La tua domanda è davvero impreciso. Per favore, segui i suggerimenti di @RiggsFolly e leggi i riferimenti su come porre una buona domanda.
Inoltre, come suggerito da @DuduMarkovitz, dovresti iniziare semplificando il problema e pulendo i tuoi dati. Alcune risorse per iniziare:
- Tutorial di base sull'elaborazione del testo di Matt Deny
- Gestione ed elaborazione di stringhe in R di Gaston Sanchez
Una volta che sei soddisfatto dei risultati, puoi quindi procedere all'identificazione di un gruppo per ogni Var1 entry (questo ti aiuterà lungo la strada per eseguire ulteriori analisi/manipolazioni su voci simili) Questo potrebbe essere fatto in molti modi diversi ma, come menzionato da @GordonLinoff, una delle possibilità è la distanza di Levenshtein.
Nota :per 50.000 voci, il risultato non sarà accurato al 100% in quanto non sarà sempre classificare i termini nel gruppo appropriato, ma ciò dovrebbe ridurre notevolmente gli sforzi manuali.
In R, puoi farlo usando adist()
Utilizzando i tuoi dati di esempio:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
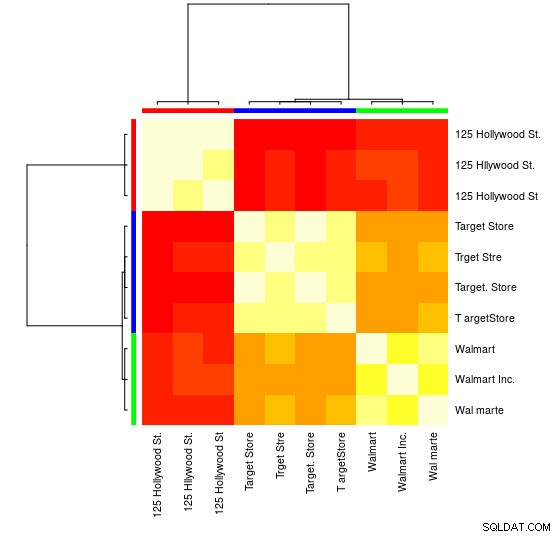
Per questo piccolo campione, puoi vedere i 3 gruppi distinti (i gruppi di valori di distanza di Levensthein bassi) e puoi facilmente assegnarli manualmente, ma per insiemi più grandi, probabilmente avrai bisogno di un algoritmo di raggruppamento.
Ti ho già indicato nei commenti uno dei miei risposta precedente
mostrando come farlo usando hclust() e il metodo della varianza minima di Ward, ma penso che qui faresti meglio a usare altre tecniche (una delle mie risorse preferite sull'argomento per una rapida panoramica di alcuni dei metodi più utilizzati in R è questo risposta dettagliata
)
Ecco un esempio che utilizza il clustering di propagazione di affinità:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Troverai nell'oggetto APResult d_ap gli elementi associati a ciascun cluster e il numero ottimale di cluster, in questo caso:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Puoi anche vedere una rappresentazione visiva:
> heatmap(d_ap, margins = c(10, 10))
Quindi, puoi eseguire ulteriori manipolazioni per ciascun gruppo. Ad esempio, qui uso hunspell per cercare ogni parola separata da Var1 in un dizionario en_US per errori di ortografia e prova a trovare, all'interno di ogni group , quale id non ha errori di ortografia (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Che dà:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Nota :Qui poiché non abbiamo eseguito alcuna elaborazione del testo, i risultati non sono molto conclusivi, ma ti fai un'idea.
Dati
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)