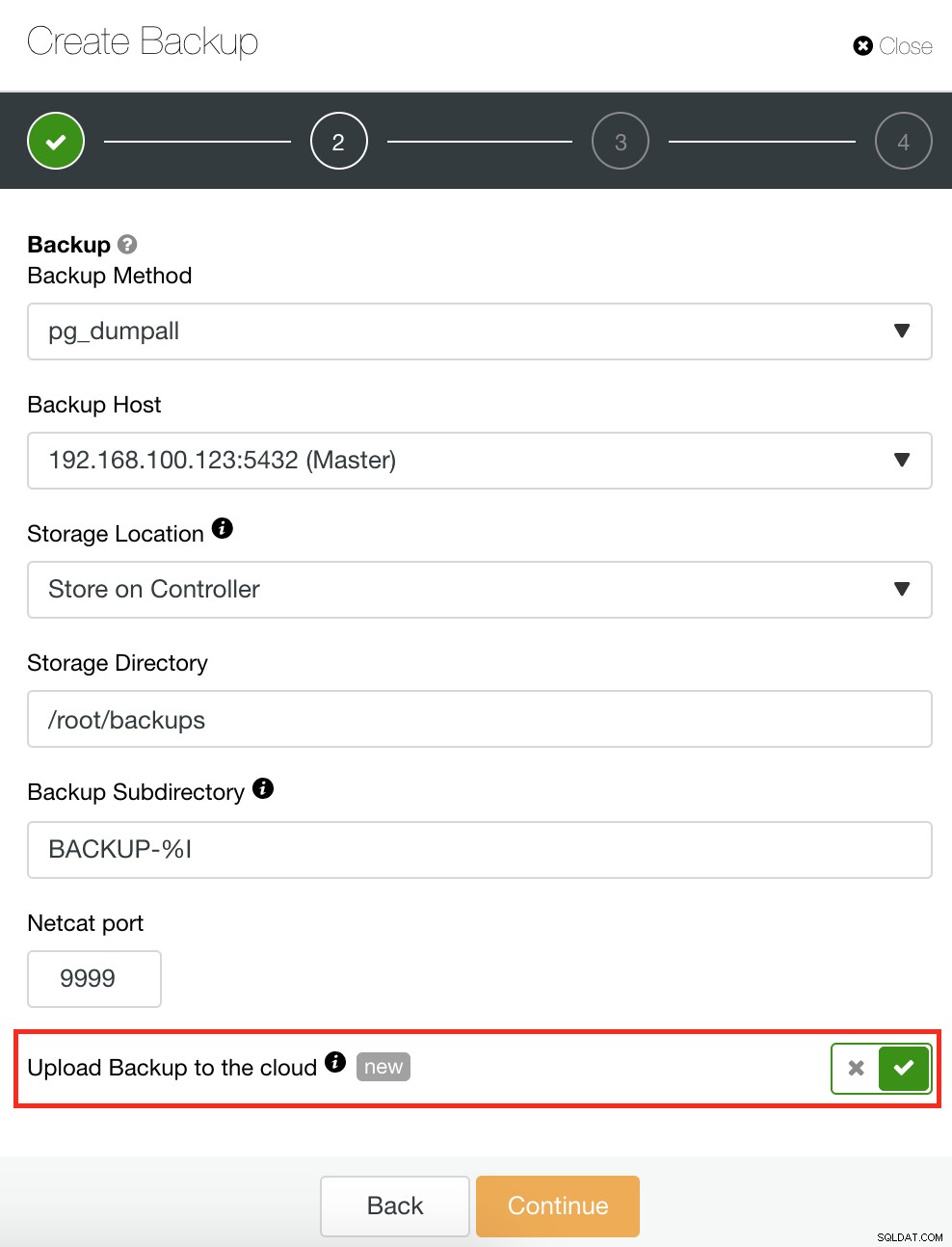
Come mostrato di seguito, la gestione del backup fornisce una semplice interfaccia utente per selezionare il backup che si desidera ripristinare, oppure potrebbe essere necessario eliminarlo. Il backup di ClusterControl consente di scegliere un periodo di conservazione, quindi nel caso in cui si disponga di un lungo elenco, alcuni di questi possono essere eliminati quando raggiunge il periodo di conservazione. 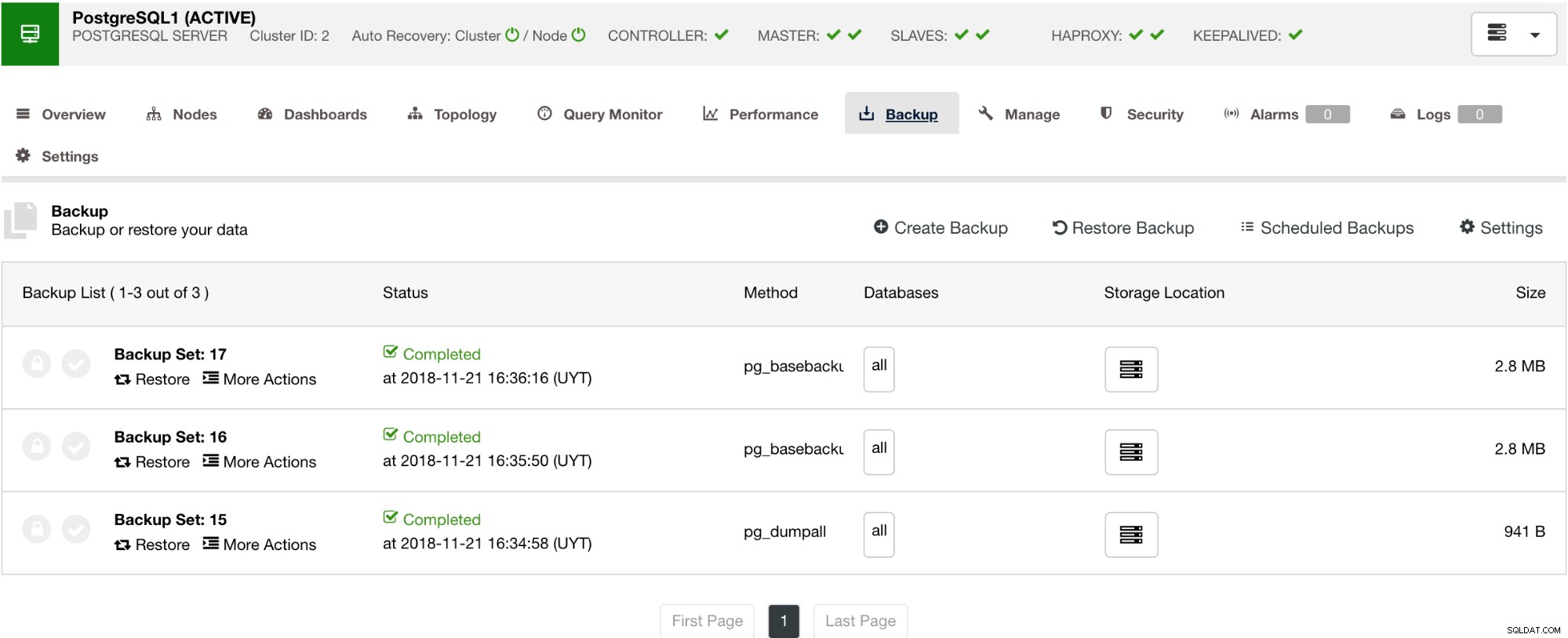
Supporta i meccanismi di alta disponibilità (HA) e di bilanciamento del carico (LB)
Non è necessario eseguire la configurazione manualmente o cercare modi per aggiungere un'elevata disponibilità nel cluster PostgreSQL. C'è un modo semplice e conveniente per portare a termine il lavoro con ClusterControl. Se puoi vedere lo screenshot di esempio, ha una configurazione HAProxy e Keepalived. Vedi screenshot qui sotto:
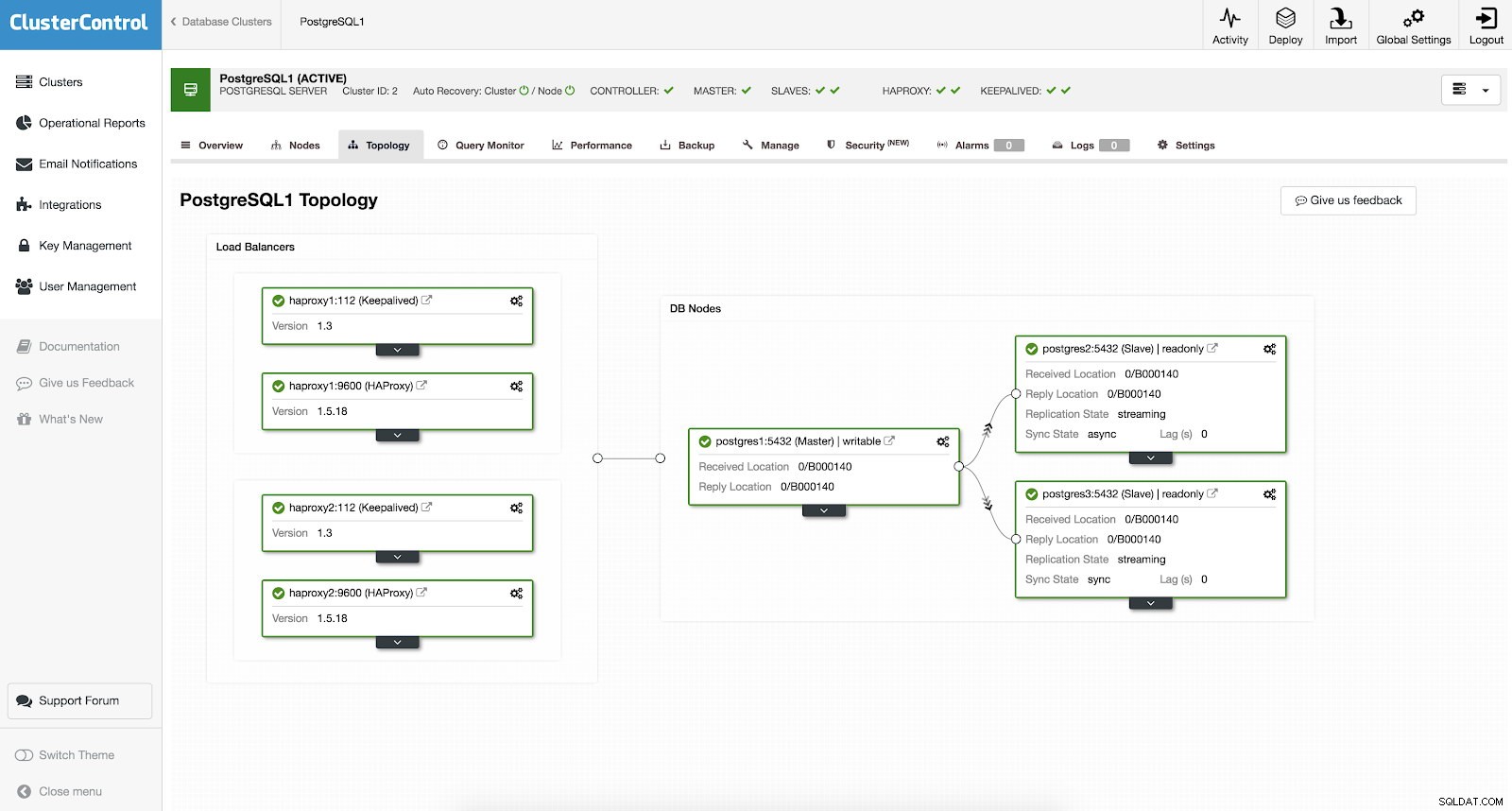
La configurazione di una disponibilità elevata con ClusterControl può essere eseguita passando da
Supporta l'ambiente distribuito
Se desideri distribuire uniformemente dal cloud locale o privato al cloud pubblico, ClusterControl supporta anche l'implementazione nel cloud. Ma per un cluster PostgreSQL e prevedi di avere uno slave secondario residente su un cloud diverso, puoi creare un cluster slave come mostrato di seguito,
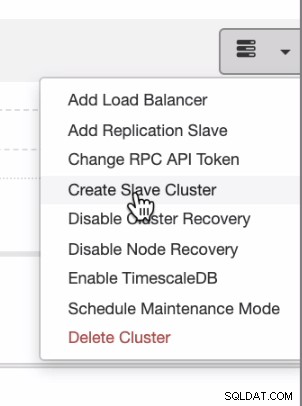
e puoi arrivare con il risultato finale come mostrato di seguito,

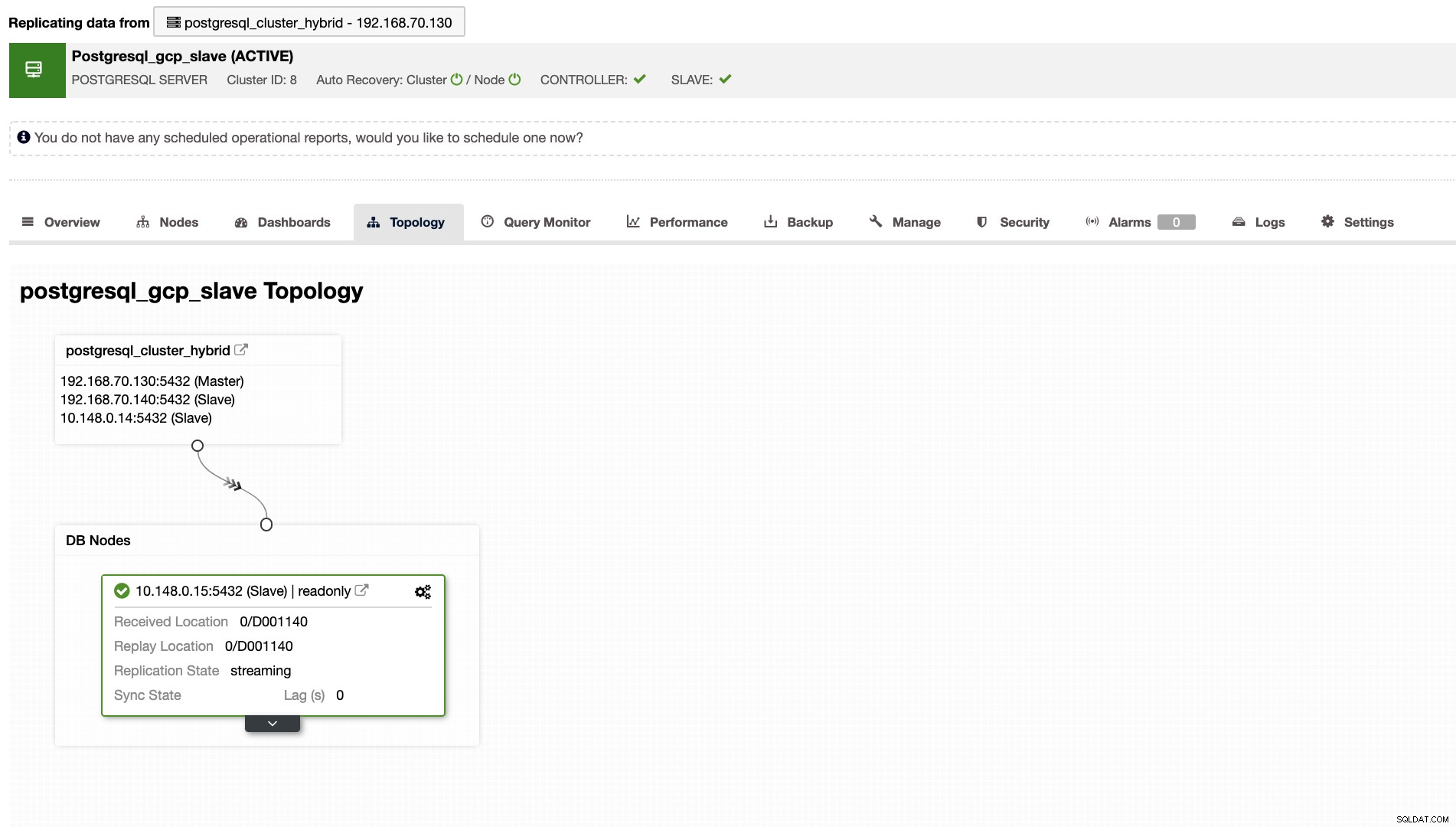
ClusterControl ti mostrerà anche la topologia corretta del tuo cluster ogni volta che disponi di una configurazione di un ambiente cloud ibrido. Vedi quanto segue di seguito,
Mentre nel cluster slave, la topologia mostrerà il suo albero di origine rivelando il suo master. Lo slave qui mostra come si trova in una rete separata situata principalmente in Google Cloud, mentre il master è in locale.
Conclusione
È accettabile ammettere che una configurazione di cloud ibrido, in particolare con il cluster PostgreSQL, aggiunge complessità. È necessario disporre dello strumento giusto con le opzioni presenti per supportare la pianificazione del ripristino di emergenza. Questi sono molto importanti per salvare ed evitare la tua attività dalla potenziale catastrofe di danni finanziari e perdita della fiducia dei clienti. Investi negli strumenti e nelle competenze giuste della tua tecnologia e salverai la tua attività dall'impatto negativo.