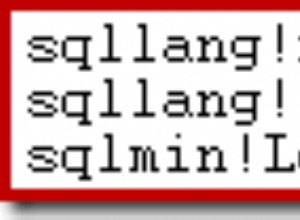
L'errore che ottieni:
ON CONFLICT Il comando DO UPDATE non può influenzare la riga una seconda volta
indica che stai tentando di inserire la stessa riga più di una volta in un singolo comando. In altre parole:hai dei duplicati su (name, url, email) nel tuo VALUES elenco. Piega i duplicati (se questa è un'opzione) e dovrebbe funzionare. Ma dovrai decidere quale riga scegliere da ciascuna serie di duplicati.
INSERT INTO feeds_person (created, modified, name, url, email)
SELECT DISTINCT ON (name, url, email) *
FROM (
VALUES
('blah', 'blah', 'blah', 'blah', 'blah')
-- ... more
) v(created, modified, name, url, email) -- match column list
ON CONFLICT (name, url, email) DO UPDATE
SET url = feeds_person.url
RETURNING id;
Poiché utilizziamo un VALUES indipendente expression ora, devi aggiungere cast di tipi espliciti per tipi non predefiniti. Come:
VALUES
(timestamptz '2016-03-12 02:47:56+01'
, timestamptz '2016-03-12 02:47:56+01'
, 'n3', 'u3', 'e3')
...
Il tuo timestamptz le colonne richiedono un cast di tipo esplicito, mentre i tipi di stringa possono funzionare con text predefinito . (Puoi ancora trasmettere a varchar(n) subito.)
Ci sono modi per determinare quale riga scegliere da ciascuna serie di duplicati:
- Seleziona la prima riga in ogni gruppo GROUP BY?
Hai ragione, non c'è (attualmente) alcun modo per essere esclusi righe nel RETURNING clausola. Cito il Wiki di Postgres:
Nota che RETURNING non rende visibile il "EXCLUDED.* " aliasdal UPDATE (solo il generico "TARGET.* " l'alias è visibile lì). Si ritiene che ciò crei una fastidiosa ambiguità per questi casi semplici e comuni [30] con scarsi o nessun beneficio. Ad un certo punto in futuro, potremmo perseguire un modo per esporre seRETURNING -le tuple proiettate sono state inserite e aggiornate, ma questo probabilmente non ha bisogno di essere inserito nella prima iterazione commit della funzione [31].
Tuttavia , non dovresti aggiornare le righe che non dovrebbero essere aggiornate. Gli aggiornamenti vuoti sono costosi quasi quanto gli aggiornamenti regolari e potrebbero avere effetti collaterali indesiderati. Non hai strettamente bisogno di UPSERT per cominciare, il tuo caso assomiglia più a "SELECT o INSERT". Correlati:
- SELEZIONA o INSERT in una funzione soggetta a condizioni di gara?
Uno un modo più pulito per inserire un set di righe sarebbe con CTE che modificano i dati:
WITH val AS (
SELECT DISTINCT ON (name, url, email) *
FROM (
VALUES
(timestamptz '2016-1-1 0:0+1', timestamptz '2016-1-1 0:0+1', 'n', 'u', 'e')
, ('2016-03-12 02:47:56+01', '2016-03-12 02:47:56+01', 'n1', 'u3', 'e3')
-- more (type cast only needed in 1st row)
) v(created, modified, name, url, email)
)
, ins AS (
INSERT INTO feeds_person (created, modified, name, url, email)
SELECT created, modified, name, url, email FROM val
ON CONFLICT (name, url, email) DO NOTHING
RETURNING id, name, url, email
)
SELECT 'inserted' AS how, id FROM ins -- inserted
UNION ALL
SELECT 'selected' AS how, f.id -- not inserted
FROM val v
JOIN feeds_person f USING (name, url, email);
La complessità aggiunta dovrebbe pagare per grandi tabelle in cui INSERT è la regola e SELECT l'eccezione.
Inizialmente avevo aggiunto un NOT EXISTS predicato sull'ultimo SELECT per evitare duplicati nel risultato. Ma era superfluo. Tutti i CTE di una singola query visualizzano gli stessi snapshot di tabelle. Il set restituito con ON CONFLICT (name, url, email) DO NOTHING si esclude a vicenda per il set restituito dopo il INNER JOIN sulle stesse colonne.
Sfortunatamente questo apre anche una piccola finestra per una condizione di gara . Se...
- una transazione simultanea inserisce righe in conflitto
- non si è ancora impegnato
- ma alla fine si impegna
... alcune righe potrebbero andare perse.
Potresti semplicemente INSERT .. ON CONFLICT DO NOTHING , seguito da un separato SELECT query per tutte le righe - all'interno della stessa transazione per superare questo problema. Che a sua volta apre un'altra piccola finestra per una condizione di gara se le transazioni simultanee possono eseguire il commit di scritture nella tabella tra INSERT e SELECT (in default READ COMMITTED livello di isolamento). Può essere evitato con REPEATABLE READ isolamento della transazione (o più rigoroso). O con un blocco di scrittura (possibilmente costoso o addirittura inaccettabile) sull'intero tavolo. Puoi ottenere qualsiasi comportamento di cui hai bisogno, ma potrebbe esserci un prezzo da pagare.
Correlati:
- Come utilizzare RETURNING con ON CONFLICT in PostgreSQL?
- Restituisci le righe da INSERT con ON CONFLICT senza dover aggiornare